@
目录
机器学习的定义
根据已有的数据进行算法选择,并基于算法和数据构建模型,最终对未来进行预测。
算法中的基本参数
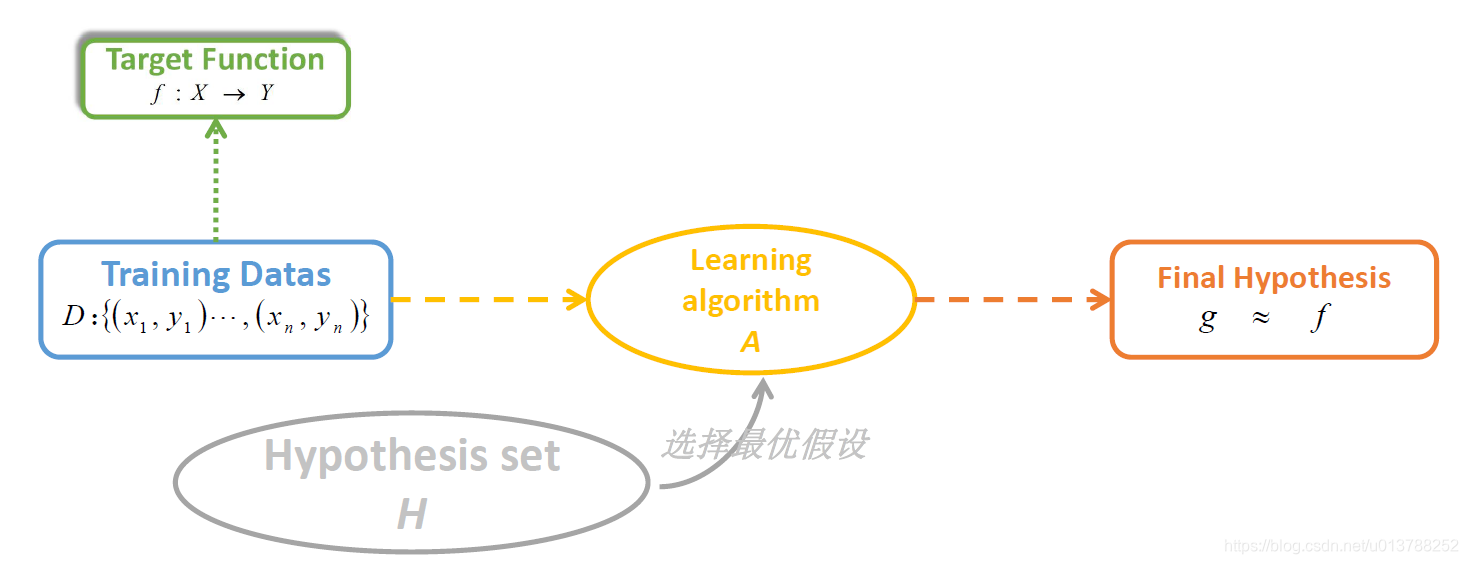
- 输入: x∈χ(属性值)
- 输出:y∈Y(目标值)
- 获得一个目标函数(target function):
f: X→Y(理想公式) - 输入数据:D={(x1,y1),(x2,y2),.....(xn,yn)}
- 最终具有性能的假设公式:
g: X→Y(学习得到的最终公式)
对算法的数据的常规描述
- 拟合:构建的算法符合给定数据的特征
- x(i) :表示第i个样本的x向量
- xi : x向量的第i维度的值
- 鲁棒性:也就是健壮性、稳健性、强健性,是系统的健壮性;当存在异常数据的时候,算法也会拟合数据
- 过拟合:算法太符合样本数据的特征,对于实际生产中的数据特征无法拟合
- 欠拟合:算法不太符合样本的数据特征
机器学习分类
有监督学习
- 用已知某种或某些特性的样本作为训练集,以建立一个数学模型,再用已建立的模型来预测未知样本,此种方法被称为有监督学习,是最常用的一种机器学习方法。是从标签化训练数据集中推断出模型的机器学习任务。
- 判别式模型(Discriminative Model):直接对条件概率p(y|x)进行建模,常见判别模型有:线性回归、决策树、支持向量机SVM、k近邻、神经网络等;
- 生成式模型(Generative Model):对联合分布概率p(x,y)进行建模,常见生成式模型有:隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA等;
- 特点:
1.生成式模型更普适;判别式模型更直接,目标性更强。
2.生成式模型关注数据是如何产生的,寻找的是数据分布模型。
3.判别式模型关注的数据的差异性,寻找的是分类面。
4.由生成式模型可以产生判别式模型,但是由判别式模式没法形成生成式模型。
无监督学习
- 与监督学习相比,无监督学习的训练集中没有人为的标注的结果,在非监督的学习过程中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。
- 无监督学习试图学习或者提取数据背后的数据特征,或者从数据中抽取出重要的特征信息,常见的算法有聚类、降维、文本处理(特征抽取)等。
- 无监督学习一般是作为有监督学习的前期数据处理,功能是从原始数据中抽取出必要的标签信息。
半监督学习
- 考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题,是有监督学习和无监督学习的结合 。
- 无监督学习试图学习或者提取数据背后的数据特征,或者从数据中抽取出重要的特征信息,常见的算法有聚类、降维、文本处理(特征抽取)等。
- 无监督学习一般是作为有监督学习的前期数据处理,功能是从原始数据中抽取出必要的标签信息
机器学习开发流程
数据收集与存储
- 数据来源:
- 用户访问行为数据
- 业务数据
- 外部第三方数据
- 数据存储:
- 需要存储的数据:原始数据、预处理后数据、模型结果
- 存储设施:mysql、HDFS、HBase、Solr、Elasticsearch、Kafka、Redis等
- 数据收集方式:
- Flume & Kafka
- 在实际工作中,我们可以使用业务数据进行机器学习开发,但是在学习过程中,没有业务数据,此时可以使用公开的数据集进行开发,常用数据集如下:
- http://archive.ics.uci.edu/ml/datasets.html
- https://aws.amazon.com/cn/public-datasets/
- https://www.kaggle.com/competitions
- http://www.kdnuggets.com/datasets/index.html
- http://www.sogou.com/labs/resource/list_pingce.php
- https://tianchi.aliyun.com/datalab/index.htm
- http://www.pkbigdata.com/common/cmptIndex.html
数据预处理
- 对数据进行初步的预处理,需要将其转换为一种适合机器学习模型的表示形式,对许多模型类型来说,这种表示就是包含数值数据的向量或者矩阵。
- 将类别数据编码成为对应的数值表示(一般使用1-of-k方法)-dumy。
- 从文本数据中提取有用的数据(一般使用词袋法或者TF-IDF)。
- 处理图像或者音频数据(像素、声波、音频、振幅等<傅里叶变换>)。
- 数值数据转换为类别数据以减少变量的值,比如年龄分段。
- 对数值数据进行转换,比如对数转换。
- 对特征进行正则化、标准化,以保证同一模型的不同输入变量的值域相同。
- 对现有变量进行组合或转换以生成新特征,比如平均数 (做虚拟变量)不断尝试。
特征提取
模型构建
- 模型选择:对特定任务最优建模方法的选择或者对特定模型最佳参数的选择。
模型测试评估
-
在训练数据集上运行模型(算法)并在测试数据集中测试效果,迭代进行数据模型的修改,这种方式被称为交叉验证(将数据分为训练集和测试集,使用训练集构建模型,并使用测试集评估模型提供修改建议)。
-
模型的选择会尽可能多的选择算法进行执行,并比较执行结果。
-
模型的测试一般以下几个方面来进行比较,分别是准确率/召回率/精准率/F值。
- 准确率(Accuracy)=提取出的正确样本数/总样本数。
- 召回率(Recall)=正确的正例样本数/样本中的正例样本数——覆盖率。
- 精准率(Precision)=正确的正例样本数/预测为正例的样本数。
- F值=PrecisionRecall2 / (Precision+Recall) (即F值为正确率和召回率的调和平均值)。
投入使用(模型部署与整合)
- 当模型构建好后,将训练好的模型存储到数据库中,方便其它使用模型的应用加载(构建好的模型一般为一个矩阵)。
- 模型需要周期性:一个月、一周。
迭代优化
- 当模型一旦投入到实际生产环境中,模型的效果监控是非常重要的,往往需要关注业务效果和用户体验,所以有时候会进行A/B测试(3:7测试:就是原来系统和加了算法的测试,测试两者的区别)。
- 模型需要对用户的反馈进行响应操作,即进行模型修改,但是要注意异常反馈信息对模型的影响,故需要进行必要的数据预处理操作。