目前因项目需要,将检测模型与图像分类结合,完成项目。因此将CBAM模型代码进行整理,仅仅需要train.py与test.py,可分别对图像训练与分类,为了更好学习代码,本文内容分2块,其一将引用
他人博客,简单介绍原理;其二根据改写代码,介绍如何使用,训练自己模型及测试图片。论文:CBAM: Convolutional Block Attention Module
代码可参考:https://github.com/tangjunjun966/CBAM_PyTorch
一.基本原理
Convolutional Block Attention Module (CBAM) 表示卷积模块的注意力机制模块。是一种结合了空间(spatial)和通道(channel)的注意力机制模块。相比于senet只关注通道(channel)的注意力机制可以取得更好的效果。
基于传统VGG结构的CBAM模块。需要在每个卷积层后面加该模块。

基于shortcut结构的CBAM模块。例如resnet50,该模块在每个resnet的block后面加该模块。

Channel attention module:
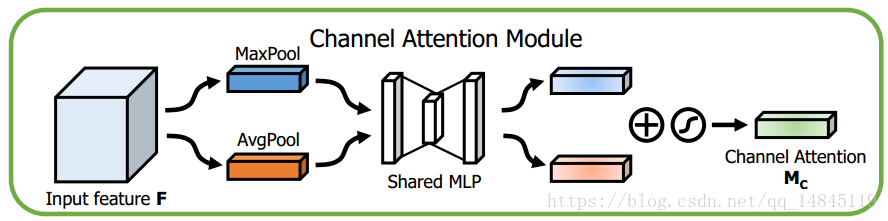
将输入的featuremap,分别经过基于width和height的global max pooling 和global average pooling,然后分别经过MLP。将MLP输出的特征进行基于elementwise的加和操作,再经过sigmoid激活操作,生成最终的channel attention featuremap。将该channel attention featuremap和input featuremap做elementwise乘法操作,生成Spatial attention模块需要的输入特征。

其中,seigema为sigmoid操作,r表示减少率,其中W0后面需要接RELU激活。
Spatial attention module:

将Channel attention模块输出的特征图作为本模块的输入特征图。首先做一个基于channel的global max pooling 和global average pooling,然后将这2个结果基于channel 做concat操作。然后经过一个卷积操作,降维为1个channel。再经过sigmoid生成spatial attention feature。最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。
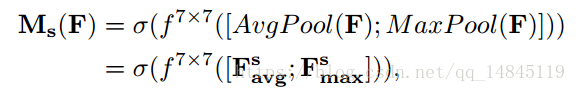
其中,seigema为sigmoid操作,7*7表示卷积核的大小,7*7的卷积核比3*3的卷积核效果更好。
二.代码使用
复制代码存放文件夹,其格式如下:

训练代码,已将整理成数据产生,模型产生等,可复制后修改args内参数,可直接调用。
训练代码如下:
from collections import OrderedDict import argparse import torch.optim as optim from torch.optim import lr_scheduler from torchvision import transforms, models, datasets from torchnet.meter import ClassErrorMeter, ConfusionMeter import torch.backends.cudnn as cudnn import torch.nn.functional as F import traceback import os import time import torch import torch.nn as nn import math import torch.utils.model_zoo as model_zoo import sys from PIL import Image import numpy as np def load_state_dict(model_dir, is_multi_gpu): state_dict = torch.load(model_dir, map_location=lambda storage, loc: storage)['state_dict'] if is_multi_gpu: new_state_dict = OrderedDict() for k, v in state_dict.items(): name = k[7:] # remove `module.` new_state_dict[name] = v return new_state_dict else: return state_dict def parse_parameters(): parser = argparse.ArgumentParser(description='PyTorch Template') parser.add_argument('--resume', default='', type=str, help='path to latest checkpoint (default: None)') # 基本不适用 parser.add_argument('--debug', action='store_true', dest='debug', help='trainer debug flag') # 不适用 parser.add_argument('--gpu', default='0', type=str, help='GPU ID Select') # 多gpu使用:'0,1,2' parser.add_argument('--data_root', default='./datasets/', type=str, help='data root') # datasets下面包含train与val文件夹,其中train与val文件夹内存放缺陷文件夹(缺陷图片)具体路径可看代码 parser.add_argument('--train_file', default='./datasets//train.txt', type=str, help='train file') parser.add_argument('--val_file', default='./datasets/val.txt', type=str, help='validation file') parser.add_argument('--model', default='resnet50_cbam', type=str, help='model type') parser.add_argument('--batch_size', default=4, type=int, help='model train batch size') parser.add_argument('--display', action='store_true', dest='display', help='Use TensorboardX to Display') parser.add_argument('--classes', default=2, type=int, help='Number of classes') parser.add_argument('--work_dir', default='./datasets/work_dir', type=str, help='work directory') parser.add_argument('--total_epochs', default=36, type=int, help='total epoch') args = parser.parse_args() return args class Logger(object): '''Save training process to log file with simple plot function.''' def __init__(self, fpath, resume=False): self.file = None self.resume = resume if os.path.isfile(fpath): if resume: self.file = open(fpath, 'a') else: self.file = open(fpath, 'w') else: self.file = open(fpath, 'w') def append(self, target_str): if not isinstance(target_str, str): try: target_str = str(target_str) except: traceback.print_exc() else: print(target_str) self.file.write(target_str + ' ') self.file.flush() else: print(target_str) self.file.write(target_str + ' ') self.file.flush() def close(self): if self.file is not None: self.file.close() class Concat_patch(object): """Resize the input PIL Image to the given size. Args: size (sequence or int): Desired output size. If size is a sequence like (h, w), output size will be matched to this. If size is an int, smaller edge of the image will be matched to this number. i.e, if height > width, then image will be rescaled to (size * height / width, size) interpolation (int, optional): Desired interpolation. Default is ``PIL.Image.BILINEAR`` """ def __init__(self, margin_ratio=(0.25, 0.25)): self.margin_ratio = margin_ratio def __call__(self, img): """ Args: img (PIL Image): Image to be scaled. Returns: PIL Image: Rescaled image. """ img = img array_img = np.array(img) h, w, c = array_img.shape h_margin = int(h * self.margin_ratio[0]) w_margin = int(w * self.margin_ratio[1]) patches = [array_img[0:h_margin, 0:w_margin, :], array_img[h - h_margin:, 0:w_margin, :], array_img[0:h_margin, w - w_margin:, :], array_img[h - h_margin:, w - w_margin:, :]] def concat_patches(patches): a = np.concatenate(patches[:2], axis=0) b = np.concatenate(patches[2:], axis=0) c = np.concatenate([a, b], axis=1) return c img = concat_patches(patches) img = Image.fromarray(img) return img def __repr__(self): interpolate_str = 'reconcat' return self.__class__.__name__ + '(size={0}, interpolation={1})'.format(self.size, interpolate_str) def build_dataset(args): gpus = args.gpu.split(',') data_transforms = { 'train': transforms.Compose([ Concat_patch(), transforms.Resize((224, 224)), # transforms.Resize((320, 320)), transforms.RandomHorizontalFlip(), transforms.RandomVerticalFlip(), # transforms.RandomRotation(90), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), 'val': transforms.Compose([ Concat_patch(), transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]) } train_datasets = datasets.ImageFolder(os.path.join(args.data_root, 'train'), data_transforms['train']) val_datasets = datasets.ImageFolder(os.path.join(args.data_root, 'val'), data_transforms['val']) # sampler = torch.utils.data.WeightedRandomSampler(weights=[1, 1], num_samples=len(train_datasets), replacement=True) train_dataloaders = torch.utils.data.DataLoader(train_datasets, batch_size=args.batch_size * len(gpus), shuffle=True, num_workers=4) val_dataloaders = torch.utils.data.DataLoader(val_datasets, batch_size=4, shuffle=False, num_workers=4) return train_dataloaders,val_dataloaders def build_model(args): if 'resnet50' == args.model: my_model = resnet50(pretrained=False, num_classes=args.classes) elif 'resnet50_cbam' == args.model: my_model = resnet50_cbam(pretrained=False, num_classes=args.classes) elif 'resnet101' == args.model: my_model = models.resnet101(pretrained=False, num_classes=args.classes) elif 'resnet18' == args.model: my_model = models.resnet18(pretrained=False, num_classes=args.classes) elif 'resnet18_cbam' == args.model: my_model = resnet18_cbam(pretrained=True, num_classes=args.classes) else: raise ModuleNotFoundError return my_model def build_optimezer(model): loss_fn = [nn.CrossEntropyLoss(weight=torch.Tensor([0.5, 5]).cuda())] # 不放到其它cuda上,是因为model输出结果在cuda0上处理 # loss_fn = [nn.CrossEntropyLoss()] optimizer = optim.SGD(model.parameters(), lr=0.02, momentum=0.9, weight_decay=1e-4) lr_schedule = lr_scheduler.MultiStepLR(optimizer, milestones=[16, 24, 32], gamma=0.1) # 按照epoch更新lr return loss_fn,optimizer,lr_schedule class Trainer(): def __init__(self, model, model_type, loss_fn, optimizer, lr_schedule, log_batchs, is_use_cuda, train_data_loader, valid_data_loader=None, metric=None, start_epoch=0, num_epochs=25, is_debug=False, logger=None, workdir='.'): self.model = model self.model_type = model_type self.loss_fn = loss_fn self.optimizer = optimizer self.lr_schedule = lr_schedule self.log_batchs = log_batchs self.is_use_cuda = is_use_cuda self.train_data_loader = train_data_loader self.valid_data_loader = valid_data_loader self.metric = metric self.start_epoch = start_epoch self.num_epochs = num_epochs self.is_debug = is_debug self.cur_epoch = start_epoch self.best_acc = 0. self.best_loss = sys.float_info.max self.logger = logger self.workdir = workdir def fit(self): for epoch in range(0, self.start_epoch): self.lr_schedule.step() for epoch in range(self.start_epoch, self.num_epochs): self.logger.append('Epoch {}/{}'.format(epoch, self.num_epochs - 1)) self.logger.append('-' * 60) self.cur_epoch = epoch self.lr_schedule.step() # 实际更新scheduler.last_epoch,且当该值到milestones,则改变学习率 if self.is_debug: self._dump_infos() self._train() self._valid() self._save_best_model() print() def _dump_infos(self): self.logger.append('---------------------Current Parameters---------------------') self.logger.append('is use GPU: ' + ('True' if self.is_use_cuda else 'False')) self.logger.append('lr: %f' % (self.lr_schedule.get_lr()[0])) self.logger.append('model_type: %s' % (self.model_type)) self.logger.append('current epoch: %d' % (self.cur_epoch)) self.logger.append('best accuracy: %f' % (self.best_acc)) self.logger.append('best loss: %f' % (self.best_loss)) self.logger.append('------------------------------------------------------------') def _train(self): self.model.train() # Set model to training mode losses = [] if self.metric is not None: self.metric[0].reset() # self.metric[1].reset() for i, (inputs, labels) in enumerate(self.train_data_loader): # Notice if self.is_use_cuda: inputs, labels = inputs.cuda(), labels.cuda() labels = labels.squeeze() else: labels = labels.squeeze() self.optimizer.zero_grad() # 清理梯度 outputs = self.model(inputs) # Notice loss = self.loss_fn[0](outputs, labels) if self.metric is not None: prob = F.softmax(outputs, dim=1).data.cpu() self.metric[0].add(prob, labels.data.cpu()) #one_hot = torch.zeros(prob.shape[0], prob.shape[1]).scatter_(1, labels.cpu(), 1) # self.metric[1].add(prob, labels.data.cpu()) loss.backward() self.optimizer.step() losses.append(loss.item()) # Notice if 0 == i % self.log_batchs or (i == len(self.train_data_loader) - 1): local_time_str = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())) batch_mean_loss = np.mean(losses) print_str = '[%s] Training Batch[%d/%d] Class Loss: %.4f ' % (local_time_str, i, len(self.train_data_loader) - 1, batch_mean_loss) if i == len(self.train_data_loader) - 1 and self.metric is not None: confusion = self.metric[0].value() print(confusion) # top1_acc_score = self.metric[0].value()[0] # top3_acc_score = self.metric[0].value()[1] # print_str += '@Top-1 Score: %.4f ' % (top1_acc_score) # print_str += '@Top-3 Score: %.4f ' % (top3_acc_score) # print(self.metric[1].value()) self.logger.append(print_str) def _valid(self): self.model.eval() losses = [] acc_rate = 0. if self.metric is not None: self.metric[0].reset() with torch.no_grad(): # Notice for i, (inputs, labels) in enumerate(self.valid_data_loader): if self.is_use_cuda: inputs, labels = inputs.cuda(), labels.cuda() labels = labels.squeeze() else: labels = labels.squeeze() if len(labels.shape) == 0: labels = labels.view(-1) outputs = self.model(inputs) # Notice loss = self.loss_fn[0](outputs, labels) if self.metric is not None: prob = F.softmax(outputs, dim=1).data.cpu() self.metric[0].add(prob, labels.data.cpu()) losses.append(loss.item()) local_time_str = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())) # self.logger.append(losses) batch_mean_loss = np.mean(losses) print_str = '[%s] Validation: Class Loss: %.4f ' % (local_time_str, batch_mean_loss) if self.metric is not None: confusion = self.metric[0].value() print(confusion) # top1_acc_score = self.metric[0].value()[0] # top3_acc_score = self.metric[0].value()[1] # print_str += '@Top-1 Score: %.4f ' % (top1_acc_score) # print_str += '@Top-3 Score: %.4f ' % (top3_acc_score) self.logger.append(print_str) # if top1_acc_score >= self.best_acc: # self.best_acc = top1_acc_score # self.best_loss = batch_mean_loss def _save_best_model(self): # Save Model self.logger.append('Saving Model...') state = { 'state_dict': self.model.state_dict(), 'best_acc': self.best_acc, 'cur_epoch': self.cur_epoch, 'num_epochs': self.num_epochs } if not os.path.isdir(os.path.join(self.workdir, 'checkpoint/') + self.model_type): os.makedirs(os.path.join(self.workdir, 'checkpoint/') + self.model_type) torch.save(state, os.path.join(self.workdir, 'checkpoint/') + self.model_type + '/Models' + '_epoch_%d' % self.cur_epoch + '.ckpt') # Notice # 构建网络 model_urls = { 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth', 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth', 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth', 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth', 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth', } def conv3x3(in_planes, out_planes, stride=1): "3x3 convolution with padding" return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False) class ChannelAttention(nn.Module): def __init__(self, in_planes, ratio=16): super(ChannelAttention, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) self.max_pool = nn.AdaptiveMaxPool2d(1) self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False) self.relu1 = nn.ReLU() self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x)))) max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x)))) out = avg_out + max_out return self.sigmoid(out) class SpatialAttention(nn.Module): def __init__(self, kernel_size=7): super(SpatialAttention, self).__init__() assert kernel_size in (3, 7), 'kernel size must be 3 or 7' padding = 3 if kernel_size == 7 else 1 self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): avg_out = torch.mean(x, dim=1, keepdim=True) max_out, _ = torch.max(x, dim=1, keepdim=True) # _索引,维度不变 x = torch.cat([avg_out, max_out], dim=1) x = self.conv1(x) return self.sigmoid(x) class BasicBlock(nn.Module): expansion = 1 def __init__(self, inplanes, planes, stride=1, downsample=None): super(BasicBlock, self).__init__() self.conv1 = conv3x3(inplanes, planes, stride) self.bn1 = nn.BatchNorm2d(planes) self.relu = nn.ReLU(inplace=True) self.conv2 = conv3x3(planes, planes) self.bn2 = nn.BatchNorm2d(planes) self.ca = ChannelAttention(planes) self.sa = SpatialAttention() self.downsample = downsample self.stride = stride def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.ca(out) * out out = self.sa(out) * out if self.downsample is not None: residual = self.downsample(x) out += residual out = self.relu(out) return out class Bottleneck_CBAM(nn.Module): expansion = 4 def __init__(self, inplanes, planes, stride=1, downsample=None): super(Bottleneck_CBAM, self).__init__() self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False) self.bn3 = nn.BatchNorm2d(planes * 4) self.relu = nn.ReLU(inplace=True) self.ca = ChannelAttention(planes * 4) self.sa = SpatialAttention() self.downsample = downsample self.stride = stride def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) out = self.ca(out) * out out = self.sa(out) * out if self.downsample is not None: residual = self.downsample(x) out += residual out = self.relu(out) return out class Bottleneck(nn.Module): expansion = 4 def __init__(self, inplanes, planes, stride=1, downsample=None): super(Bottleneck, self).__init__() self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False) self.bn3 = nn.BatchNorm2d(planes * 4) self.relu = nn.ReLU(inplace=True) # self.ca = ChannelAttention(planes * 4) # self.sa = SpatialAttention() self.downsample = downsample self.stride = stride def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) # out = self.ca(out) * out # out = self.sa(out) * out if self.downsample is not None: residual = self.downsample(x) out += residual out = self.relu(out) return out class ResNet(nn.Module): def __init__(self, block, layers, num_classes=23): self.inplanes = 64 super(ResNet, self).__init__() self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(64) self.relu = nn.ReLU(inplace=True) self.layer1 = self._make_layer(block, 64, layers[0], stride=2) self.layer2 = self._make_layer(block, 128, layers[1], stride=2) self.layer3 = self._make_layer(block, 256, layers[2], stride=2) self.layer4 = self._make_layer(block, 512, layers[3], stride=2) self.avgpool = nn.AvgPool2d(7, stride=1) self.fc = nn.Linear(512 * block.expansion, num_classes) for m in self.modules(): if isinstance(m, nn.Conv2d): n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels m.weight.data.normal_(0, math.sqrt(2. / n)) elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(1) m.bias.data.zero_() def _make_layer(self, block, planes, blocks, stride=1): downsample = None if stride != 1 or self.inplanes != planes * block.expansion: downsample = nn.Sequential( nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(planes * block.expansion), ) layers = [] layers.append(block(self.inplanes, planes, stride, downsample)) self.inplanes = planes * block.expansion for i in range(1, blocks): layers.append(block(self.inplanes, planes)) return nn.Sequential(*layers) def forward(self, x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.avgpool(x) x = x.view(x.size(0), -1) x = self.fc(x) return x def resnet18_cbam(pretrained=False, **kwargs): """Constructs a ResNet-18 model. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs) if pretrained: pretrained_state_dict = model_zoo.load_url(model_urls['resnet18']) now_state_dict = model.state_dict() now_state_dict.update(pretrained_state_dict) now_state_dict.pop('fc.weight') now_state_dict.pop('fc.bias') model.load_state_dict(now_state_dict, strict=False) return model def resnet34_cbam(pretrained=False, **kwargs): """Constructs a ResNet-34 model. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs) if pretrained: pretrained_state_dict = model_zoo.load_url(model_urls['resnet34']) now_state_dict = model.state_dict() now_state_dict.update(pretrained_state_dict) model.load_state_dict(now_state_dict) return model def resnet50_cbam(pretrained=False, **kwargs): """Constructs a ResNet-50 model. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ model = ResNet(Bottleneck_CBAM, [3, 4, 6, 3], **kwargs) if pretrained: pretrained_state_dict = model_zoo.load_url(model_urls['resnet50']) now_state_dict = model.state_dict() now_state_dict.update(pretrained_state_dict) model.load_state_dict(now_state_dict) return model def resnet50(pretrained=False, **kwargs): """Constructs a ResNet-50 model. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs) if pretrained: pretrained_state_dict = model_zoo.load_url(model_urls['resnet50']) now_state_dict = model.state_dict() now_state_dict.update(pretrained_state_dict) model.load_state_dict(now_state_dict) return model def resnet101_cbam(pretrained=False, **kwargs): """Constructs a ResNet-101 model. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ model = ResNet(Bottleneck_CBAM, [3, 4, 23, 3], **kwargs) if pretrained: pretrained_state_dict = model_zoo.load_url(model_urls['resnet101']) now_state_dict = model.state_dict() now_state_dict.update(pretrained_state_dict) model.load_state_dict(now_state_dict) return model def resnet152_cbam(pretrained=False, **kwargs): """Constructs a ResNet-152 model. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """ model = ResNet(Bottleneck_CBAM, [3, 8, 36, 3], **kwargs) if pretrained: pretrained_state_dict = model_zoo.load_url(model_urls['resnet152']) now_state_dict = model.state_dict() now_state_dict.update(pretrained_state_dict) model.load_state_dict(now_state_dict) return model def train(): args=parse_parameters() logger = Logger('./' + args.model + '.log') if len(args.resume)==0 else Logger('./' + args.model + '.log', True) logger.append(vars(args)) os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu is_use_cuda = torch.cuda.is_available() cudnn.benchmark = True train_dataloaders, val_dataloaders = build_dataset(args) model=build_model(args) loss_fn, optimizer, lr_schedule = build_optimezer(model) if is_use_cuda and 1 == len(args.gpu.split(',')): model = model.cuda() elif is_use_cuda and 1 < len(args.gpu.split(',')): model = nn.DataParallel(model.cuda()) # 将模型my_model.cuda() 缓存放在cuda 0 上 metric = [ConfusionMeter(2)] start_epoch = 0 my_trainer = Trainer(model, args.model, loss_fn, optimizer, lr_schedule, 10, is_use_cuda, train_dataloaders, val_dataloaders, metric, start_epoch, args.total_epochs, args.debug, logger, args.work_dir) my_trainer.fit() logger.append('Optimize Done!') if __name__ == '__main__': train()
测试代码调用模型依附训练代码,因此需要有训练代码与测试代码同文件,方可调用。
测试代码如下:
from collections import OrderedDict from PIL import Image import torch import torch.nn.functional as F from torch.autograd import Variable from torchvision import transforms import numpy as np from train_new import resnet50_cbam def init_cls_model(checkpoint_path, is_multi_gpu=False, classes=2): my_model = resnet50_cbam(num_classes=classes) state_dict = torch.load(checkpoint_path)['state_dict'] if is_multi_gpu: new_state_dict = OrderedDict() for k, v in state_dict.items(): name = k[7:] # remove `module.` new_state_dict[name] = v my_model.load_state_dict(new_state_dict) else: my_model.load_state_dict(state_dict) my_model = my_model.cuda() my_model.eval() return my_model class Concat_patch(object): # 切图,实际可以不用 """Resize the input PIL Image to the given size. Args: size (sequence or int): Desired output size. If size is a sequence like (h, w), output size will be matched to this. If size is an int, smaller edge of the image will be matched to this number. i.e, if height > width, then image will be rescaled to (size * height / width, size) interpolation (int, optional): Desired interpolation. Default is ``PIL.Image.BILINEAR`` """ def __init__(self, margin_ratio=(0.25, 0.25)): self.margin_ratio = margin_ratio def __call__(self, img): """ Args: img (PIL Image): Image to be scaled. Returns: PIL Image: Rescaled image. """ img = img array_img = np.array(img) h, w, c = array_img.shape h_margin = int(h * self.margin_ratio[0]) w_margin = int(w * self.margin_ratio[1]) patches = [array_img[0:h_margin, 0:w_margin, :], array_img[h - h_margin:, 0:w_margin, :], array_img[0:h_margin, w - w_margin:, :], array_img[h - h_margin:, w - w_margin:, :]] def concat_patches(patches): a = np.concatenate(patches[:2], axis=0) b = np.concatenate(patches[2:], axis=0) c = np.concatenate([a, b], axis=1) return c img = concat_patches(patches) img = Image.fromarray(img) return img def __repr__(self): interpolate_str = 'reconcat' return self.__class__.__name__ + '(size={0}, interpolation={1})'.format(self.size, interpolate_str) def cls_judge(img_path, model, img_size=224): FALSE_NAME = 'FALSE' NG_NAME = 'NG' CLS_NAME = [FALSE_NAME, NG_NAME] data_transform = transforms.Compose([ Concat_patch(), transforms.Resize((img_size, img_size)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]) file_path = img_path with torch.no_grad(): img_tensor = data_transform(Image.open(file_path).convert('RGB')).unsqueeze(0) img_tensor = Variable(img_tensor.cuda(), volatile=True) output = F.softmax(model(img_tensor), dim=1).cpu().numpy() # defect_prob = round(output.data[0, 1], 6) pred = np.argmax(output) pred = CLS_NAME[pred] score = np.max(output) if pred == FALSE_NAME: score = 0 if score <= 0.85 and pred == NG_NAME: pred = FALSE_NAME score = 0 return pred, score if __name__ == '__main__': model_path=r'E:code_tjCBAM_PyTorchdatasetswork_dircheckpoint esnet50-cbamModels_epoch_0.ckpt' img=r'E:code_tjCBAM_PyTorchdatasetsvalv06W0C2P0206A0108_WHITE_20210125.jpg' model=init_cls_model(model_path, is_multi_gpu=False, classes=2) pre=cls_judge(img, model, img_size=224) print(pre)
参考博客:https://blog.csdn.net/qq_14845119/article/details/81393127