tcp传输:
传输需要ack回应,然后才清空缓存,服务端先起来。
tcp流式协议,tcp的Nagle的优化算法,会将时间间隔短,数据量小的打包成一个,然后发送给对方,减少发送的次数。
UDP协议:
不用建连接,不用确认。速度快,强调速度的场景,ntp,dns,udp有效的传输512bytes。
不用listen,accept,connect.
udp套接字,如果一次没有收够的话,剩下的丢弃,在linux中,比如 recvfrom(3) sendto(4) 就会只接收三个。windows系统会报错。


from socket import * server = socket(AF_INET,SOCK_DGRAM) server.bind(("127.0.0.1",8081)) while True: data,client_addr = server.recvfrom(1024) print(data,client_addr) server.sendto(data.upper(),client_addr例子
from socket import * client = socket(AF_INET,SOCK_DGRAM) while True: msg = input(">>>:").strip() client.sendto(msg.encode('utf-8'),("127.0.0.1",8081)) data,server_addr = client.recvfrom(1024) print(data.decode('utf-8'))
操作系统的概念:
操作的作用:操作硬件,封装接口,控制进程,控制竞争。
进程:相当于部门
线程:是部门中干活的人
多道技术:当cpu在等待i/o的过程中,去干其他的工作。背景:单核下实现并发的效果。
(1)空间上的复用:内存分为及部分,每个部分放入一个程序
(2)时间上的复用:当一个进程在等待i/o时候,另一个程序可以使用cpu,当一个程序在等待I/O时,另一个程序可以使用cpu, 如果内存中可以同时存放足够多的作业,则cpu的利用率可以接近100%,类似于我们小学数学所学的统筹方法。(操作系统采用了 多道技术后,可以控制进程的切换,或者说进程之间去争抢cpu的执行权限。这种切换不仅会在一个进程遇到io时进行,一个进程占 用。
(3)切换的3种情况
cpu时间过长也会切换,或者说被操作系统夺走cpu的执行权限.
有i/o切换时,提升效率。
优先级切
并发与并行:
无论是并行还是并发,在用户看来都是'同时'运行的,不管是进程还是线程,都只是一个任务而已,真的干活的是cpu,cpu来做这些任务,而一个cpu同一时刻只能执行一个任务
一 并发:是伪并行,即看起来是同时运行。单个cpu+多道技术就可以实现并发,(并行也属于并发)
二 并行:同时运行,只有具备多个cpu才能实现并行
单核下,可以利用多道技术,多个核,每个核也都可以利用多道技术(多道技术是针对单核而言的)
进程的三种状态:
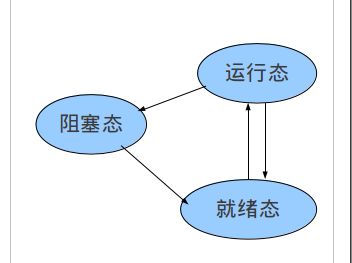
在linux中,进程创建调用fork
在windows中,进程创建调用 CreateProcess
关于创建的子进程,UNIX和windows
1.相同的是:进程创建后,父进程和子进程有各自不同的地址空间(多道技术要求物理层面实现进程之间内存的隔离),任何一个进程的在其地址空间中的修改都不会影响到另外一个进程。
2.不同的是:在UNIX中,子进程的初始地址空间是父进程的一个副本,提示:子进程和父进程是可以有只读的共享内存区的。但是对于windows系统来说,从一开始父进程与子进程的地址空间就是不同的。
开进程的两种方式:
#windows开进程的话,进程必须放在主函数下面。
方法一
from multiprocessing import Process import time def task(name): print("%s is running" %name) time.sleep(3) print("%s is down" %name) if __name__ == '__main__': p = Process(target=task,args=('zym')) p.start() print("主") ##这里创建进程需要绑定内存空间可能需要时间。
方法二
from multiprocessing import Process import time class MyProcess(Process): def __init__(self,name): #定义自己的属性会把父类覆盖掉 super(MyProcess,self).__init__() #重用父类 self.name =name def run(self): print("%s is running" % self.name) time.sleep(3) print("%s is down" % self.name) if __name__ == '__main__': p =MyProcess('进程一') p.start() # 就是p.run() 因为是自己定义的进程,所以要自己写run函数
进程的内存空间:
就像各个部门之间的工作内容,互不干涉。
进程中的函数:
join #例如:p.join() p为实例化的一个进程对象,join的意思是执行完这个进程在执行下面的代码,
场景,让主进程等待子进程完成在行动。
僵尸进程和孤儿进程:
参考博客:http://www.cnblogs.com/Anker/p/3271773.html 一:僵尸进程(有害) 僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。详解如下 我们知道在unix/linux中,正常情况下子进程是通过父进程创建的,子进程在创建新的进程。子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程到底什么时候结束,如果子进程一结束就立刻回收其全部资源,那么在父进程内将无法获取子进程的状态信息。 因此,UNⅨ提供了一种机制可以保证父进程可以在任意时刻获取子进程结束时的状态信息: 1、在每个进程退出的时候,内核释放该进程所有的资源,包括打开的文件,占用的内存等。但是仍然为其保留一定的信息(包括进程号the process ID,退出状态the termination status of the process,运行时间the amount of CPU time taken by the process等) 2、直到父进程通过wait / waitpid来取时才释放. 但这样就导致了问题,如果进程不调用wait / waitpid的话,那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵死进程,将因为没有可用的进程号而导致系统不能产生新的进程. 此即为僵尸进程的危害,应当避免。 任何一个子进程(init除外)在exit()之后,并非马上就消失掉,而是留下一个称为僵尸进程(Zombie)的数据结构,等待父进程处理。这是每个子进程在结束时都要经过的阶段。如果子进程在exit()之后,父进程没有来得及处理,这时用ps命令就能看到子进程的状态是“Z”。如果父进程能及时 处理,可能用ps命令就来不及看到子进程的僵尸状态,但这并不等于子进程不经过僵尸状态。 如果父进程在子进程结束之前退出,则子进程将由init接管。init将会以父进程的身份对僵尸状态的子进程进行处理。 二:孤儿进程(无害) 孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。 孤儿进程是没有父进程的进程,孤儿进程这个重任就落到了init进程身上,init进程就好像是一个民政局,专门负责处理孤儿进程的善后工作。每当出现一个孤儿进程的时候,内核就把孤 儿进程的父进程设置为init,而init进程会循环地wait()它的已经退出的子进程。这样,当一个孤儿进程凄凉地结束了其生命周期的时候,init进程就会代表党和政府出面处理它的一切善后工作。因此孤儿进程并不会有什么危害。 我们来测试一下(创建完子进程后,主进程所在的这个脚本就退出了,当父进程先于子进程结束时,子进程会被init收养,成为孤儿进程,而非僵尸进程),文件内容 import os import sys import time pid = os.getpid() ppid = os.getppid() print 'im father', 'pid', pid, 'ppid', ppid pid = os.fork() #执行pid=os.fork()则会生成一个子进程 #返回值pid有两种值: # 如果返回的pid值为0,表示在子进程当中 # 如果返回的pid值>0,表示在父进程当中 if pid > 0: print 'father died..' sys.exit(0) # 保证主线程退出完毕 time.sleep(1) print 'im child', os.getpid(), os.getppid() 执行文件,输出结果: im father pid 32515 ppid 32015 father died.. im child 32516 1 看,子进程已经被pid为1的init进程接收了,所以僵尸进程在这种情况下是不存在的,存在只有孤儿进程而已,孤儿进程声明周期结束自然会被init来销毁。 三:僵尸进程危害场景: 例如有个进程,它定期的产 生一个子进程,这个子进程需要做的事情很少,做完它该做的事情之后就退出了,因此这个子进程的生命周期很短,但是,父进程只管生成新的子进程,至于子进程 退出之后的事情,则一概不闻不问,这样,系统运行上一段时间之后,系统中就会存在很多的僵死进程,倘若用ps命令查看的话,就会看到很多状态为Z的进程。 严格地来说,僵死进程并不是问题的根源,罪魁祸首是产生出大量僵死进程的那个父进程。因此,当我们寻求如何消灭系统中大量的僵死进程时,答案就是把产生大 量僵死进程的那个元凶枪毙掉(也就是通过kill发送SIGTERM或者SIGKILL信号啦)。枪毙了元凶进程之后,它产生的僵死进程就变成了孤儿进 程,这些孤儿进程会被init进程接管,init进程会wait()这些孤儿进程,释放它们占用的系统进程表中的资源,这样,这些已经僵死的孤儿进程 就能瞑目而去了。 四:测试 #1、产生僵尸进程的程序test.py内容如下 #coding:utf-8 from multiprocessing import Process import time,os def run(): print('子',os.getpid()) if __name__ == '__main__': p=Process(target=run) p.start() print('主',os.getpid()) time.sleep(1000) #2、在unix或linux系统上执行 [root@vm172-31-0-19 ~]# python3 test.py & [1] 18652 [root@vm172-31-0-19 ~]# 主 18652 子 18653 [root@vm172-31-0-19 ~]# ps aux |grep Z USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 18653 0.0 0.0 0 0 pts/0 Z 20:02 0:00 [python3] <defunct> #出现僵尸进程 root 18656 0.0 0.0 112648 952 pts/0 S+ 20:02 0:00 grep --color=auto Z [root@vm172-31-0-19 ~]# top #执行top命令发现1zombie top - 20:03:42 up 31 min, 3 users, load average: 0.01, 0.06, 0.12 Tasks: 93 total, 2 running, 90 sleeping, 0 stopped, 1 zombie %Cpu(s): 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 1016884 total, 97184 free, 70848 used, 848852 buff/cache KiB Swap: 0 total, 0 free, 0 used. 782540 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND root 20 0 29788 1256 988 S 0.3 0.1 0:01.50 elfin #3、 等待父进程正常结束后会调用wait/waitpid去回收僵尸进程 但如果父进程是一个死循环,永远不会结束,那么该僵尸进程就会一直存在,僵尸进程过多,就是有害的 解决方法一:杀死父进程 解决方法二:对开启的子进程应该记得使用join,join会回收僵尸进程 参考python2源码注释 class Process(object): def join(self, timeout=None): ''' Wait until child process terminates ''' assert self._parent_pid == os.getpid(), 'can only join a child process' assert self._popen is not None, 'can only join a started process' res = self._popen.wait(timeout) if res is not None: _current_process._children.discard(self) join方法中调用了wait,告诉系统释放僵尸进程。discard为从自己的children中剔除 解决方法三:http://blog.csdn.net/u010571844/article/details/50419798
守护进程:
当你的子进程伴随主进程的全部生命周期,主进程死了(主进程代码运行完毕),子进程没必要存在了,这时可以设置为守护进程。
在p.start()之前加上p.daemon = True,p即为守护进程 !!!但是守护进程中无法在开子进程。
互斥锁:
from multiprocessing import Process,Lock import json import random import time def look(): time.sleep(random.randint(1,3)) #模拟网络延迟 dic = json.load(open("db.txt",'r',encoding='utf-8')) #json 文件内容 {"count": 0} print("剩下的票数是 %s" %dic["count"]) def buy(lock): lock.acquire() dic = json.load(open("db.txt", 'r', encoding='utf-8')) if dic['count'] >= 1: dic['count'] -=1 time.sleep(random.randint(1, 3)) json.dump(dic,open("db.txt", 'w', encoding='utf-8')) print("购票成功") else:print("购票失败") lock.release() def task(lock): look() buy(lock) if __name__ == '__main__': lock = Lock() for p in range(4): #用for循环开启, p=Process(target=task,args=(lock,)) p.start() #目的查票同时进行,改票只能一个用户进行。 #互斥锁只能acquire一次,再次使用的话只能现释放在使用。 #使用时当做参数传进去。 # 互斥锁的使用,可以在函数里面用,需要的代码加锁,也可以对整个函数使用。
递归锁:
#死锁现象,就是两个线程之间互相把对方锁在外边了。
#递归锁,创建一个递归锁,之后每使用这把锁,这个锁的计数就会加一,可以连续acquire,只要递归锁的计数不为0,其他人都抢不到这把锁。
#只有进程将这个锁的计数全部释放,这把锁才能再次被线程争抢(包括他自己)
from threading import Thread,RLock
(Lock为正常锁,Rlock为递归锁用法一致)
mutexA = Lock()#创建锁
mutexA = Rlock()#创建递归锁
mutexA.acpuire()#加锁
mutexA.release()#释放
信号量:
另一种形式的锁,例如设置信号量为5,即有5个钥匙,拿到钥匙才能进门,出门时再将钥匙放在门前,由其他人去拿。
from threading import Thread,Semaphore,current_thread sm = Semaphore(5) #设置信号量为5 import time import random def task(): with sm: print("%s is laing " %current_thread().getName())#线程的名字 time.sleep(random.randint(1,3)) #模拟网络延迟 if __name__ == '__main__': for i in range(20): #起20个线程 t = Thread(target=task,) t.start()
Event事件:
同进程的一样
线程的一个关键特性是每个线程都是独立运行且状态不可预测。如果程序中的其 他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就会变得非常 棘手。为了解决这些问题,我们需要使用threading库中的Event对象。 对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在 初始情况下,Event对象中的信 号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设 置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行
event.isSet():返回event的状态值; event.wait():如果 event.isSet()==False将阻塞线程; event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度; event.clear():恢复event的状态值为False。
from threading import Thread,Event,current_thread import time def mysql_check(): print('�33[45m[%s]正在检查mysql�33[0m' % current_thread().getName()) time.sleep(5) event.set() def mysql_connect(): count = 1 while not event.is_set(): if count > 3 : raise TimeoutError('连接超时') event.wait(2) #wait后面的2 * count的值大于sleep中的5才能接收到event设置的值 print("%s 尝试重新链接 ,time %s"%(current_thread().getName(),count)) count += 1 print("succes") if __name__ == '__main__': event =Event() #实例化 t1 = Thread(target=mysql_check,) t2 = Thread(target=mysql_connect,) t3 = Thread(target=mysql_connect,) t4 = Thread(target=mysql_connect,) t1.start() t2.start() t3.start() t4.start()
定时器:
指定多长时间后执行
from threading import Timer def fanc(name): print("%s is aaaaa" % name) t = Timer(3,fanc,args=('zym',)) #args后面是参数,需要加括号(就是一个元组,传参数时注意顺序) t.start() #如果在固定点运行需要在前端的定时器,这个实现不了
线程之间的通信:
推荐使用队列,因为可以不用考虑锁的问题。
进程队列,线程队列(耦合度高,性能问题,损坏的问题) 所以一般用单独的一台或者集群来使用队列软件,例如rabbitmq集群
import queue q=queue.Queue(3) #队列:先进先出 q.put(1) q.put(2) q.put(3) q.get() #加上这个 ,q.put(4,block=True,timeout=3)将不会报错 # q.put(4) # q.put_nowait(4) # q.put(4,block=False) q.put(4,block=True,timeout=3) #先取出一个,然后再放入,否则会报错 # print(q.get()) # print(q.get()) # print(q.get()) q=queue.LifoQueue(3) #堆栈:后进先出 q.put(1) q.put(2) q.put(3) print(q.get()) print(q.get()) print(q.get()) q=queue.PriorityQueue(3) #优先级队列,vip类型,传值类表或元组,数字越小,优先级越高 q.put((10,'a')) q.put((-3,'b')) q.put((100,'c')) print(q.get()) print(q.get()) print(q.get())
进程池:
#进程池 #提交任务的两种方式: #同步调用:提交完任务后就在原地等待,拿到任务的返回值,才能继续下一行代码,导致程序串行执行 #异步调用:提交完任务后,不在原地等待,结果?程序是并发执行的,一般与回调机制一块使用 #进程的执行状态: #阻塞 #非阻塞 from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor import os import time import random def task(n): print('%s is runing ' %os.getpid() ) time.sleep(random.randint(1,3)) return n**2 def handle(res): res = res.result() print('handle res %s' %res) if __name__ == '__main__': pool = ProcessPoolExecutor(4) #不指定,默认为cpu的盒数,一般超过cpu盒数的两倍,从始到总就是这4个进程在干活。 for i in range(13): obj = pool.submit(task,i) #提交的进程池,i即传入的参数,submit是异步 obj.add_done_callback(handle) #回调机制,触发handle,回调的是个对象,然后使用 result()取出结果 pool.shutdown(wait=True) #相当于join,(关门,不能再向池子里丢任务了),wait =TRUE,就是在进程池里的任务全部跑完,挨个取出,执行join操作(默认即为True)。 print('主')
线程池:
与进程池用法一致。默认池子线程是核心数的5倍。
区别包的名字有所不同
pool = ThreadPoolExecutor()
协程:
协程:是单线程下的并发,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。、
需要强调的是:
#1. python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行)
#2. 单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关)
对比操作系统控制线程的切换,用户在单线程内控制协程的切换
优点如下:
#1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级
#2. 单线程内就可以实现并发的效果,最大限度地利用cpu
缺点如下:
#1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程
#2. 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
比如nginx就是利用协程的方法实现轻量级的并发。
协程的使用:(遇到io在进行切换)
使用一:
from gevent import monkey;monkey.patch_all() ##打一个补丁,让gevent模块识别其他的io操,将阻塞变为非阻塞,让gevent来帮助切换 import gevent import time def eat(name): print('%s eat 1' %name) # gevent.sleep(3) time.sleep(3) print('%s eat 2' %name) def play(name): print('%s play 1' % name) # gevent.sleep(2) time.sleep(3) print('%s play 2' % name) g1=gevent.spawn(eat,'egon') #提交任务异步 g2=gevent.spawn(play,'alex') # gevent.sleep(1) # g1.join() # g2.join() gevent.joinall([g1,g2]) #让线程不要死掉否则看不到结果
使用二:
利用套接字来实现,server端采用一个线程,使用gevent模块。使用协程,因为在套接字建立连接,收发消息的时候会有阻塞的情况。所以可以采用协程的方式。
import socket from gevent import monkey,spawn;monkey.patch_all() #打补丁,识别其他的io操作 def accept(): server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server.bind(('127.0.0.1', 8083)) server.listen(5) while True: conn,addr = server.accept() # print('from addr is %s' %str(addr)) spawn(send,conn) #提交任务 def send(conn): while True: data = conn.recv(1024) conn.send(data.upper()) if __name__ == '__main__': g = spawn(accept,) #实例化一个对象 g.join() #防止进程死亡
import socket from threading import Thread,current_thread,Thread def client(): client = socket.socket(socket.AF_INET,socket.SOCK_STREAM) client.connect(('127.0.0.1', 8083)) while True: client.send(('%s is in connecting' % current_thread().getName()).encode('utf-8')) data = client.recv(1024) print(data.decode('utf-8')) client.close() if __name__ == '__main__': for i in range(10): t = Thread(target=client) t.start()