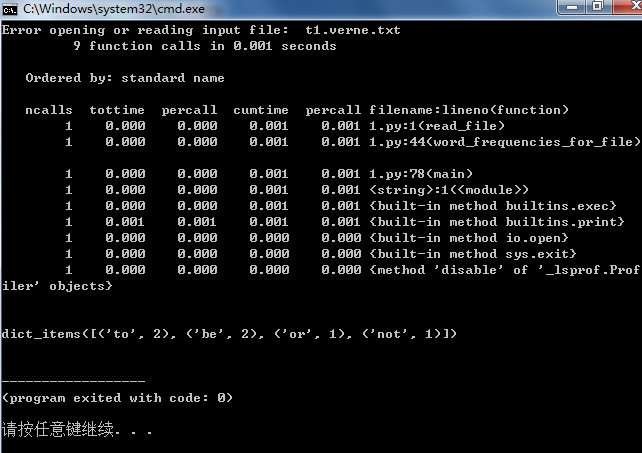
1 def read_file(filename):#读入文件 2 try: 3 fp=open(filename) #打开文件 4 L=fp.readlines() #按行读入 5 except IOError: #如果没找到文件 6 print("Error opening or reading input file: ",filename) #输出显示没找到的文件名 7 sys.exit() #提前import sys 8 return L #读到文件的每一行 9 10 def get_word_from_string(line):#将字符组合成单词 #输入一行 11 word_list=[] #创建空列表,用来存单词 12 character_list=[] #空列表 13 for c in line: 14 if c.isalnum(): #通过isalnum()函数检测字符串是否由字母和数字组成 15 character_list.append(c) #将数字和字母串添加到character_list列表中 16 elif len(character_list)>0: 17 word="".join(character_list) #如果遇到非数字或字母,将character_list中的字符通过函数join连接成word 18 word=str.lower(word) #如果输入line='a cat a 12',输出为['a','cat','a','12'] 19 word_list.append(word) 20 if len(character_list)>0: 21 word="".join(character_list) 22 word=str.lower(word) 23 word_list.append(word) 24 return word_list 25 26 def get_word_from_line_list(L):#得到文档单词 27 word_list=[] 28 for line in L: 29 words_in_line=get_word_from_string(line) #调用get_word_from_string()函数得到一行单词 30 #word_list=word_list+words_in_line 31 word_list.extend(word_in_line) #将一行中的各个单词存于word_list中 32 return word_list 33 34 def count_frequency(word_list):#利用字典数据结构计算每一个单词出现的频次 35 D={} 36 for new_word in word_list: 37 if new_word in D: 38 D[new_word]=D[new_word]+1 39 else: 40 D[new_word]=1 41 return D.items() 42 43 44 def word_frequencies_for_file(filename):#对向量内的元素进行排序预处理 45 line_list=read_file(filename) 46 word_list=get_word_from_line_list(filename) 47 freq_mapping=count_frequency(word_list) 48 sortde_freq_mapping=sorted(freq_mapping) 49 return sortde_freq_mapping 50 51 52 def inner_product(L1,L2): #计算俩向量内积 53 sum=0.0 54 i=0 55 j=0 56 while i<len(L1) and j<len(L2): 57 if L1[i][0]==L2[j][0]: 58 #两个都有的单词才计算内积 59 sum+=L1[i][1]*L2[j][1] 60 i+=1 61 j+=1 62 elif L1[i][0]<L2[j][0]: 63 #单词L1[i][0]在L1不在L2 64 i+=1 65 else: 66 j+=1 67 return sum 68 69 70 71 def vector_angle(L1,L2):#计算俩向量夹角 72 numerator=inner_product_product(L1,L2) 73 denominator=math.sqrt(inner_product(L1,L1)*inner_product(L2,L2)) 74 return math.acos(numerator/denominator) 75 76 77 78 def main():#文档比较主函数 79 filename_1="t1.verne.txt" 80 filename_2="t1.verne.txt" 81 sorted_word_list_1=word_frequencies_for_file(filename_1) 82 sorted_word_list_2=word_frequencies_for_file(filename_2) 83 distance=vector_angle(sorted_word_list_1,sorted_word_list_2) 84 print("The distance bewteen the documents is: %0.6f(radians)"%distance) 85 86 if __name__=="__main__": 87 import cProfile #调用import cProfile查看每个函数占用的处理时间 88 import sys 89 cProfile.run("main()") 90 91 92 93 print(count_frequency(word_list=['to','be','or','not','to','be']))