一、开始认识Flask
刚接触Flask是源于想整合两个接口服务到一块里面,之前开发接口用的是Python spyne并把它集成在Django里面,感觉只是做接口服务没必集也集成到Django框架里,不够灵活。
无意中在网上搜索到Python的Flask框架,网友们使用Flask 设计 RESTful API。今天开始认识Flask
什么是 “微”?
Flask官网上这样介绍:
“微” (“Micro”) 并不是意味着把整个 Web 应用放入到一个 Python 文件,尽管确实可以这么做。当然“微” (“Micro”) 也不是意味 Flask 的功能上是不足的。微框架中的 “微” (“Micro”) 是指 Flask 旨在保持代码简洁且易于扩展。
易于扩展,灵活选择模板文件jinja,数据引擎flask-SQLALchemy,表单验证flask-wtf各类扩展,大多以“flask-”打头的,添加到应用中实现。使用Flask给我的感受就是,不断的下载扩展,添加到virtualenv虚拟开发环境中。
二、Flask的应用
1、搭建Python virtualenv虚拟环境
Python中有一个神器Virtualenv虚拟环境,有了它我们不再需要考虑Python版本的差异,不同版本的Python2.x或者3.x它们可以相互独立,互不影响,不用每次因为版本的不同去切换系统的环境变量,大大节省开发的时间成本;
这符合软件解耦设计思想,不同的应用可以使用不同的套件版本,彼此互相不受影响。
1)安装Virutalenv
pip install virtualenv
2)创建虚拟环境
virtualenv安装目录下,cmd到命令行,这里我创建python2.7的虚拟环境
virtualenv.exe --python=“C:Program FilesPython27python.exe” "D:PythonEnvp2vir"
--p 或者--python 指定python解析器(Python.exe文件路径)
p2vir 创建的虚拟环境目录名称

3)安装各类扩展
(1)下载需要的扩展包,解压到相应的目录下,例如我安装jinja模板扩展的路径E:软件jinja-master
(2)进入python的虚拟环境:输入 D:PythonEnvp2virScriptsactivate.bat
(3)安装jinja命令:python setup.py install
balabalabala....
2、Flask项目目录结构
Flask非常灵活,没有绝对的目录结构,依据个人习惯可以随意设计,网上比较场景有两类,一种是以功能划分和应用划分。
功能划分目录:
项目project下,由models、routes、templates、services,分别用来放数据库模型、路由文件、模板文件和工具。
project/ __init__.py models/ __init__.py base.py users.py posts.py ... routes/ __init__.py home.py account.py dashboard.py ... templates/ base.html post.html ... services/ __init__.py google.py mail.py ...
应用划分目录:
project项目下,有个项目初始化文件__init__.py,数据库文件db.py,两个应用auth和blog分别划分到不同的目录下,每个目录下都有单独的route、models和templates,目录结果比较清晰明了
project/ __init__.py db.py auth/ __init__.py route.py models.py templates/ blog/ __init__.py route.py models.py templates/ ...
综合比较这两种划分方式,我用的是后者,应用划分。我使用的是Pycharm IDE,以下是我的Flask项目目录结构
模板文件统一放到粉色的模板文件目录 templates,templates目录是在Pycharm创建Flask项目,勾选虚拟环境的时候自动创建的。
3、jinja2模板
jinja2是Python的一套模板引擎,灵感来自Django的模板并进行了扩展。
开始使用jinja2,一起来挖坑+填坑
模板文件layout.html
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>{% block title %}{% endblock %}</title> 6 <link rel="stylesheet" href="static/layui/css/layui.css" media="all"> 7 <script type="text/javascript" src="static/layui/layui.js"></script> 8 <script type="text/javascript" src="static/js/jquery-3.1.1.min.js"></script> 9 {% block customstyle %} {% endblock %} 10 {% block customscript %} {% endblock %} 11 </head> 12 <body> 13 {% block conent %}{% endblock %} 14 </body> 15 </html>
实现页面warehouse.html
1 {% extends 'layout.html' %} 2 {% block title %}仓库管理{% endblock %} 3 {% block customstyle %} 4 <style> 5 body { 6 overflow-y: scroll; 7 } 8 </style> 9 {% endblock %} 10 {% block customscript %} 11 <script> 12 function renderForm() { 13 layui.use('form', function () { 14 var form = layui.form; 15 form.render(); 16 }); 17 } 18 </script> 19 {% endblock %} 20 {% block conent %} 21 <div id="content"> 22 <div class="layui-inline"> 23 </div> 24 <div class="layui-inline" style="1200px;height:400px;padding-left:10px" > 25 <table id="warehouse" lay-filter="test"></table> 26 </div> 27 </div> 28 {% endblock %}
4、layui 前端框架
layui官网下载前端框架压缩包,解压缩到相应目录下,拷贝layui目录放到项目里面,实现页面添加引用,就可以开始用layui咯。
我把layui放在static目录下:
5、Flask-SQLALchemy + pymysql
python使用pymysql作为数据库引擎连接和操作数据库,Flask-SQLALchemy是一套ORM(Object Relationship Mapping模型关系映射),
面向对象的思想,一切事物皆是对象,Flask-SQLALchemy ORM可以让我们操作数据库跟操作对象是一样的,非常方便。一个表就抽象成一个类,一条数据就抽象成该类的一个对象。
config.py文件,记录项目相关配置信息,包括指明模板文件的路径、静态文件的路径、数据库URI(数据库mysql、数据库引擎pymysql,域名地址,数据库,登录用户,登录密码,端口号)、数据库超时、连接池等属性
1 # -*- coding: utf-8 -*- 2 import os 3 4 BASE_DIR = os.getcwd() # 项目的绝对路径 5 6 TEMPLATES_DIR = os.path.join(BASE_DIR, 'templates') # 模板文件的路径 7 8 STATICFILES_DIR = os.path.join(BASE_DIR, 'static') # 静态文件的路径 9 10 DIALECT = 'mysql' 11 DRIVER = 'pymysql' 12 USERNAME = 'root' 13 PASSWORD = 'xxxx' 14 HOST = 'xx.xx.xx.xx' 15 PORT = '3306' 16 DATABASE = 'xxx' 17 18 # 数据库URI 19 SQLALCHEMY_DATABASE_URI = '{}+{}://{}:{}@{}:{}/{}?charset=utf8'.format( 20 DIALECT, DRIVER, USERNAME, PASSWORD, HOST, PORT, DATABASE 21 ) 22 23 SQLALCHEMY_TRACK_MODIFICATIONS = True # 查询跟踪,不太需要,False,不占用额外的内存 24 25 SQLALCHEMY_COMMIT_TEARDOWN = True 26 27 SQLALCHEMY_POOL_SIZE = 100 # 数据库连接池大小 28 29 SQLALCHEMY_POOL_TIMEOUT = 30 # 连接池的连接超时时间
__init__.py文件,初始化Flask对象并返回。
1 # -*- coding: utf-8 -*- 2 from flask import Flask 3 from flask_sqlalchemy import SQLAlchemy 4 from config import SQLALCHEMY_DATABASE_URI, SQLALCHEMY_TRACK_MODIFICATIONS, SQLALCHEMY_COMMIT_TEARDOWN, 5 SQLALCHEMY_POOL_SIZE, SQLALCHEMY_POOL_TIMEOUT 6 7 db = SQLAlchemy() # 初始化SQLAlchemy 8 9 10 def create_app(): 11 """创建app的方法""" 12 app = Flask(__name__) # 生成Flask对象 13 app.config['SQLALCHEMY_DATABASE_URI'] = SQLALCHEMY_DATABASE_URI # 配置 app的URI 14 app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = SQLALCHEMY_TRACK_MODIFICATIONS 15 app.config['SQLALCHEMY_COMMIT_TEARDOWN'] = SQLALCHEMY_COMMIT_TEARDOWN 16 app.config['SQLALCHEMY_POOL_SIZE'] = SQLALCHEMY_POOL_SIZE 17 app.config['SQLALCHEMY_POOL_TIMEOUT'] = SQLALCHEMY_POOL_TIMEOUT 18 19 db.init_app(app=app) 20 21 # 在这里还可设置好配置后,初始化其他的模块 22 23 return app # 返回Flask对象app
models.py文件,数据库模型,使用Flask-SQLALchemy进行ORM映射,使得我们可以想操作对象一样操作数据库的增、删、改、查。
1 # -*- coding: utf-8 -*- 2 from flask import Flask 3 from flask_sqlalchemy import SQLAlchemy 4 from iMock import create_app 5 from flask_script import Manager 6 import datetime 7 8 # 创建Flask对象 9 app = create_app() 10 11 # 获取SQLAlchemy实例对象,接下来就可以使用对象调用数据 12 db = SQLAlchemy(app) 13 14 15 class SFErpOrder(db.Model): 16 __tablename__ = 't_sf_erpOrder' 17 id = db.Column(db.Integer, primary_key=True) 18 skuNo = db.Column('skuNo', db.String(200)) 19 qty = db.Column(db.Integer) 20 erpOrder = db.Column('erpOrder', db.String(100)) 21 warehouseCode = db.Column('warehouseCode', db.String(100)) 22 serialNumber = db.Column('serialNumber', db.Text) 23 receiptId = db.Column('receiptId', db.String(100)) 24 create_time = db.Column(db.DateTime, default=datetime.datetime.now()) 25 modify_time = db.Column(db.DateTime, default=datetime.datetime.now()) 26 27 def to_json(self): 28 dict = self.__dict__ 29 if "_sa_instance_state" in dict: 30 del dict["_sa_instance_state"] 31 return dict 32 33 def __repr__(self): 34 return '<t_sf_erpOrder %r> ' % self.id 35 36 37 class SFOutErpOrder(db.Model): 38 __tablename__ = 't_sf_outErpOrder' 39 id = db.Column(db.Integer, primary_key=True) 40 skuNo = db.Column('skuNo', db.String(200)) 41 fqlOrder = db.Column('fqlOrder', db.String(100)) # 分期乐订单O20170831XXXXXXX 42 warehouseCode = db.Column('warehouseCode', db.String(100)) 43 outIMEI = db.Column('outIMEI', db.Text) 44 itemQuantity = db.Column(db.Integer) 45 shipMentId = db.Column('shipMentId', db.String(100)) 46 create_time = db.Column(db.DateTime, default=datetime.datetime.now()) 47 modify_time = db.Column(db.DateTime, default=datetime.datetime.now()) 48 49 def __repr__(self): 50 return '<t_sf_outErpOrder %r> ' % self.id 51 52 53 manager = Manager(app) 54 55 if __name__ == '__main__': 56 db.create_all() # 创建数据表 57 manager.run()
Flask-SQLALchemy常用数据类型:
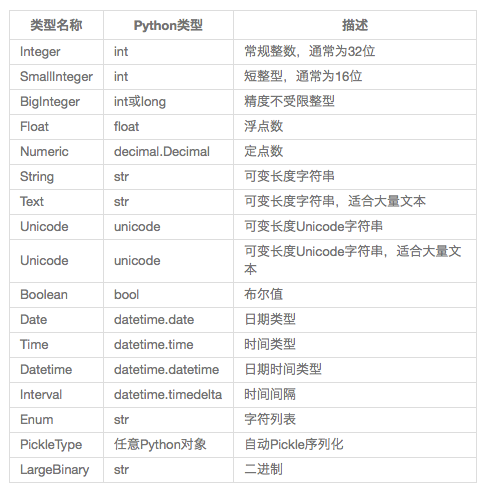
Flask-SQLALchemy可选参数:
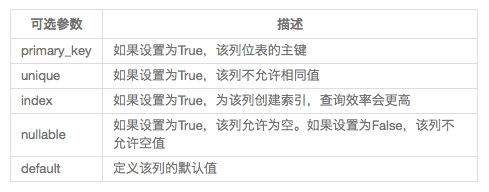
Flask-SQLALchemy数据表主外键关系:
1对多关系
1 class Person(db.Model): 2 id = db.Column(db.Integer, primary_key=True) 3 name = db.Column(db.String(50), nullable=False) 4 addresses = db.relationship('Address', backref='person', lazy=True) 5 6 class Address(db.Model): 7 id = db.Column(db.Integer, primary_key=True) 8 email = db.Column(db.String(120), nullable=False) 9 person_id = db.Column(db.Integer, db.ForeignKey('person.id'), 10 nullable=False)
多对多关系
1 tags = db.Table('tags', 2 db.Column('tag_id', db.Integer, db.ForeignKey('tag.id'), primary_key=True), 3 db.Column('page_id', db.Integer, db.ForeignKey('page.id'), primary_key=True) 4 ) 5 6 class Page(db.Model): 7 id = db.Column(db.Integer, primary_key=True) 8 tags = db.relationship('Tag', secondary=tags, lazy='subquery', 9 backref=db.backref('pages', lazy=True)) 10 11 class Tag(db.Model): 12 id = db.Column(db.Integer, primary_key=True)
Flask-SQLALchemy数据库操作:


操作数据库,根据查询条件像 sql where一样实现条件查询。更多操作
from .models import * try: sfErpOrder = SFErpOrder().query.filter_by(erpOrder=ErpOrder).first()
# total_count = SFErpOrder.query.filter_by(**filter_dict).count() # filter_by支持多条件查询 **filter_dict字典参数
except Exception as err:
print traceback.print_exc()
6、flask-script+flask-migrate+alembic
Flask-Migrate
Flask-Migrate是Flask的一个扩展,底层使用的是Alembic,主要用来处理Flask应用关于SQLAlchemy数据库变更的迁移。更多
相关命令:
初始化数据库,在工程中新建migrations目录,在数据库中生成一个alembic_version表,记录数据库迁移版本信息version_num
python manage.py db init
执行以下命令,生成数据库迁移脚本文件,保存在versions目录下面
python manage.py db migrate
官网有这么一句话:
The migration script needs to be reviewed and edited, as Alembic currently does not detect every change you make to your models.
In particular, Alembic is currently unable to detect table name changes, column name changes, or anonymously named constraints.
意思是flask-migrate底层的Alembic不能够侦测到全部对于模型的改动,包括数据表名称变更、字段名称变更或者匿名命名约束的变化等。这个时候
我们可以手动修改migrate生成的版本文件
1 def upgrade(): # 升级方法 2 # 举个例子:这里修改数据表t_sf_erpOrder字段名skuNoo为skuNo,并且变更字符串长度为200字节 3 op.alter_column('t_sf_erpOrder', 'skuNoo', new_column_name='skuNo',existing_type=mysql.VARCHAR(length=200)) 4 5 def downgrade(): # 降级方法 6 op.create_table('t_sf_erpOrder', 7 sa.Column('id', mysql.INTEGER(display_width=11), autoincrement=True, nullable=False), 8 sa.Column('skuNoo', mysql.VARCHAR(length=100), nullable=True),
最后把数据库变更应用到数据库,使得改动生效。更多操作
python manage.py db upgrade
Flask-Script
Flask-Script是Flask的一个扩展,使得Flask可以执行外部的脚本,包括运行开发服务器,自定义的Python shell脚本,数据库操作脚本,定时cronbjobs任务和其他命令行脚本。更多
Flask-Script和Flask-migrate的应用实例:
这个是我的manage.py项目启动文件
1 # -*- coding: utf-8 -*- 2 from flask_script import Manager, Server 3 from flask_migrate import MigrateCommand, Migrate 4 from flask_sqlalchemy import SQLAlchemy 5 from iMock import create_app 6 from iMock.api import api 7 from iMock.warehouse import warehouse 8 """ 9 注意 10 11 在这里一定要严格在遵守Python导入包的编写顺序 12 13 Python Build In 内构包 14 Python 第三方库 15 用户自定义模块 16 """ 17 18 19 app = create_app() # 创建app 20 app.register_blueprint(api, url_prefix='/imock') # 注册蓝图 21 app.register_blueprint(warehouse, url_prefix='/warehouse') # 注册蓝图 22 23 manager = Manager(app) # 通过app创建manager对象 24 db = SQLAlchemy(app) 25 migrate = Migrate(app, db) 26 27 manager.add_command("runserver", Server(use_debugger=True)) # 添加到命令行 28 manager.add_command("db", MigrateCommand) # 添加到命令行 29 30 31 if __name__ == '__main__': 32 manager.run() # 运行服务器
在Pycharm中,设置下启动配置启动参数,Run->Edit Configuration...->Configuration的Parameters设置为“runserver --thread” ,参数的意识“开启多线程模式”,避免频繁访问缓慢卡顿。
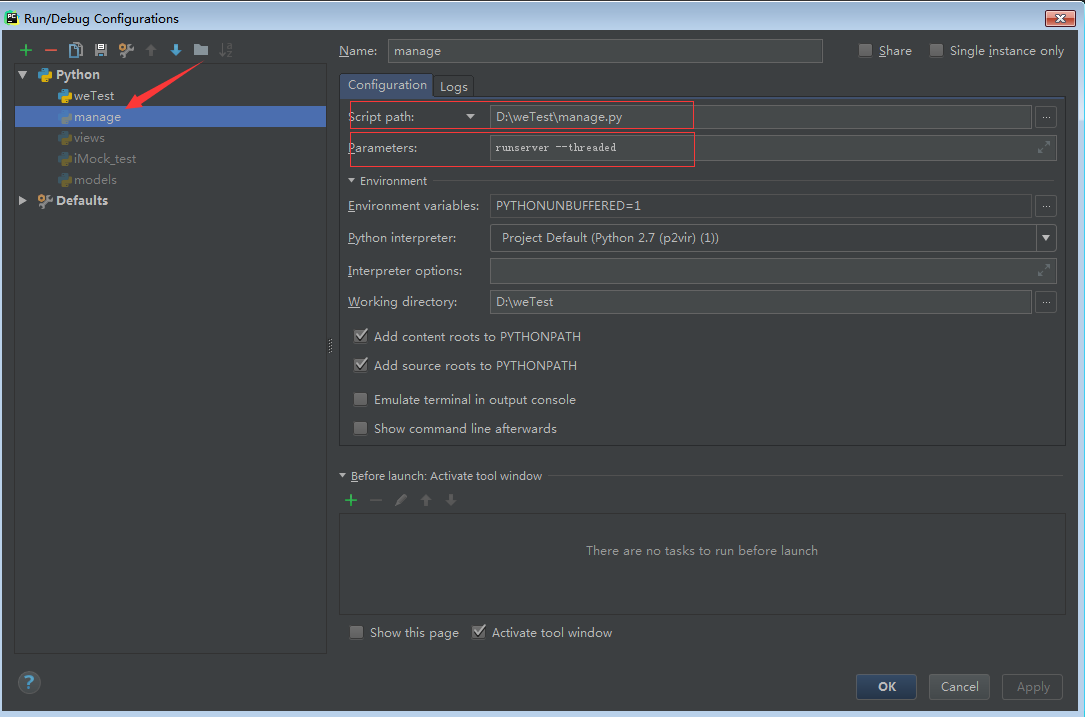
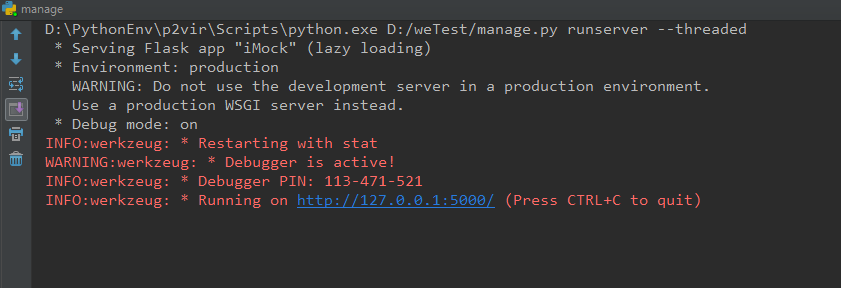
直接右键执行manage.py启动脚本,看到下面的终端日志,说明服务器启动成功,默认端口号5000,可以开始访问了
三、Flask的总结
Python Flask框架已经基本搭建完毕,期间涉及到Flask框架特性和原理、项目结构,Flask的配置文件、jinja2模板、Flask-SQLAlchemy,Pymysql,Flask-script,Flask-Migrate,Alembic,启动文件相关知识;
目前算是入了Flask的门,接下来就要在平时的实践中不断去摸索和学习框架的相关东西,Flask的各类扩展,使得Flask更好地应用到我的工作当中。
转载&&参考:
Python Flask 官网 http://www.pythondoc.com/flask/index.html
Python Flask 开发环境virtualenv搭建 https://blog.csdn.net/doago/article/details/50488586
Virtualenv用户操作指南 https://virtualenv.pypa.io/en/latest/reference/
Python Flask项目结构 https://lepture.com/en/2018/structure-of-a-flask-project
前端框架Layui https://www.layui.com/
Alembic https://www.cnblogs.com/xiaoming279/p/6641601.html
作者的寄语:
每天进步一点点,慢慢成为更好的自己。