原文链接:https://www.cnblogs.com/qcloud1001/p/7615526.html
正文
一,HBase产生背景
Hadoop只能执行批量处理,并且只以顺序方式访问数据。这意味着必须搜索整个数据集,即使是最简单的搜索工作。当处理结果在另一个庞大的数据集,也是按顺序处理一个巨大的数据集。在这一点上,一个新的解决方案,需要访问数据中的任何点(随机访问)单元。对于随机访问数据单元的数据库种类有多种如:HBase, Cassandra, couchDB, Dynamo 和 MongoDB 都是一些存储大量数据和以随机方式访问数据的数据库。而HBase是建立在Hadoop文件系统上的分布式面向列的数据库。
二,HBase是什么
HBase:是建立在Hadoop文件系统上的分布式面向列的数据库。它可以提供快速随机访问海量结构化数据的能力,同时由于利用了Hadoop的HDFS文件系统,从而提高了容错能力。使用者可以直接通过Hbase存储的HDFS数据,来使用Hbase在HDFS中随机访问数据。
HBase 是 BigTable 的开源(源码使用 Java 编写)版本。是 Apache Hadoop 的数据库,是建 立在 HDFS 之上,被设计用来提供高可靠性、高性能、列存储、可伸缩、多版本的 NoSQL 的分布式数据存储系统,实现对大型数据的实时、随机的读写访问。
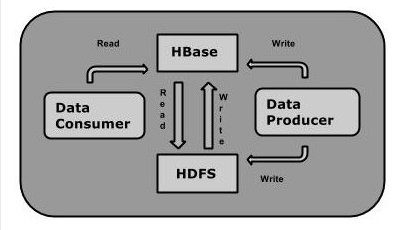
HBase 依赖于 HDFS 做底层的数据存储。
HBase 依赖于 MapReduce 做数据计算。
HBase 依赖于 ZooKeeper 做服务协调。
如下图:
三,HBase简介
3.1 HBase的特点
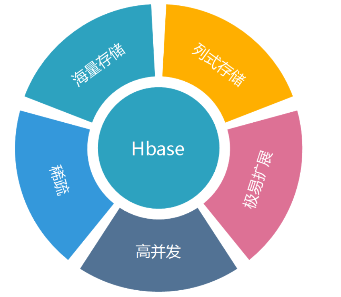
1),海量存储:Hbase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与Hbase的极易扩展性息息相关。正式因为Hbase良好的扩展性,才为海量数据的存储提供了便利。(数据存储在HDFS)
2),列式存储:这里的列式存储其实说的是列族存储,Hbase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。
3),Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。通过横向添加RegionSever的机器,进行水平扩展,提升Hbase上层的处理能力,提升Hbsae服务更多Region的能力。
备注:RegionServer的作用是管理region、承接业务的访问,这个后面会详细的介绍通过横向添加Datanode的机器,进行存储层扩容,提升Hbase的数据存储能力和提升后端存储的读写能力。
4),由于目前大部分使用Hbase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,Hbase的单个IO延迟下降并不多。能获得高并发、低延迟的服务。
5),稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
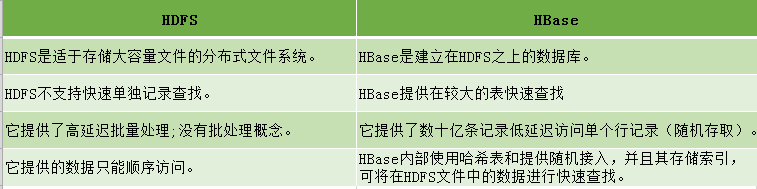
3.2 HBase和HDFS的关系
HDFS为Hbase提供最终的底层数据存储服务,同时为Hbase提供高可用(Hlog存储在HDFS)的支持,具体功能概括如下:提供元数据和表数据的底层分布式存储服务数据多副本,保证的高可靠和高可用性
HDFS和HBase的区别如下:
3.3 HBase与RDBMS的关系
HBase是一个NoSQL,即非关系型数据库。常见的NoSQL有:hbase, redis, mongodb,关系型数据库有RDBMS:mysql,oracle,sql server,db2。

四,HBase重要名词
学习HBase有几个重要的名词需要我们详细说明,如下所示是一个简单的数据表:

4.1 Column Family
Column Family又叫列族,Hbase通过列族划分数据的存储,列族下面可以包含任意多的列,实现灵活的数据存取。刚接触的时候,理解起来有点吃力。我想到了一个非常类似的概念,理解起来就非常容易了。那就是家族的概念,我们知道一个家族是由于很多个的家庭组成的。列族也类似,列族是由一个一个的列组成(任意多)。
Hbase表的创建的时候就必须指定列族。就像关系型数据库创建的时候必须指定具体的列是一样的。
Hbase的列族不是越多越好,官方推荐的是列族最好小于或者等于3。我们使用的场景一般是1个列族。
4.2 Colmn
列,可理解成MySQL列。
4.3 Rowkey
Rowkey的概念和mysql中的主键是完全一样的,Hbase使用Rowkey来唯一的区分某一行的数据。
由于Hbase只支持3中查询方式:
1),基于Rowkey的单行查询
2),基于Rowkey的范围扫描
3),全表扫描
因此,Rowkey对Hbase的性能影响非常大,Rowkey的设计就显得尤为的重要。设计的时候要兼顾基于Rowkey的单行查询也要键入Rowkey的范围扫描。具体Rowkey要如何设计后续会整理相关的文章做进一步的描述。这里大家只要有一个概念就是Rowkey的设计极为重要。
4.4 Region
Region的概念和关系型数据库的分区或者分片差不多。
Hbase会将一个大表的数据基于Rowkey的不同范围分配到不通的Region中,每个Region负责一定范围的数据访问和存储。这样即使是一张巨大的表,由于被切割到不通的region,访问起来的时延也很低。
4.5 TimeStamp
TimeStamp对Hbase来说至关重要,因为它是实现Hbase多版本的关键。在Hbase中使用不同的timestame来标识相同rowkey行对应的不通版本的数据。
在写入数据的时候,如果用户没有指定对应的timestamp,Hbase会自动添加一个timestamp,timestamp和服务器时间保持一致。
在Hbase中,相同rowkey的数据按照timestamp倒序排列。默认查询的是最新的版本,用户可同指定timestamp的值来读取旧版本的数据。