因为工作中历史产品采用了terracotta作为分布式缓存线性扩展平台,因此不得不提前对其原理做了相关了解,当然其中很多的设计思想和oracle、memcached的设计相似,但也有自己的亮点,那就是JVM的懒加载细粒度拷贝以及线性扩展,使得序列化对象消耗大大降低,提高CPU使用率以及内存无缝线性扩展。
我在研究terracotta的时候,没有急于去尝试环境搭建以及demo实现,首先我去了解了一下为什么之前产品为什么会选型使用它、它是什么、能做什么、和其他相似的技术相比有什么优势,最后才做了相关的demo验证,以及相关产品中的调优,那么现在让我们来揭开它的面纱吧(文章内容从官方、网络、公司资源库整理而来)!
Terracotta是什么
Terracotta是一种分布式java集群技术,它巧妙得隐藏了多个分布式JVM带来的复杂性,使得java对象能够透明得在多个JVM集群中进行分享和同步,并能够进行持久化。从某种意义上讲它类似于hadoop中的zookeeper,可以作为zookeeper之外的另外一种选择。
Terracotta采用的是一种被称之为中心辐射的架构。在这种架构里运行着分布式应用程序的JVM们在启动时都会与一台中心Terracotta服务器相连。Terracotta服务器负责存储DSO对象数据,协调JVM之间的并发线程。Terracotta库位于应用程序JVM中,在类加载过程中,它们用来对类的字节码进行增强,处理同步块内的lock和unlock请求,处理应用JVM之间的wait(),notify()请求,处理运行时和Terracotta服务器的联系等等
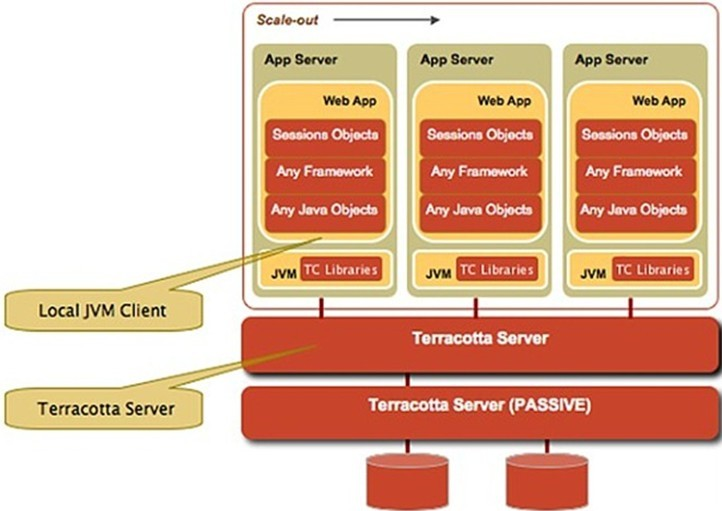
terracotta能做什么
是一个JVM级的开源群集框架,它最重要的一个功能就是DSO(Distributed Shared Object),通过DSO我们可以把那些被频繁访问的,重要的数据缓存在TC Server上,然后供集群里的不同JVM共享,这样减轻了数据库的负载,它同时还提供:HTTP Session复制,spring security整合、与Hibernate整合,分布式缓存(收购了java开源缓存项目Ehcache以及Java任务调度项目Quartz,并对其做了深度整合),POJO群集(比如spring框架中引入terracotta,那么spring中的bean就可以分布式集群了。bean被分布式了,那么我们可以无缝得扩展我们的web系统,我们的web系统也天然得有了故障转移机制),跨越群集的JVM来实现分布式应用程序协调(采用代码注入的方式,所以你不需要修改任何),同时TC Server本身也可以配置成集群的形式,宕机的TC Server中的活动自动而无缝地转移到集群里的及其他TC Server上去
为什么要选择terracotta
Terracotta是一个可以在不改变任何现有系统代码的基础上提供HA和HP的一个优秀解决方案,与其他集群相比:
1、 由于大多数Web应用服务器都采用Java序列化和数据广播方式实现session数据的共享,导致任何一个节点对任何session数据进行修改,都造成大量的内存、CPU以及网络带宽的消耗。这种消耗随着应用服务器节点的增加而成级数级增长。当节点数目超过4个以上的时候,经常由于session复制导致的消耗过高,使得整个集群的吞吐量反而开始下降。由于普通session复制机制性能和可用性的缺陷,很多web开发人员不得不通过数据保存和共享session相关的数据,因此又增加了对数据库的压力,形成新的性能瓶颈,Terracotta集群实现sessino数据的共享。不使用广播机制,避免了Java序列化,只把被修改的字段的数据传递给服务器和使用节点,大大减少CPU和内存消耗
2、 利用服务器实现网络扩展内存,使得有限内存的客户端节点可以访问远大于其内存容量的数据结构,而不必担心发生内存溢出的异常
3、 数据保存在服务器端,因此客户端JVM宕机不会造成数据丢失
4、 增量数据传递,智能数据推送,最大限度减少对网络的负担,使得客户端JVM可以横向扩展
5、 服务器分片,实现服务器数据存储及数据吞吐量横向扩展
6、 通过服务器实现共享数据持久化,通过服务器集群实现容错等
7、 无需学习新的API,大大降低开发成本
8、 广泛支持各种应用服务器:WebLogic, WebSphere, Tomcat, JBoss, Jetty, Geronimo等等,自动session数据迁移,集群范围内数据可视以及强大的管理和监控功能界面,大大方便对整合集群的共享数据、性能数据、软硬件指标等的实施监控、调试、优化(通过JMX开放服务器监控信息)
9、 企业版的Terracotta服务器还提供了数据分片功能,使得集群吞吐量随着服务器数量的增加达到线性增长
上述应该能够清楚的知道它是什么、做什么用了,那么下面我们就来通过简单的原理设计思想来提高自己设计的能力,我们应该如何做才能使其优势最大化
注入与字节码
普通的应用程序是怎么获得这种分布式的集群行为呢?当应用程序类在被JVM加载的时候,它们通过字节码增强技术被偷偷注入了分布式集群行为(通过配置文件配置后获得)。这种字节码增强注入技术其实很常用,在很多AOP框架中都得以采用,比如AspectJ和AspectWerkz。类的字节码在加载的时候由Terracotta库进行解析和检查。然后这些字节码会被传递到JVM重新构造成一个类,在此之前这些字节码会根据配置被修改。
为了维护对象的修改,PUTFIELD和GETFIELD字节指令被进行了重载。PUTFIELD指令被替换了,能够存储对一个分布式对象的各个域的修改。GETFILED字节指令重载后能够在需要的时候从服务器获取对象的域数据,但这么做的前提是此时它还没有从服务器的查询中获取到被这个域所引用的对象,此时该域引用的对象还没有在JVM堆中被实例化。也就是说GETFIELD是一个lazy initialize模式,如果域为空才会加载域数据,否则不会加载。
为了管理线程之间的协调,MONITORENTER和MONITOREXIT字节码指令也被重载了,INVOKEVIRTUAL指令也会被重载,这些指令会被各种各样的object.wait()和objecti.notify()方法用到。MONITORENTER意味着某一个线程对某一个对象monitor的请求。一个线程会阻塞在这条指令上,直到它获得了对该对象的锁。一旦获得了锁,那么线程就会持有该对象的排他锁,直至针对该对象的MONITOREXIT指令被执行。如果在MONITORENTER请求查询monitor的时候这个对象碰巧是一个集群对象-DSO,Terracotta会保证:除了请求这个对象在本地JVM里的本地锁之外,线程还会在这个DSO对象上的整个JVM集群上的排他锁,在此之前,该线程会一直阻塞。当线程释放本地JVM上对该DSO对象的本地锁的时候,他也会释放相应的整个JVM集群上的锁。
在Terracotta的应用程序中,所有的synchronized方法和synchronized块往往会被被配置成“autolocking”(我们可以看到在测试的例子中运用到了synchronized,配置文件中对其进行”autolocking”配置:


),这就意味着MONITORENTER和MONITOREXIT方法被进行了字节码增强处理。当然有些开发人员可能不太愿意用显式的synchronized关键字,那么可以在Terracotta配置文件中声明一个方法为一个locked方法,从而使得应用程序获得集群同步特性(如上图配置)。
对象wait()和notify()方法相应的字节码指令也会被进行字节码增强。当某一个共享对象的wait()方法被调用时,terracotta服务器会把调用这个wait()方法的线程加入到一个线程队列中去,这个线程队列记录了整个JVM集群中所有等待该对象锁的所有线程。当这个对象的notify方法被调用时,服务器会确保整个集群中所有阻塞在该对象上的线程会被通知到。一旦该对象的notify在一个JVM中被调用时,terracotta服务器会选择一个阻塞在该对象上的线程,然后唤醒通知它。当notifyAll被调用时,terracotta服务器会让所有JVM中等待在该DSO上的所有线程都被唤醒。
ROOT、集群对象图
集群对象从一个共享对象图中的根开始,这个root可以通过Terracotta配置文件中的一个或多个域进行配置的,当一个root被首先实例化时,这个root对象和这个root所能到达的所有的对象就变成了集群对象:

他们的各个域的数据会被传递到服务器上由服务器来存储,在任何JVM中一旦一个root对象被创建,那么该root对象创建时所对应的那个域就会忽略本地堆对象的分配,取而代之的是分配一个服务器集群对象。这种情况往往发生在第二个应用程序实例创建root对象的时刻,由于root对象已经由第一个应用程序实例化创建了,那么其他应用程序中的,尽管这些root域按照代码的要求是要通过构造函数来生成对象的,但这些指令都被忽略了,取而代之的是,Terracotta客户端库会从服务器获取root对象,然后在本地堆中实例化它,然后把这个引用赋给相应的域,这些工作都是透明得进行的,被terracotta的库隐藏了。terracotta的工作机制给我们的应用程序带来的最主要也是最有价值的地方也就在于此。一旦某一个对象变成集群对象了,那么他就会被分配一个整个集群范围内唯一的object id,并且在剩下的生命周期内一直保持集群特性。一旦某一个集群对象突然变成了任何root对象都不可达的状态,并且在整个集群JVM中都没有它的任何实例,那么这个集群对象会被terracotta的服务器GC进行回收。
细粒度的更改复制
包含DSO对象变化的transaction只包含那些已经发生变化的域的数据。这些transaction会被发送到Terracotta服务器和其他集群JVM上从而保持集群一致性。服务器不是广播式的将transaction发送到所有其它的JVM上,这些transaction只会被发送到特定的JVM上,这些JVM包含transaction代表的对象,并且这些对象在这些JVM的堆上进行了实例化。也就是说,terracotta服务器只发送其它JVM必须使用到的transaction的一部分。比如:一个线程改变了对象a中的域p和对象b中的域q,那么只有a.p和b.q的域数据会被放到transaction中并被发送到服务器。更改某个DSO的多个相关的域在terracotta中一定是原子的,一定是要用synchronized关键字进行同步的,根据前面的定义,那么更改DSO的这些域也就是transaction,被发送到服务器上。(只更改某个DSO的单个域本身就是原子的,不需要用synchronized进行显式同步,也就是说某个DSO单个域的修改本身就是一个transaction)。Terracotta服务器会决定哪些JVM含有a和b的实例。如果一个JVM的本地堆只含有对象a的实例而并没有对象b的实例,那么这个JVM只会收到a.p的数据,而不会收到b.q的数据
对象的标识和序列化
由于对象的变化的历史记录只是局限在对象的域层次并且transaction只包含的是DSO的片段而不是整个对象图,因此terracotta不会使用Java序列化来复制传播对象的变化。举个例子,我们更改一个product对象的price域,那么我们需要发送到集群上就是发生变化的对象的ID,对象发生变化的域的ID,和包含price域数据的字节。Product对象的其余部分就被忽略了。如果我们采用object序列化技术,那么product对象的每个域都需要被序列化,而各个域又会引用到其它对象,这样最后的结果是仅仅是对product对象的一个double域的修改就会导致整个对象图都会被序列化,Terracotta目前采用的做法相比java序列化而言更加高效,因为它只发送了发生改变的对象而不是整个对象图。但是,除了效率,利用对象域作为改变的基本单位还有另外的好处:保持对象的唯一性,如果采用java序列化来在集群间转移对象的变化,那么JVM集群的客户端应用程序需要对发生改变的对象进行反序列化并且不得不替换已有的对象实例。这就是为什么许多其他的集群和分布式技术会要求提供PUT/GET API,因为一个集群对象从集群中被获取出来一定需要一个GET调用,当对象发生变化时,它一定需要一个PUT调用把发生改变的对象放回集群上去,Terracotta没有这样的限制。一个集群对象也像普通对象一样在JVM堆中生存着。当对象是被JVM本地进行修改的,那么这些修改直接作用在JVM的堆上。如果这些修改是通过远程的在另外一个JVM上的这个DSO对象的引用进行的,那么本地的JVM就会收到这个transaction并且直接将transaction作用在已在本地堆中存在的对象上。这意味着针对某个DSO,在任何给定的时刻一个JVM在堆中只可能拥有一个对它的实例引用。
有了terracotta,你不必考虑每个JVM实际上存放的是一个对象的copy,也不必考虑当本地进行完修改时再把对象的copy放回集群中去。由于没有对象拷贝的概念,一个集群对象就是一个在集群堆中的普通对象,行为也和普通对象没有什么区别,任何对集群对象的修改对任何拥有该集群对象引用的对象也是有效的。由于保留了对象的唯一性,这使得集群的,多JVM的应用在行为表现上和普通的,单JVM的应用没有什么区别。在集群中保持对象唯一性带来的简洁和强大使得分布式特性从应用程序的设计和实施中剥离出来。分布式行为被推给了terracotta服务器,已经融入了基础架构。就像Java的GC使得内存管理的代码从应用层代码中完全消失了,terracotta使得分布式计算行为也从应用代码中消失。
虚拟堆/网络内存
除了在多个JVM之间分享和同步对象,Terracotta也能够针对非常大的对象图有效得使用本地堆。随着共享对象图不断增大,可能它已经不能够放在单个JVM的堆中了,Terracotta会保持一个对分布式对象图的配置窗口,这样当分布式对象对堆的使用超过一定阈值后就会按照一定的策略被flush out出去。当这些被flush out的对象片段又被使用时,再从terracotta服务器中取出来放到JVM的堆中。你可以把terracotta服务器看成一个无限大的虚拟堆或者网络内存,由于terracotta可以看成一个巨大的可以无限扩展的网络内存,你可以装进整个对象,使之成为一个分布式的对象图,而不必关心它的大小,对象只需要装载一次,这大大减小了应用程序实例的启动的时间。
Terracotta搭建:https://blog.csdn.net/lgcjava/article/details/19069523,http://topmanopensource.iteye.com/blog/1911679
转载自:http://yale.iteye.com/blog/1541612