导语
这篇博客是在看慕课时写的,由于我的环境为
TF2.3,在看慕课里TF1.*的代码的时候,运行起来就会出现种种问题,而我呢又不想直接去看TF2的内容,就一个个解决,记录下来,慕课链接放在下面,当然这篇博客会以TF2为主,毕竟主要还是用TF2的嘛,当然不一定完全哈。这一个板块的所有博客应该都会这样,就看我后面有没有时间继续写了。
慕课:《深度学习应用开发-TensorFlow实践》
章节:第四讲 磨刀不误砍柴工:TensorFlow 编程基础
Tensorflow基本概念
一些导学啊、TF概念啊啥的就直接跳过了,想看的直接去慕课
还是先从HelloWorld讲起
没错,小小hello world也会出点问题,先来看TF1中的代码
import tensorflow as tf
# 创建一个常量运算,将作为一个节点加入到默认计算图中
hello = tf.constant("hello,hello")
# 创建一个TF会话
sess=tf.Session()
# 运行并获得结果
print(sess.run(hello))
这段代码在TF1里毫无问题,放在TF2中,一运行,嘿嘿
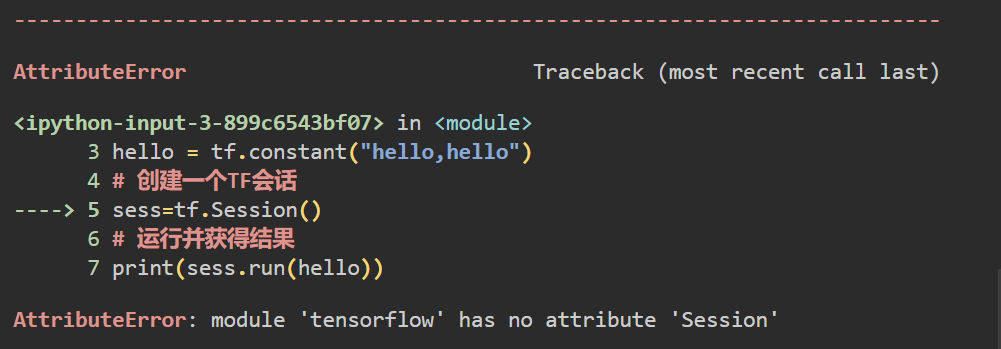
这是啥原因的,原来啊是TF2中把tf.Session()给删了,当然这个好解决的把import tensorflow as tf改成import tensorflow.compat.v1 as tf就好了,这样的话他就会兼容TF1运行
但是,你改完后,还会发现他又又又报错了
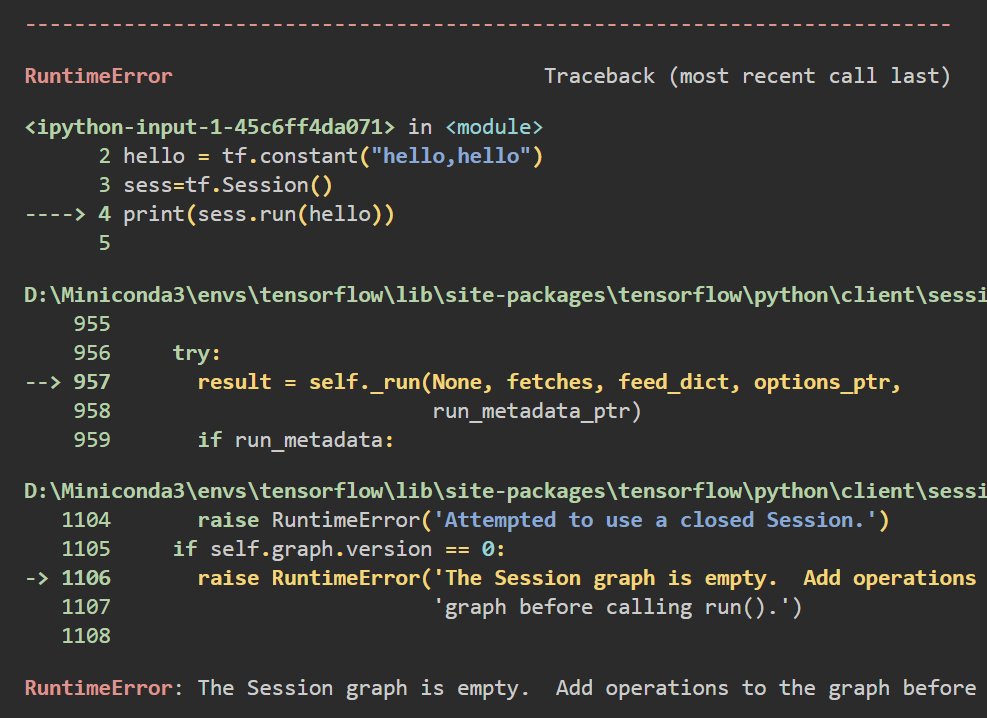
这次报错在了print(sess.run(hello)),ERROR为The Session graph is empty. Add operations to the graph before calling run().,翻译一下就是Session图为空。在调用run()之前向图添加操作,呃,还是Tensorflow版本的问题,加一句tf.compat.v1.disable_eager_execution()就好了,下面是全部可运行代码
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()#保证sess.run()能够正常运行
# 创建一个常量运算,将作为一个节点加入到默认计算图中
hello = tf.constant("hello,hello")
# 创建一个TF会话
sess=tf.Session()
# 运行并获得结果
print(sess.run(hello))
输出
b'hello,hello'
这里前面的b表示字节文字,具体可以看我之前写的一篇博客
事实上,当你写完下面这样一段内容以后,你接下来的操作就和TF1几乎一毛一样了
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()#保证sess.run()能够正常运行
TensorFlow的计算模型——计算图
计算图是一个有向图,它包含以下的几个部分:
- 一组节点,每个节点都代表一个操作,是一种运算
- 一组有向边,每条边代表节点之间的关系(数据传递和控制依赖)
TensorFlow有两种边:
- 常规边(实线):代表数据依赖关系。一个节点的运算输出成另一个节点的输入,两个节点之间有tensor流动
- 特殊边(虚线):不携带值,表示两个节点之间的控制相关性
计算实例(这里的导入是import tensorflow.compat.v1 as tf,同时进行了tf.compat.v1.disable_eager_execution(),之后如果没讲,在跑TF1代码的时候默认写了这俩)
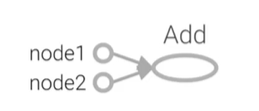
node1=tf.constant(3.0,tf.float32,name="node1")
node2=tf.constant(4.0,tf.float32,name="node2")
node3=tf.add(node1,node2)
print(node3)
输出
Tensor("Add:0", shape=(), dtype=float32)
这里的node3是一个张量结构,不是数字,他在内部会生成这样的一张图
输出组成是tensor(名称,形状,元素类型),如果输出node1也是类似的
Tensor("node1_1:0", shape=(), dtype=float32)
由于TF1它是静态的,所以上面其实并没有执行,也就是说并没有进行加这样的一个具体数值的操作,想要去执行它,就需要去建立会话,然后执行对话
sess=tf.Session()
print(f"node1结果:{sess.run(node1)}")
print(f"node3结果:{sess.run(node3)}")
sess.close()# 关闭session
输出:
node1结果:3.0
node3结果:7.0
这一块如果是TF2的话,那就不需要后面创建对话那一段了,直接就运行好了
node1=tf.constant(3.0,tf.float32,name="node1")
node2=tf.constant(4.0,tf.float32,name="node2")
node3=tf.add(node1,node2)
print(node3)
输出
tf.Tensor(7.0, shape=(), dtype=float32)
事实上,两者在这一阶段的差别也就是TF1需要创建一个对话然后去运行它,而TF2由于是动态的,因此就不再需要创建。
在这里我们可以看到,如果我们直接去print(node3),他输出的是一个tensor类型,那如果我只要其中的值,该怎么操作呢?这里我们可以调用numpy()方法
node1=tf.constant([3.0],tf.float32,name="node1")
node2=tf.constant([4.0],tf.float32,name="node2")
node3=tf.add(node1,node2)
print(node3)
print(node3.numpy())
输出
tf.Tensor([7.], shape=(1,), dtype=float32)
[7.]
这样的话,输出结果就会使其中numpy的内容了,当然也可以通过其他的参数名去输出对应的参数值
print(node3.shape)
print(node3.dtype)
输出
(1,)
<dtype: 'float32'>
接下来的代码,我就直接贴TF1和TF2了,不再作解释,其实基本上也没有啥其他区别(我说的只是这一块哈)
张量
在TensorFlow中,所有数据都通过张量的形式来表示。
从功能的角度,张量可以简单理解为多维数组
- 零阶张量表示标量,也就是一个数
- 一阶张量为向量,也就是一维数组
- n阶张量可以理解为一个n维数组
张量并没有保存真正的数字,他保存的是计算过程。
当然,在TF2中,由于其热运行的特性,在计算的时候直接就得到了结果
张量的属性
在这一点上,TF1和TF2还是有一定的区别的。
先来看TF2叭
<tf.Tensor: shape=(1, 2), dtype=float32, numpy=array([[7., 9.]], dtype=float32)>
- 标识号(id):系统自动维护的唯一值。在TF2.0中,输出
tensor,第一个参数就是id,但我不知道为什么在2.3中就不打印id了,有知道的可以告诉我一下。 - 形状(shape):张量的维度信息,可以通过
tensor.shape获取,比如例子中的变量node3.shape,注意没有括号! - 类型(dtype):每个张量都会有一个唯一的类型,TensorFlow会对参与运算的所有张量进行类型的检查,发现类型不匹配时会报错,可以通过
tensor.dtype获取,比如例子中的变量node3.dtype - 值(value):通过
numpy(),返回Numpy.array类型的数据,比如例子中的变量node3.numpy()
张量的形状
三个术语描述张量的维度:阶、形状、维数
| 阶 | 形状 | 维数 | 例子 |
|---|---|---|---|
| 0 | () | 0-D | 4 |
| 1 | (D0) | 1-D | [2,3,4] |
| 2 | (D0,D1) | 2-D | [[2,3],[3,4]] |
| 3 | (D0,D1,D2) | 3-D | [[[2],[3]],[[3],[4]]] |
| N | (D0,D1,...,Dn-1) | n-D | 形为(D0,D1,...,Dn-1)的张量 |
| 表格中的D0表示第0维元素个数,Di表示Di维元素的个数。这里看维度有个技巧,你看最左边有几个最括号,那就是几维的。 | |||
| 这个俩版本是没有区别的,来举个例子 |
scalar=tf.constant(100)
vector=tf.constant([1,2,3])
matrix=tf.constant([[1,2,3],[4,5,6]])
cube_matrix=tf.constant([[[2],[3]],[[3],[4]]])
print(scalar.shape)
print(vector.shape)
print(matrix.shape)
print(cube_matrix.shape)
输出
()
(3,)
(2, 3)
(2, 2, 1)
查看张量的shape属性出了上面这种,也可以用get_shape()方法获取
>>>cube_matrix.get_shape()
TensorShape([2, 2, 1])
张量的阶
张量的阶(rank)表征了张量的维度
| 阶 | 数学实体| 代码示例 |
|--|--|--|--|
| 0 | Scalar | Scalar = 1000 |
| 1 |Vector| Vector = [2,8,3] |
| 2 | Matrix| Matrix = [[4,2,1],[5,3,2],[5,5,6]] |
| 3 |3-tensor | Tensor = [[[4],[3],[2]],[[6],[100],[4]],[[5],[1],[4]]] |
| N |N-tensor | … |
阶为1的张量等价于向量;
阶为2的张量等价于矩阵,通过t[i,j] 获取元素;
阶为3的张量,通过t[i,j,k] 获取元素;
来举个例子
>>>cube_matrix=tf.constant([[[2],[3]],[[3],[4]]])
>>>print(cube_matrix.numpy()[1,1,0])
4
张量的类型
TensorFlow支持不同的类型
- 实数: tf.float32, tf.float64
- 整数: tf.int8, tf.int16, tf.int32, tf.int64, tf.uint8
- 布尔 :tf.bool
- 复数 :tf.complex64, tf.complex128
不带小数点的数会被默认为int32,带小数点的会被默认为float32
注意:TensorFlow会对参与运算的所有张量进行类型的检查,发现类型不匹配时会报错
来举一些例子
a=tf.constant([1,2])
b=tf.constant([2.0,3.0])
result=tf.add(a,b)
显然这段代码是会报错的,具体如下
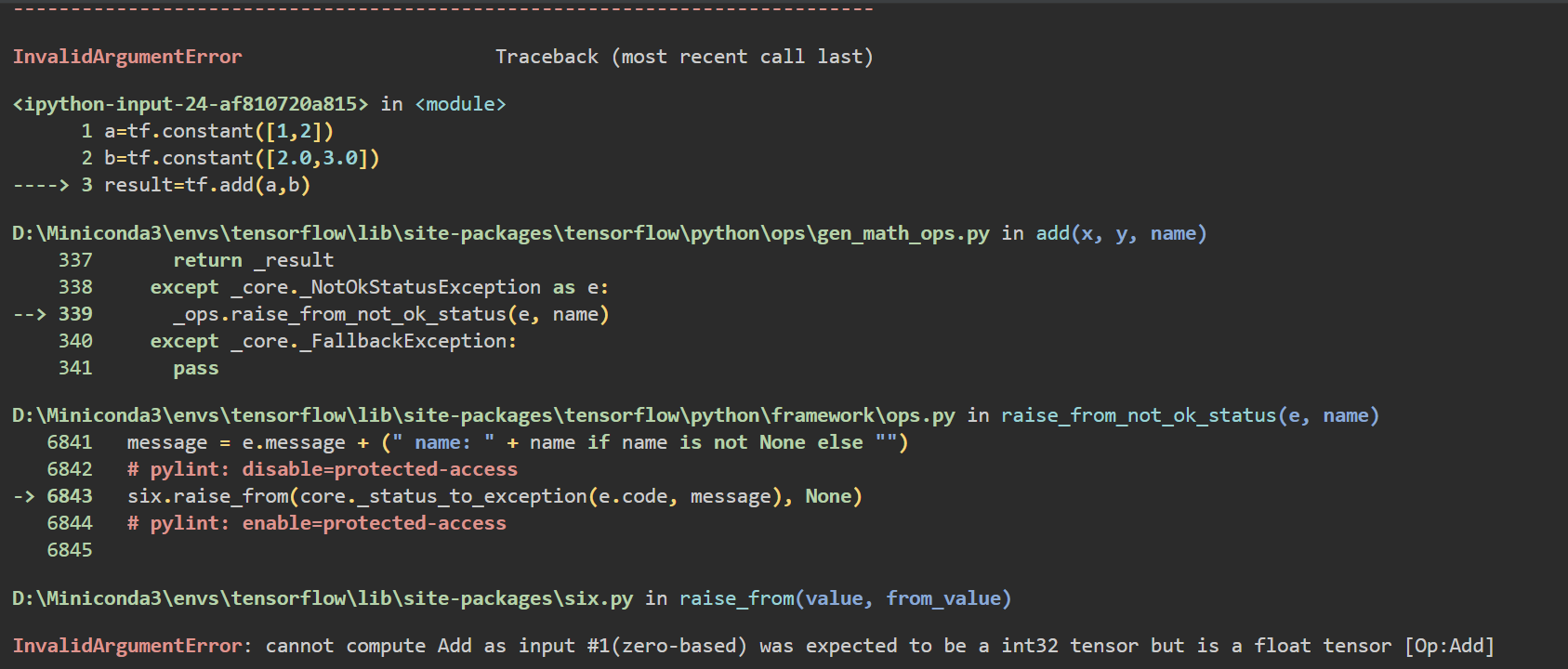
就是个类型不匹配错误,在TensorFlow中,我们可以使用tf.cast()来进行数据类型的转换
a=tf.constant([1,2])
b=tf.constant([2.0,3.0])
a=tf.cast(a,tf.float32)
result=tf.add(a,b)
result
输出
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([3., 5.], dtype=float32)>
这么一来,a的元素就转化为了tf.float32类型的了
当然我们可以通过dtype属性来指定他的类型,但不是必须的。
TensorFlow基本运算
常量 Constant
常量指在执行过程中值不会改变的单元
创建语句
tf.constant(value, dtype=None, shape=None, name="Const"):
在各个参数中,value是必须项,其他如果没填,会自动产生,在TF2中,name已经不那么重要了
这个例子的话,前面都是,就不再重复举例了
变量 Variable
变量指在运行过程中值可以被改变的单元
创建语句
tf.Variable(initial_value=None,
trainable=None,
validate_shape=True,
caching_device=None,
name=None,
variable_def=None,
dtype=None,
import_scope=None,
constraint=None,
synchronization=VariableSynchronization.AUTO,
aggregation=VariableAggregation.NONE,
shape=None))
同样,只有initial_value是必须项,trainable表示变量是否可训练,如果没给出的话,他会默认为True
a=tf.Variable(1)
b=tf.Variable(2,tf.float32)
a,b
输出
(<tf.Variable 'Variable:0' shape=(1,) dtype=int32, numpy=array([1])>,
<tf.Variable 'Variable:0' shape=(1,) dtype=int32, numpy=array([2])>)
此外,给一个变量赋初值的方式除了上面这种意外,还可以将一个常量作为初值赋给一个变量
c=tf.constant(1)
v=tf.Variable(c)
c,v
输出
(<tf.Tensor: shape=(), dtype=int32, numpy=1>,
<tf.Variable 'Variable:0' shape=() dtype=int32, numpy=1>)
在TensorFlow中变量和普通编程语言中的变量有着较大区别。
TensorFlow中的变量是一种特殊的设计,是可以被机器优化过程中自动改变值的张量,也可以理解为待优化的张量。在TensorFlow中变量创建后,一般无需人工进行赋值,系统会根据算法模型,在训练优化过程中自动调整变量的值。
在变量的参数中,trainable参数用来表征当前变量是否需要被自动优化,创建变量对象时默认是启用自动优化标志。
变量的赋值
与传统编程语言不同,TensorFlow中的变量定义后,一般无需人工赋值,系统会根据算法模型,训练优化过程中自动调整变量对应的数值。
但在一些特殊情况下,我们不希望它的值会自动更新,这时候我们可以将它的trainable参数设置为False,那么在需要人工更新时候,可用变量赋值语句assign()来现实
举个例子
v=tf.Variable(5,trainable=False)
v.assign(v+1)
v
输出
<tf.Variable 'Variable:0' shape=() dtype=int32, numpy=6>
此外TensorFlow还提供了assign_add()和assign_sub()来实现变量的加法和减法
a=tf.Variable(1)
b=tf.Variable(2)
a.assign_add(1)
b.assign_sub(1)
a,b
输出
(<tf.Variable 'Variable:0' shape=() dtype=int32, numpy=2>,
<tf.Variable 'Variable:0' shape=() dtype=int32, numpy=1>)
占位符 placeholder
注意:这是TensorFlow1中的一种数据类型!!!在TF2中它其实已经被删除了,当然我们还是可以用
tf.compat.v1包中的占位符来使用它,这段可以直接跳过!!这里粗略带过一下(用的时候要关闭动态!)
TensorFlow中的Variable变量类型,在定义时需要初始化,但有些变量定义时并不知道其数值,只有当真正开始运行程序时,才由外部输入,比如训练数据,这时候需要用到占位符。
占位符是TensorFlow中特有的一种数据结构,类似动态变量,函数的参数、或者C语言或者Python语言中格式化输出时的“%”占位符,我们可以使用 tf.placeholder来创建它
创建
TensorFlow占位符Placeholder,先定义一种数据,其参数为数据的Type和Shape
占位符Placeholder的函数接口如下:
tf.placeholder(dtype, shape=None, name=None)
举个例子
>>>x=tf.compat.v1.placeholder(tf.float32,[2,3],name="tx")
>>>x
<tf.Tensor 'tx_1:0' shape=(2, 3) dtype=float32>
Feed提交数据
如果构建了一个包含placeholder操作的计算图,当在session中调用run方法时,placeholder占用的变量必须通过feed_dict参数传递进去,否则报错

多个操作可以通过一次Feed完成执行

TensorBoard可视化初步
TensorBoard是TensorFlow的可视化工具,通过TensorFlow程序运行过程中输出的日志文件可视化TensorFlow程序的运行状态,TensorBoard和TensorFlow程序跑在不同的进程中。
这里就简单看个案例就好了
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
tf.reset_default_graph()
logdir='logs'#日志保存地址,空就是当前目录下
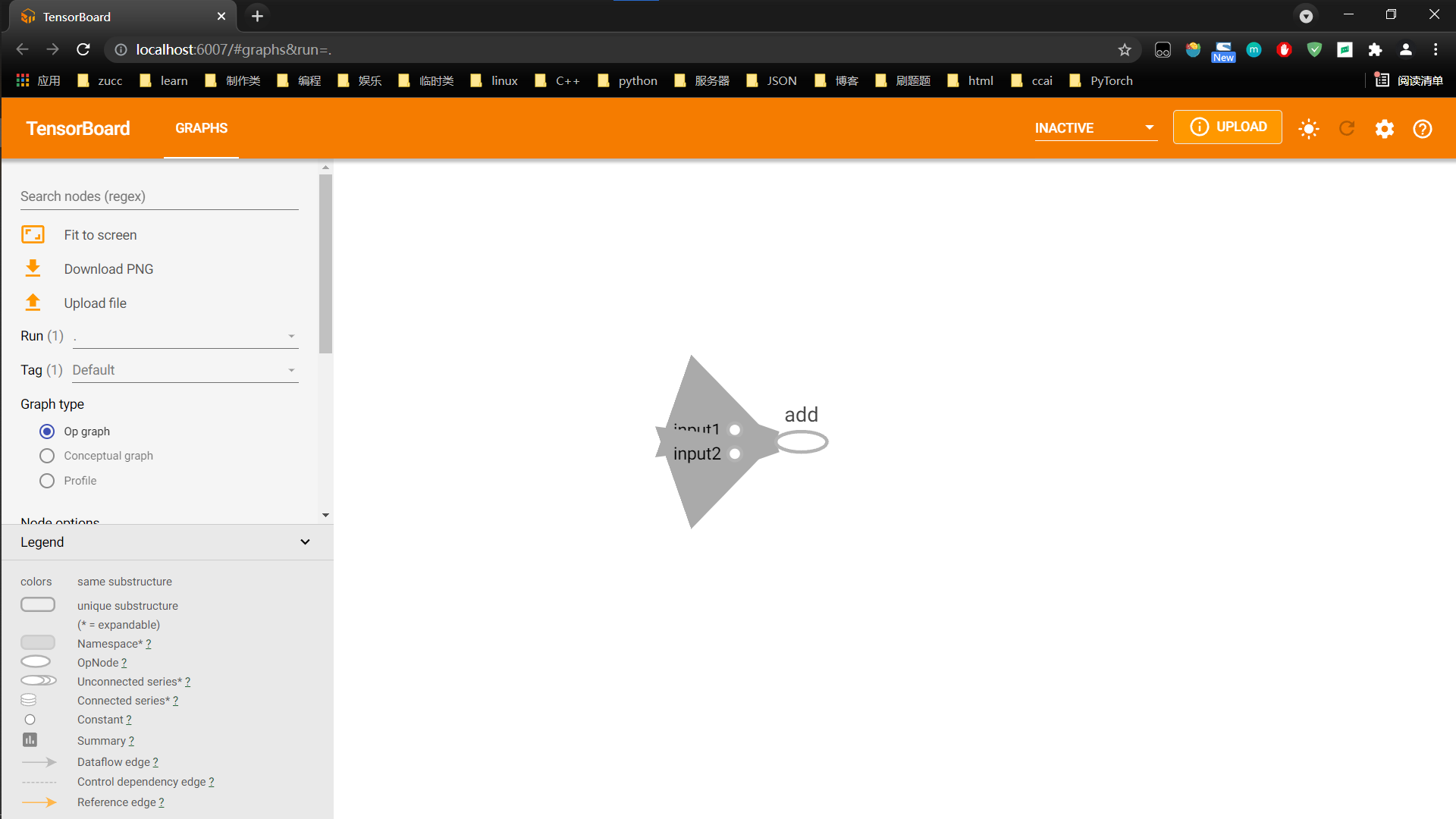
input1=tf.constant(3,name="input1")
input2=tf.constant(4,name="input2")
output=tf.add(input1,input2,name="add")
# 生成日志并写入计算图
writer=tf.summary.FileWriter(logdir,tf.get_default_graph())
writer.close()
运行完成后,会在你指定的目录下生成一个这样的文件

接下来打开终端,进入对应环境和文件夹,输入
tensorboard --logdir=logs --port=6007
--logdir的值为你日志的目录,--port可以修改端口,非必须项,默认为6006

接下来你可以在浏览器中打开出现的那个网址,我这里是http://localhost:6007/,就可以看到对应的图了
参考文章
以下为我在解决这些问题时候看的所有文章,感谢文章以下博主
【1】https://blog.csdn.net/weixin_38410551/article/details/103631977
学习笔记,仅供参考,如有错误,敬请指正!
同时发布在CSDN中:https://blog.csdn.net/tangkcc/article/details/120595492