[技术博客]数据库的评测与选择
我们以及许多其他项目组都使用了Django作为后端,而采用的数据库却有SQLite3, MySQL, PostgreSQL等多种。在alpha阶段尾声时,我们遭受了一次攻击,在回档时我们发现了SQLite3有一些不方便。所以我们打算在beta从SQLite3上切换到其他数据库,因此打算考察一下数据库的性能。网上现有的评测大多是基于SQL代码直接测试的,例如这个,而我们在实践中主要用的是Django封装的模型,还是有所差别的,因此我们自己进行了一次测试。我们的测试不是十分完善,仅供参考。
三种数据库都有什么优势和坑
测试之前我们先上网调研了一下三种数据库的优势与劣势,可以参考这里。
SQLite3
优势
- 非常轻量级
- 小数据量时性能高
- 内存占用少
- Django内置,不需要什么其他配置
不足
- 并发差。(注:SQLite只支持库级锁,这意味着一写多读的模式,不能并发的执行写操作。)
- 单文件储存导致大数据时表现较差。
- 回滚等的支持较差
MySQL
优势
- 用的人多,教程多
- 性能还行
- 出错时回滚较好
不足
- 坑比较多
- 大坑UTF-8,网上的教程大多数都有这个问题,与实际的UTF-8并不兼容,需要切换UTF8bm4。表现是不支持emoji和部分生僻字。(参考友商网页不能在评论中打emoji,也不能显示)
- text要手动区分 small text, middle text, large text,不支持json,array等类型储存
- 内置的是悲观锁
PostgreSQL
优势
- 稳定
- 支持json,jsonb,array,图等数据的存储和索引
- text内置支持无限长度
- 高负载,大数据量下性能依然很好
不足
- 比较小众(但是用的公司其实不少)
- 教程可能比较少
测试用服务器
在进行测试之前,我们先介绍一下服务器。服务器使用的是华为云赞助的服务器,现在作为课程设计网站的测试环境之一。服务器硬件性能稳定,配置如下:
Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz *1
1G 内存
2G swap
50G 硬盘
其中我们比较关心的是硬盘性能。4k读写性能对于数据库性能有较大的影响,在机械硬盘,消费级固态和企业级固态上同一个数据库甚至有数个数量级的性能差距。我们用了dd命令来测试硬盘性能,这两条大致测试了顺序读写和4K性能。
dd if=/dev/zero of=test.dbf bs=500M count=2 oflag=dsync
dd if=/dev/zero of=test.dbf bs=4k count=20000 oflag=dsync
结果如下:


免费的服务器要什么自行车,能用就行。
虽然硬盘性能一般,但是三者的测试环境一致,还是能较公平的展示效果的。
测试内容
我们对三个选手进行了增删改查这四项数据库常规操作测试。测试代码完全相同,每组测试唯一的区别是在settings.py中指定的数据库不一样。由于我们的主要目的是测试在Django模型层的性能差距,因此对于其他方面有所忽视,我们对于并发上的测试较薄弱,另外跨表查询也没有做,测试还是比较水的。主要代码如下:
def test(request):
times = []
a=time.time()
t=10000 # 还测试了100000
b=list(range(t))
random.shuffle(b)
for i in range(t): # 增
c=Test(con=i) # Test为目标测试数据模型
c.save()
times.append(time.time()-a)
a=time.time()
for i in b: # 查
c=Test.objects.get(con=i)
times.append(time.time()-a)
a=time.time()
for i in b: # 查+改
c=Test.objects.get(con=i)
c.con=-c.con
c.save()
times.append(time.time()-a)
a=time.time()
for i in b: # 删
c=Test.objects.get(con=-i)
c.delete()
times.append(time.time()-a)
saveToFile(times)
settings.py
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
# 在测试时只更换ENGINE为下面两个,不改其他代码
'ENGINE': 'django.db.backends.mysql',
'ENGINE':'django.db.backends.postgresql_psycopg2',
}
}
测试结果
我们测了10000组4项操作和100000组操作的执行时间,单位为秒,越短越好。
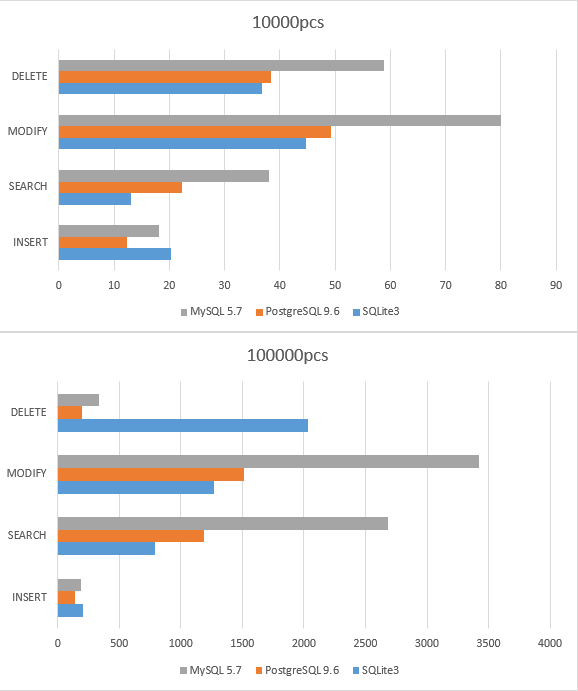
可以看到:
- SQLite3 在小数据时的确是最快的
- MySQL 基本可以说是垫底了
- PG在较大数据量时优化比MySQL好得多,性能一直和SQLite3较接近
- MySQL和PG在增删上表现更好,可能是结构上的优势。
结论
一张万年老图可以说明问题

就结论上来说,虽然MySQL看上去大比分落后,其实选的啥都行。主要原因是我们网站规模较小,实际差别不大。我们的网站可能最终也不会超过50000条数据。
就我们项目而言,目前采取的是定时备份+SQLite3。考虑到各个数据库的坑以及回滚等的需求,我们打算迁移到PG上,但是优先级较低,不是迫切的需求。