本次将整理一份map计算方法,主要分为2部分,第一部分介绍map原理,主要引用部分他人结果,第二部分说明如何整理真实标签的数据及预测数据,调用pycocotools库实现map的计算,以下便是本博客的整理(附带转换coco json代码):
一.map原理:
定义内容均来自此网址:https://zhuanlan.zhihu.com/p/70667071
Accuracy:准确率
✔️ 准确率=预测正确的样本数/所有样本数,即预测正确的样本比例(包括预测正确的正样本和预测正确的负样本,不过在目标检测领域,没有预测正确的负样本这一说法,所以目标检测里面没有用Accuracy的)。
Precision:查准率
✔️ recision表示某一类样本预测有多准。
✔️ Precision针对的是某一类样本,如果没有说明类别,那么Precision是毫无意义的(有些地方不说明类别,直接说Precision,是因为二分类问题通常说的Precision都是正样本的Precision)。
Recall:召回率
✔️ Recall和Precision一样,脱离类别是没有意义的。说道Recall,一定指的是某个类别的Recall。Recall表示某一类样本,预测正确的与所有Ground Truth的比例。
✍️ Recall计算的时候,分母是Ground Truth中某一类样本的数量,而Precision计算的时候,是预测出来的某一类样本数。
F1 Score:平衡F分数
F1分数,它被定义为查准率和召回率的调和平均数
更加广泛的会定义 分数,其中
和
分数在统计学在常用,并且,
分数中,召回率的权重大于查准率,而
分数中,则相反。
AP: Average Precision
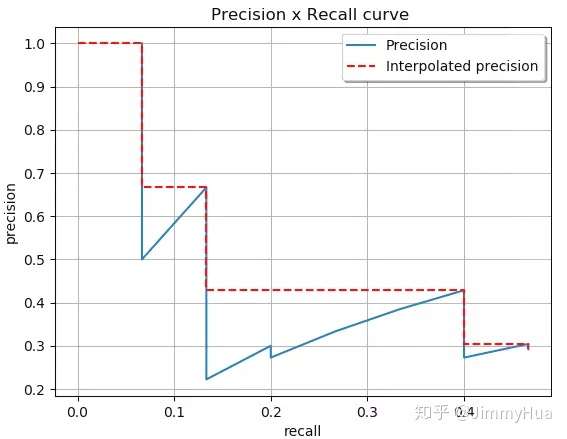
以Recall为横轴,Precision为纵轴,就可以画出一条PR曲线,PR曲线下的面积就定义为AP,即:
 PR曲线
PR曲线
由于计算积分相对困难,因此引入插值法,计算AP公式如下:
计算面积:

原理:
二.代码:
本部分才是本博客重要内容,我将介绍2部分,第一部分如何使用有标记的真实数据产生coco json格式与如何使用模型预测结果产生预测json格式,第二部分如何使用代码计算map。
①.json格式
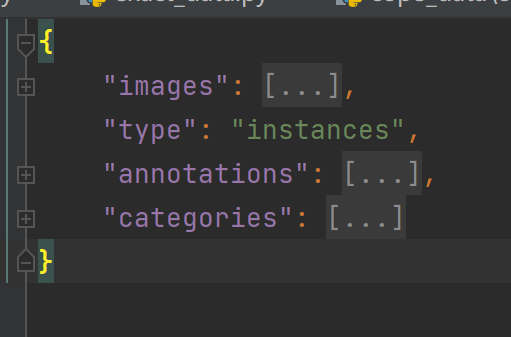
真实数据json格式实际是coco json 格式,主要是如下图:
其中images格式如下图:

annotations格式如下:
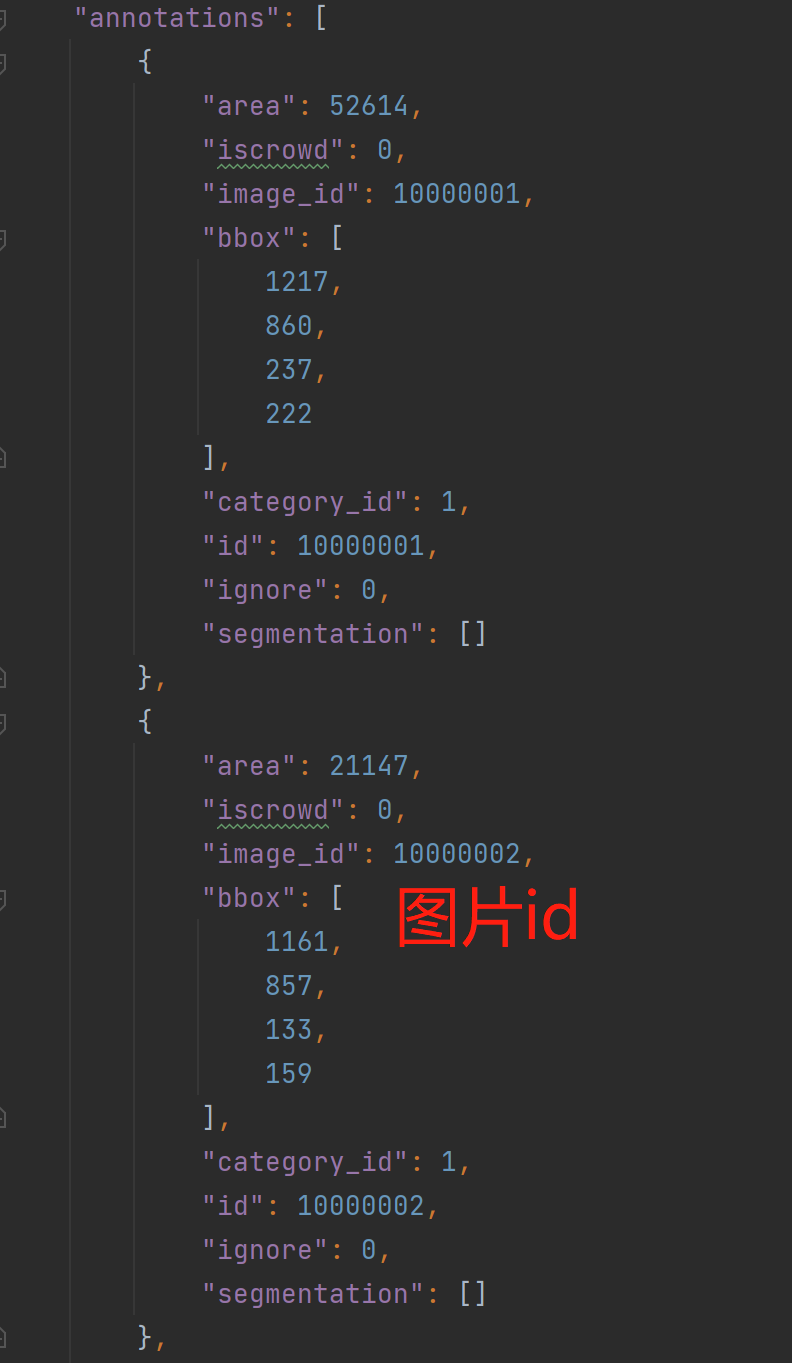
categories格式为:
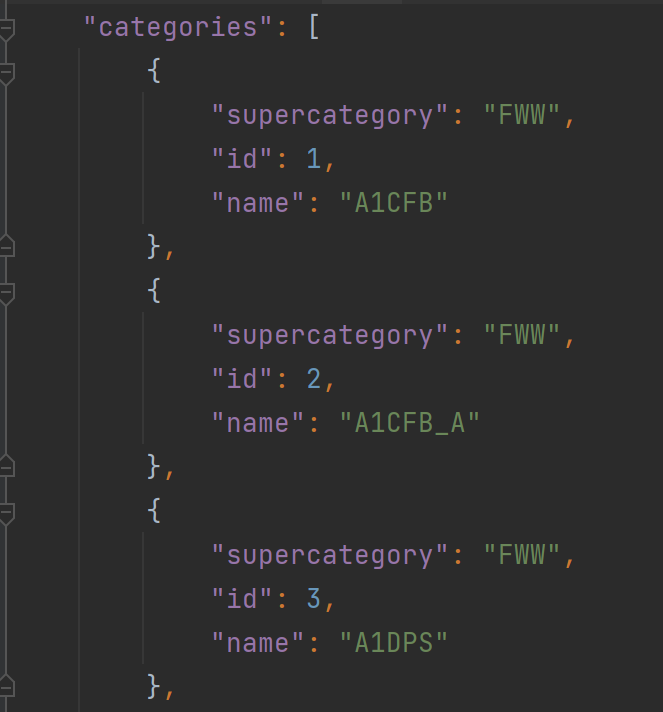
以上为真实数据转换为json的格式。
预测结果数据json格式转换,主要是如下图:
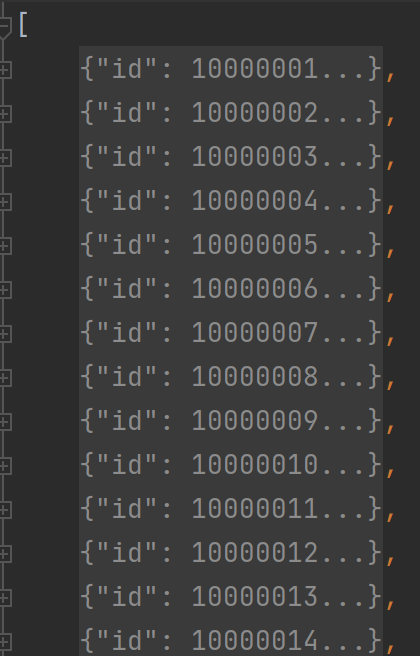
以上右图是整体结构,实际为列表,左图是预测信息,保存为字典,其详细内容如下:

特别注意:image id 对应真实coco json图像的image-id,类别id也是对应真实coco json中的类别id。
②.实际代码,借助pycocotools 库中评估类别,具体代码如下图:
1 from pycocotools.coco import COCO 2 from pycocotools.cocoeval import COCOeval 3 4 if __name__ == "__main__": 5 cocoGt = COCO('coco_json_format.json') #标注文件的路径及文件名,json文件形式 6 cocoDt = cocoGt.loadRes('predect_format.json') #自己的生成的结果的路径及文件名,json文件形式 7 cocoEval = COCOeval(cocoGt, cocoDt, "bbox") 8 cocoEval.evaluate() 9 cocoEval.accumulate() 10 cocoEval.summarize()
③结果展示:
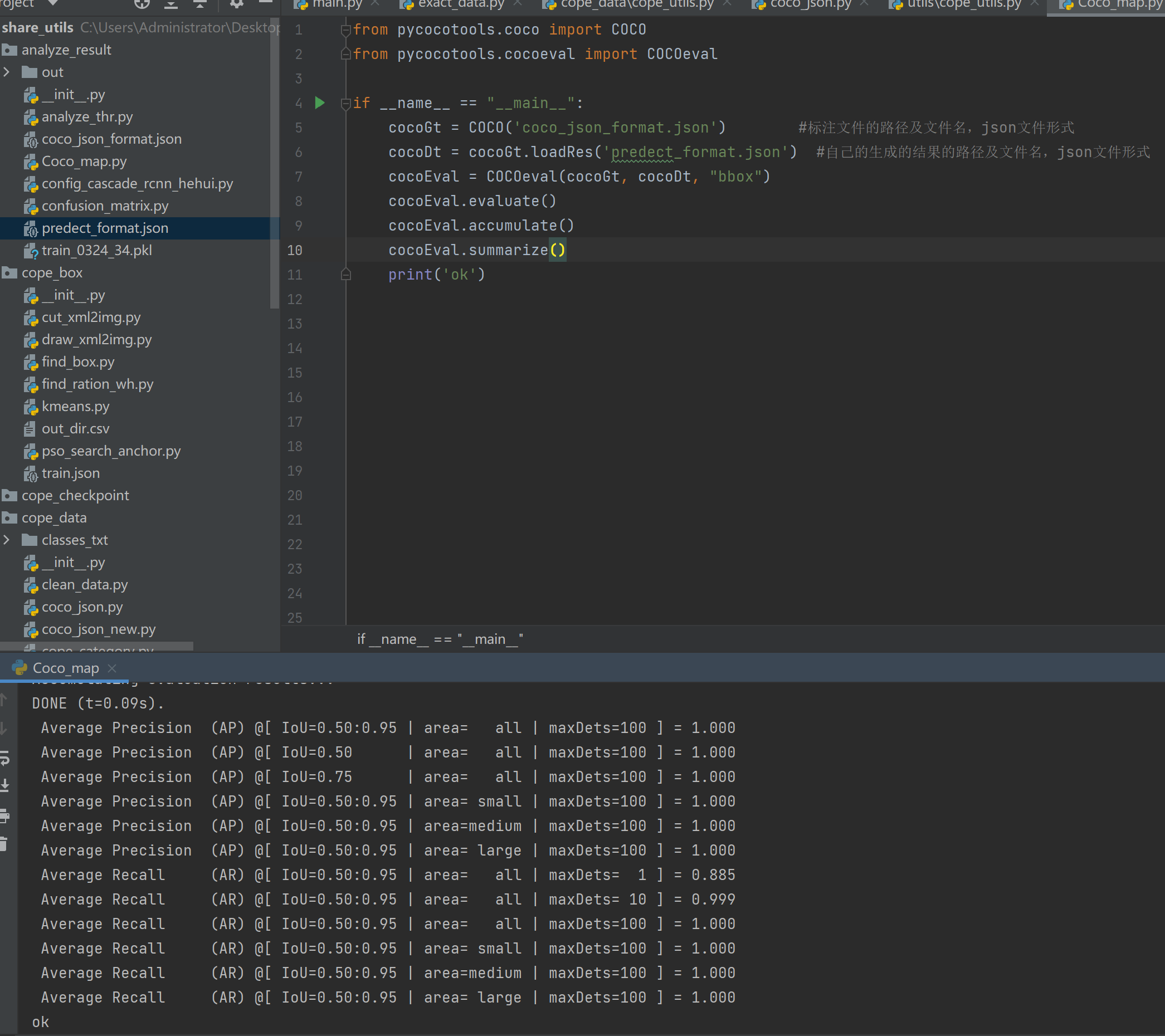
附带xml转换coco json代码:
1 import os 2 import json 3 import xml.etree.ElementTree as ET 4 import cv2 # 无xml时候需要读取图片高与宽 5 # from cope_data.cope_utils import * 6 from tqdm import tqdm 7 8 9 10 11 12 13 14 15 def read_xml(xml_root): 16 ''' 17 :param xml_root: .xml文件 18 :return: dict('cat':['cat1',...],'bboxes':[[x1,y1,x2,y2],...],'whd':[w ,h,d]) 19 ''' 20 dict_info = {'cat': [], 'bboxes': [], 'box_wh': [], 'whd': []} 21 if os.path.splitext(xml_root)[-1] == '.xml': 22 tree = ET.parse(xml_root) # ET是一个xml文件解析库,ET.parse()打开xml文件。parse--"解析" 23 root = tree.getroot() # 获取根节点 24 whd = root.find('size') 25 whd = [int(whd.find('width').text), int(whd.find('height').text), int(whd.find('depth').text)] 26 xml_filename = root.find('filename').text 27 dict_info['whd']=whd 28 dict_info['xml_filename']=xml_filename 29 for obj in root.findall('object'): # 找到根节点下所有“object”节点 30 cat = str(obj.find('name').text) # 找到object节点下name子节点的值(字符串) 31 bbox = obj.find('bndbox') 32 x1, y1, x2, y2 = [int(bbox.find('xmin').text), 33 int(bbox.find('ymin').text), 34 int(bbox.find('xmax').text), 35 int(bbox.find('ymax').text)] 36 b_w = x2 - x1 + 1 37 b_h = y2 - y1 + 1 38 39 dict_info['cat'].append(cat) 40 dict_info['bboxes'].append([x1, y1, x2, y2]) 41 dict_info['box_wh'].append([b_w, b_h]) 42 43 else: 44 print('[inexistence]:{} suffix is not xml '.format(xml_root)) 45 return dict_info 46 47 48 49 50 51 52 53 # xml转换为训练集 54 def train_multifiles(root_data, json_name='train.json', categories=None, out_dir=None, add_file=False,refuse_category=[],category_path=None): 55 ''' 56 json文件中的file_name包含文件夹/名字 57 :param json_name: 保存json文件名字,最终结果在out_dir+json_name(若out_dir有路径情况),否则在root_data下面 58 :param categories: 类别信息,为None则将self.root文件夹的名字作为类别信息 59 add_file :True表示cocojson中添加文件名,否则不添加 60 refuse_category:拒绝装换为cocojson的类的列表 61 :return: 62 ''' 63 64 65 66 def read_txt(file_path): 67 with open(file_path, 'r') as f: 68 content = f.read().splitlines() 69 return content 70 def write_txt(text_lst, out_dir): 71 ''' 72 每行内容为列表,将其写入text中 73 ''' 74 file_write_obj = open(out_dir, 'w') # 以写的方式打开文件,如果文件不存在,就会自动创建 75 for text in text_lst: 76 file_write_obj.writelines(text) 77 file_write_obj.write('\n') 78 file_write_obj.close() 79 return out_dir 80 81 def get_strfile(file_str, pos=-1): 82 ''' 83 得到file_str / or \\ 的最后一个名称 84 ''' 85 endstr_f_filestr = file_str.split('\\')[pos] if '\\' in file_str else file_str.split('/')[pos] 86 return endstr_f_filestr 87 88 # coco json文件格式 89 json_dict = {"images": [], "type": "instances", "annotations": [], "categories": []} 90 image_id = 10000000 91 anation_id = 10000000 92 xml_root_lst = [] 93 for dir, dir_file, dir_names in os.walk(root_data): 94 name_lst = [os.path.join(dir, name) for name in dir_names if name[-3:] == 'xml'] 95 xml_root_lst = xml_root_lst + name_lst 96 if category_path is None: 97 if categories is None: 98 categories = [] 99 elif isinstance(categories, list): 100 categories = categories 101 else: 102 raise IOError('categories must be list or None') 103 else: 104 categories=read_txt(category_path) 105 106 107 count_categories = {} 108 for xml_root in tqdm(xml_root_lst): 109 try: 110 xml_info=read_xml(xml_root) 111 if len(xml_info['cat'])>0: 112 xml_filename = xml_info['xml_filename'] 113 xml_name = get_strfile(xml_root) 114 img_name = xml_name[:-3] + xml_filename[-3:] 115 # 转为cocojson时候,若add_file为True则在cocojson文件的file_name增加文件夹名称+图片名字 116 file_name = get_strfile(xml_root, pos=-2) + '/' + img_name if add_file else img_name # 只记录图片名字 117 118 image_id = image_id + 1 119 120 w,h,d=xml_info['whd'] 121 # 构建json文件字典 122 image = {'file_name': file_name, 'height': h, 'width': w, 'id': image_id} 123 for i, category in enumerate(xml_info['cat']): 124 125 if category in refuse_category: 126 print('refuse {} code will not convert coojson format '.format(category)) 127 continue 128 # 若categories列表不包含该code则增加该code到列表中 129 if category not in categories and category_path is None: 130 categories.append(category) 131 # 计数每个cat的数量 132 count_categories[category]=1 if category not in count_categories else count_categories[category]+1 133 134 135 # 表示有box存在,可以添加images信息 136 if image not in json_dict['images']: 137 json_dict['images'].append(image) # 将图像信息添加到json中 138 category_id = categories.index(category) + 1 # 给出box对应标签索引为类 139 anation_id = anation_id + 1 140 xmin,ymin,xmax,ymax=xml_info['bboxes'][i] 141 142 o_width,o_height=xml_info['box_wh'][i] 143 144 if (xmax <= xmin) or (ymax <= ymin): 145 print('code:[{}] will be abandon due to {} min of box w or h more than max '.format(category,xml_root)) # 打印错误的box 146 147 else: 148 ann = {'area': o_width * o_height, 'iscrowd': 0, 'image_id': image_id, 149 'bbox': [xmin, ymin, o_width, o_height], 150 'category_id': category_id, 'id': anation_id, 'ignore': 0, 151 'segmentation': []} 152 json_dict['annotations'].append(ann) 153 except: 154 print('xml file: {} not read error!'.format(xml_root)) 155 156 157 for cid, cate in enumerate(categories): 158 cat = {'supercategory': cate, 'id': cid + 1, 'name': cate} 159 json_dict['categories'].append(cat) 160 if out_dir is not None: 161 build_dir(self.out_dir) 162 out_dir = os.path.join(out_dir, json_name) 163 out_dir_txt=os.path.join(out_dir, 'classes.txt') 164 else: 165 out_dir = os.path.join(root_data, json_name) 166 out_dir_txt = os.path.join(root_data, 'classes.txt') 167 with open(out_dir, 'w') as f: 168 json.dump(json_dict, f, indent=4) # indent表示间隔长度 169 170 write_txt(categories,out_dir_txt) 171 172 173 print('categories count : \n',count_categories) 174 175 176 177 178 if __name__ == '__main__': 179 root_path = r'D:\DATA\coco2017_train_val\data_coco_clear_2017\val' 180 category_path=r'D:\DATA\coco2017_train_val\data_coco_clear_2017\classes.txt' 181 train_multifiles(root_path,category_path=category_path)
借鉴博客:https://blog.csdn.net/qq_35916487/article/details/89076570