作者:楼永红 王轩宇|浙商银行
浙商银行股份有限公司(简称“浙商银行")是 12 家全国性股份制商业银行之一,总部设在浙江杭州,全国第13家"A+H"上市银行,致力于打造平台化服务银行,为客户提供开放、高效、灵活、共享、极致的综合金融服务。在英国《银行家》(The Banker) 杂志“2020 年全球银行 1000 强"榜单中,位列第 97 位。
浙商银行很早就开始全面推进数字化转型,2010 年浙商银行上线电子银行服务、手机银行业务,2017 年上线首个区块链服务平台,同年发布了直销银行品牌。2018 年浙商银行国标 A 级数据中心启用,并在 2020 年成立易企银金融科技子公司。
业务背景
浙商银行微服务可视化治理平台是基于Java体系自研的微服务治理监控平台,为行内基于统一的微服务框架开发的应用提供全面、实时的微服务治理监控功能,能够有效提升云环境下的微服务可视化程度和服务管理控制的便捷度,减少服务故障发现时间,提升故障定位效率,辅助应用程序优化。在这样的业务场景中,数据量大、监控指标繁杂成了我们的主要挑战。
通过分析监控数据,我们发现它有以下特点:
• 数据高写入、低查询、不修改
对于按时间顺序插入的监控数据,会涉及到少量的查询,没有修改数据的业务场景。
• 无需事务支持
如果数据模型设计妥当,无需使用事务处理。
• 各监控指标之间相互独立,无需联合查询
• 数据时效性较强,超过一定时间的数据参考价值很小
核心诉求
针对这样的场景,我们需要一款能高效处理时序数据的工具。在各种因素的影响下,我们有如下几点需求:
• 开源可控,且最好是国产软件,且能支持国产化芯片
• 功能稳定
• 社区活跃:开发者社区人员多,问答、讨论频繁且有稳定的开发团队支持
• 部署成本低:尽可能少的服务节点,运维成本低,占用 CPU、内存资源较少
• 性能强大:支持万条数据秒级插入
时序数据库选型
具体对比如下:
Apache Druid:Druid 是 Apache 基金会旗下的一款高性能的实时分析数据库,支持时间序列数据。功能强大、可自愈、自平衡、易操作、可进行有效的预聚合和预计算。不过对于时间跨度较大的查询不够灵活,而且架构较为复杂,需要的计算资源多。
InfluxDB:InfluxDB 是由 InfluxData 公司开发的一款开源的时序数据库,在业界非常流行。功能强大,部署简单,使用方便。不过集群功能没有开源。
TDengine:能满足我们的核心诉求,相关测试表明其性能优于 InfluxDB,而且开源了核心的集群功能。简单快捷、性能强大;支持 JDBC 接口,可以使我们应用快速接入使用。还有一点非常重要,因为 TDengine 的核心研发团队在国内,很方便直接交流。
整体对比之后,我们决定尝试 TDengine。
技术架构
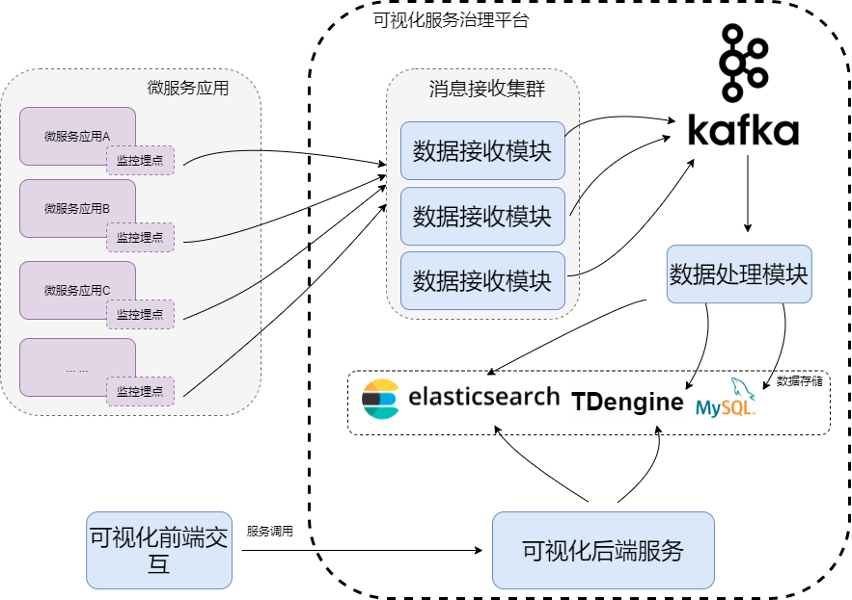
可视化服务治理平台的一个核心功能就是实时的监控功能,监控数据通过微服务框架自带的埋点发送到数据接收模块,经过数据处理和格式转换之后发送到 Apache Kafka。数据处理模块会接收 Kafka 中的各类监控数据,根据不同的数据类型进行加工计算,存储到 Elasticsearch 和 TDengine 中。用户通过前端与后端的服务层对监控数据进行查询分析。
目前为止,存储于 TDengine 中的数据主要为时序类数据,如CPU、内存使用率等系统运行数据,微服务调用、分布式锁、数据库操作处理时间,业务线程池、连接池等各类指标数据。
数据模型
目前收集的监控数据类型如下:
• JVMGC 相关指标
• JVMThread 相关指标
• JVMMemory 相关指标
• 系统负载相关指标
• 数据库连接池监控数据
• Transaction 调用监控数据
• Dubbo 线程池监控数据
我们针对每一个监控类型都采用了超级表建表,以 JVMGC 为例,建表语句为:
create stable JVMGC (happentime timestamp, jvmUsedMemory bigint, jvmUsedMemoryyPercentage double, nonHeapMemoryUsed double, oldGenUsed bigint, oldGenUsedPercentage double , directBufferUsed bigint) tags (application NCHAR(300), host NCHAR(500), ip NCHAR(50))
与此同时,对每一个监控节点都建立一张子表,这样处理的好处在于:
• 相同指标在进行多表查询时,可以利用超级表在一个 SQL 语句中完成查询
• 超级表可以实现表与表之间的数据聚合
• 对于单节点的监控数据,查询只需要访问单一子表即可
使用体验
目前微服务可视化服务治理平台对并发要求较高,但是 TDengine 可以很好地满足需求,插入/查询平均耗时均在 10ms 以内。
TDengine 的开源版本小而精致,开发测试人员可以自己搭建私有的 TDengine 集群进行测试,无须担心影响他人,非常方便。
TDengine 的社区非常活跃,遇到问题在 GitHub 上提 issue,或直接在官方的微信交流群里讨论,都可以快速得到响应。
总结
TDengine 很好地满足了我们的需求,性能和稳定性都非常出色,同时极大降低了部署和运维成本。
TDengine 的支持团队也非常积极热心,能够快速解决我们遇到的大部分问题,为我们免除了后顾之忧。
作为一款为物联网场景设计的时序数据库,TDengine 以存储效率高、性能强大、功能稳定等特点在传统互联网应用架构中同样有着相当出色的发挥,超级表的设计省去了不少联表查询逻辑,大大简化了业务层的开发工作。接下来,我们也期待在行内挖掘出更多 TDengine 的应用场景。