zookeeper
# 为什么要用zookeeper
像公司当中就是将单体应用架构进行拆分,拆分成一个一个个服务,然后部署在不同服务器中,这个叫分布式架构
# 官网:https://zookeeper.apache.org/
zoopeeper是一个开源的分布式协调服务,提供分布式数据一致性解决方案,分布式应用程序可以实现数据发布订阅,负载均衡,命名服务,集群管理分布式锁,分布式队列等功能。
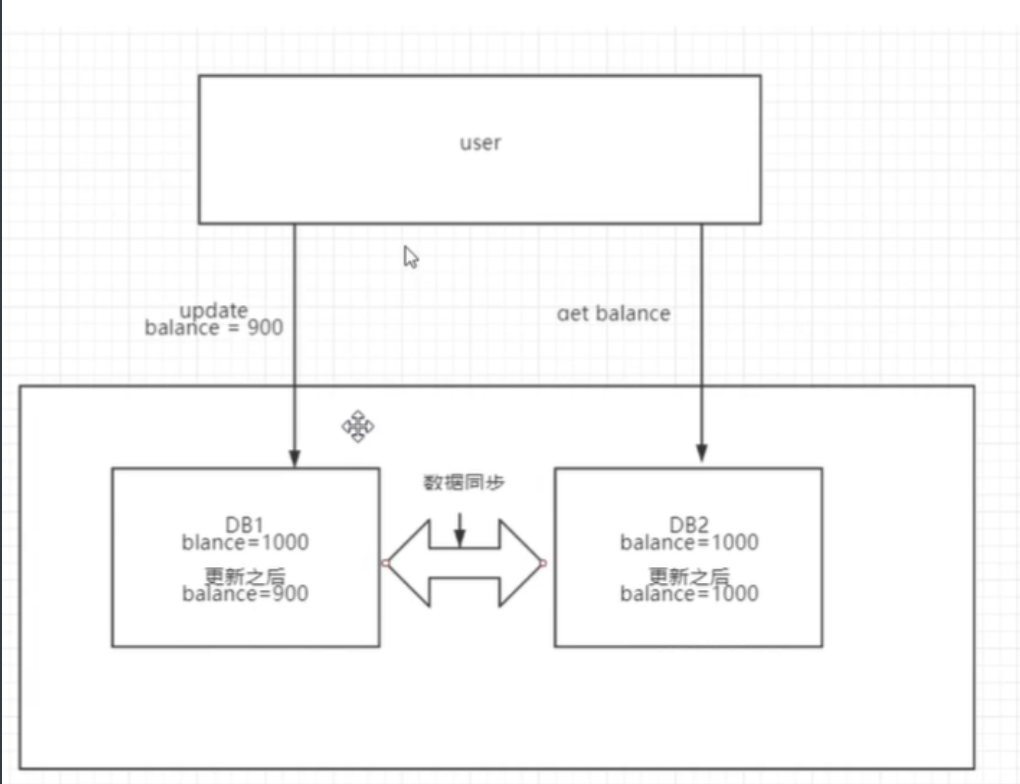
数据一致性
# zookeeper提供了分布式数据一致性解决方案,那什么是分布式数据一致性呢,首先我们谈谈什么叫一致性?
强一致性:指的是如果数据不一致,就不对外提供数据服务,保证用户读取数据始终一致,借助锁机制
最终一致性:要求最终同步,不用实时同步
cap原则
cap在分布式系统中指的是一致性,可用性和分区容错性
- 一致性:
一致性指的是强一致性
- 可用性
系统提供的服务一直处于可用状态,用户的操作请求在指定的响应时间内请求响应,超出时间范围,认为系统不可用
- 分区容错性
分布式系统在遇到任何网络分区故障的时候,分需要能保证对外提供一致性和可用性服务,除非是整个网络都发生故障
在一个分布式系统中不可能同时满足一致性,可用性,分区容错性,最多满足两个,对于分布式互联网应用而言,必须保证p,所以要么满足AP模型,要么满足cp模型
一致性协议
事务需要跨多个分布式节点时,为了保证事务的ACID特性,需要选举出来一个协调分布式各个节点的调度,基于这个思想衍生了多重一致性协议
二阶段提交
事务提交过程分为两个阶段
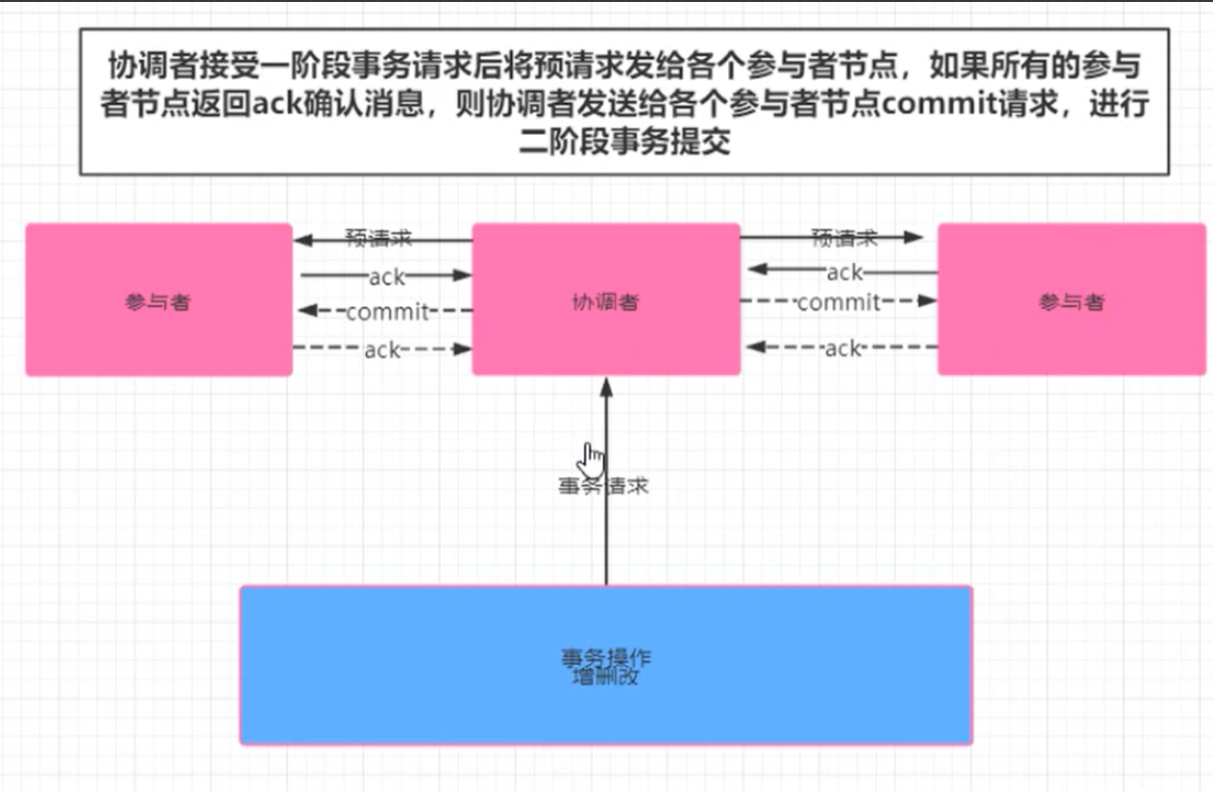
- 阶段一 提交事务请求
1. 协调者向所有的参与者节点发送事务内容,询问是否可以执行事务操作,并等待其他参与者节点的反馈。
2. 各参与者节点执行事务操作
3. 各参与者节点反馈给协调者,事务是否可以执行
- 阶段二 事务提交(需要根据参与者反馈信息执行)
根据一阶段各个参与者节点反馈的ack,如果所有参与者节点返回ack,则执行事务,否则中断事务。
事务提交:
1. 协调者向各个参与者节点发送commit请求
2. 参与者节点接受到commit请求后,执行事务的提交操作
3. 各参与者节点完成事务提交后,向协调者返送commit成功,确认消息
4. 协调者接受各个参与者节点的ack后,完成commit
中断事务:
1. 有部分参与者没有响应协调者ack
2. 协调者发送回滚请求
3. 各个参与者节点回滚事务
4. 反馈给协调者事务回滚结果
5. 协调者接受各个参与者节点ack后回滚事务
二阶段提交存在问题:
· 同步阻塞:
二阶段提交过程中,所有参与事务操作的节点处于同步阻塞状态,无法进行其他操作
· 单点问题:
一旦协调者出现单点故障,无法保证事务的一致性操作
· 脑裂导致数据不一致
参与者与协调者失去联系,参与者会重新选举leader,部分参与者接收到请求,部分没有,数据不一致。
三阶段提交
二阶段阶段改进版,将二阶段提交事务拆成两步,形成了cancommit,precommit,docommit三个阶段的事务一致性协议。
借助超时时间,解决二阶段出现的同步阻塞
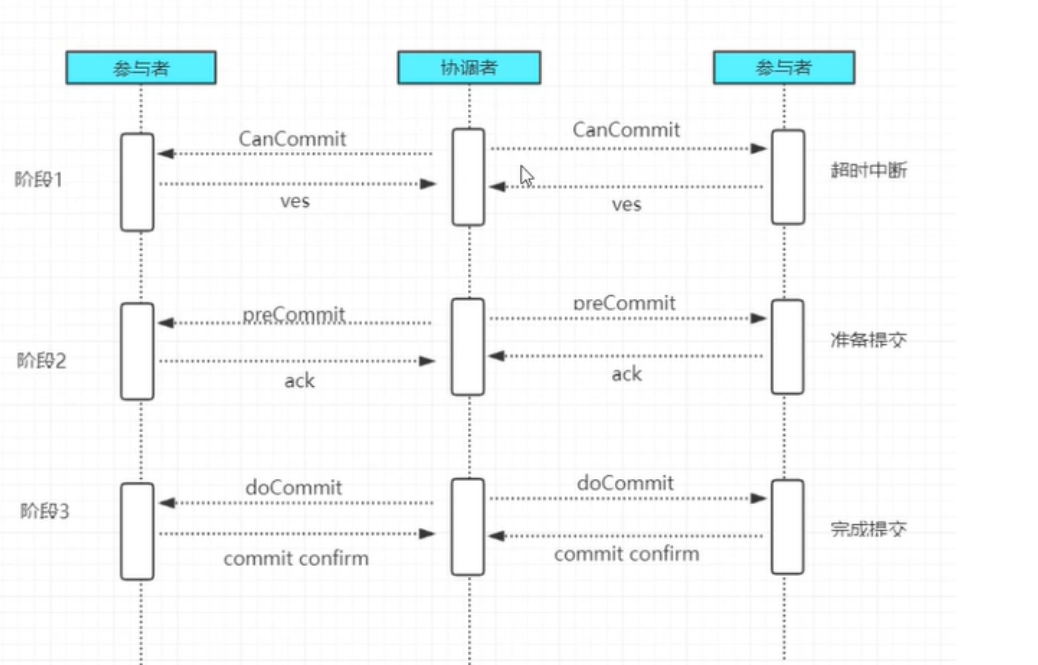
· 阶段一:Cancommit
- 事务咨询
- 各参与者节点向协调者反馈事务询问的响应
· 阶段二:Precommit
根据阶段一的反馈结果分为两种情况
- 执行事务预提交
1> 发行预提交请求
协调者向所有参与者节点发送Precommit请求,进入prepared阶段
2> 事务预提交
各参与者节点接收到Precommit请求后,执行事务操作
3> 各参与者节点向协调者反馈事务执行
中断事务
任意一个参与者节点反馈给协调者响应为no时,或者在等待超时后,协调者还未接受到参与者的反馈,就中断事务,中断事务分为两步:
1> 协调者向各参与者节点发送abort请求
2> 参与者收到abort请求后,或者等待超时时间后,中断事务
阶段三: docommit
执行提交
1> 发送提交请求
协调者向所有参与者节点发送docommit请求
2> 事务提交
各参与者节点接受到docommit请求后,执行事务操作提交
3> 反馈事务提交结果
各参与者节点完成事务提交后,向协调者发送ack
4> 事务完成
协调者接受各个参与者反馈ack后,完成事务
中断事务
1> 参与者接受到abort请求后,执行事务回滚
2> 参与者完成事务回滚后,向协调者发送ack
3> 协调者接受回滚,回滚事务
3阶段相较于2阶段,解决了协调者挂掉后参与者无限阻塞和单点问题,但是任然无法解决网络分区问题
paxos算法
基于消息传递且具有高度容错性的一种算法,是目前公认的解决分布式一致性问题最有效的算法,
# 解决问题:
在分布式系统中,如果产生宕机或者网络异常情况,快速的正确的在集群内部对某个数据的值达成一致,并且不管发生任何异常,都不会破坏整个系统的一致性
# 重要概念:
半数原则,少数服从多数
# paxos有三个版本:
· basic paxos
· multi paxos
· fast paxos
# paxos的四种角色:
1. client:产生题案者(老板)
2. proposer: 题案者(秘书)******
3. acceptor:决策者 (政府官员)******
4. learners: 学习者(不参与只关注结果)
# paxos算法的两个阶段:
· 阶段一:prepare阶段,准备阶段
· 阶段二: accept阶段,同意阶段
ZAB协议
由于paxos算法实现起来较难,存在活锁和全序问题(无法保证两次最终提交的顺序),所以zookeeper并没有使用paxos作为一致性协议,而是使用ZAB协议
ZAB:(zookeeper atomic broadcast):是一种支持崩溃恢复的原子广播协议,基于fast paxos实现。
zookeeper使用单一主进程leader用于处理客户端所有事物请求,即写请求,当服务器数据发生变更好,集群采用ZAB原子广播协议,以事物提交proposal形式广播到所有的副本进程,
每一个事物分配一个全局的递增的事务编号xid。
若客户端提交的请求为读请求时,则接受请求的节点直接根据自己保存的数据响应,若是写请求,且当前节点不是leader,那么该节点就会将请求发给leader,
leader会提案者的方式广播此写请求,如果超过半数同意写请求,则该写请求就会提交,leader会通知所有的订阅者同步数据。
zk的三种角色
为了避免zk单点问题,zk采用集群方式保证zk高可用
· leader
leader负责集群的写请求,将写请求封装成题案,分发给follower,并发起投票,只有超过半数的节点同意后才会提交改写请求
· follower
处理读请求,响应结果,转发写请求给leader,在选举leader过程中参与投票
· obsserver
observer可以理解为没有投票权的follower,主要职责是协助follower处理读请求,那么当整个zk集群读请求负载很高时,为什么不增加follower节点呢?
原因是增加follower节点会让leader在提出写请求提案时,需要半数以上的follower投票节点同意,这样会增加leader和follower通讯压力,降低写操作效率。
# zookeeper两种模式
· 恢复模式
当服务启动或领导崩溃后,zk进入恢复状态,选举leader,leader选出后,将完成leaer和其他机器的数据同步,当大多数server完成和leader的同步后,恢复模式结束
· 广播模式
一旦leader已经和多数的follower进行了状态同步后,进入广播模式,进入广播模式后,如果新加入的服务器,会自动从leader中同步数据,leader在接受客户端请求后,
会生成事务题案广播给其他机器,有超过半数以上的follower同意该题议后,再提交事务。
注意在ZAB的事务的二阶段提交后,移除了事务中断的逻辑,follower要么ack,要么放弃,leader无需等待所有的follower的ack。
# zxid
zxid是64位长度的Long类型,期中高32为表示纪元epoch,低32为表示事务表示xid,即zxid由两部分构成,epoch和xid
每个leader都具有不同的epoch值,表示一个纪元,每个新的选举开启时都会生成一个新的epoch,新的leader产生,会更新所有的zkServer的zxid和epoch,xid是一个依次递增的事务编号。
# zookeeper leader选举算法:
启动过程:
· 每一个server发出一个投票给集群中的其他节点
· 收到各个服务器的投票后,判断该投票的有效性,比如是否是本轮投票,是否是looking状态
· 处理投票,pk别人的投票和自己的投票 比较规则xid>myid取最大原则
· 统计是否超过半数的接受相同的选票
· 确认leader 改变服务器状态
· 添加新server,leader已经选举出来,只能从follower身份加入集群中
崩溃恢复过程:
· leader挂掉后,集群中其他follower会将状态从following变成looking,重新进入leader选举
· 同上启动过程
# 核心选举原则:
1.zookeeper集群中只有超过半数以上的服务器启动,集群才能正常工作
2.在集群正常工作之前,myid小的服务器会给myid大的服务器投票,持续到集群正常工作,直到选出leader
3.选择出leader之后,之前的服务器状态,要由looking改变为following,以后的服务器都是follower
# 举例选举过程:
假设现有五台服务器,组成zookeeper集群,五台服务器他们的myid分别从1-5,而且他们都是最新启动,没有历史数据,假设服务器启动从id 1-5 的顺序启动
因为一共五台服务器,只有超过半数以上,也就是最少启动三台服务器,集群才能正常工作
1. 服务器1 启动,发起一次选举,服务器1投自己一票,此时服务器1 有1票,但不够半数,选举无法完成,当前服务器1状态还是保持looking状态
2. 服务器2 启动,发起一次选举,服务器2投自己一票,因为是再次发起选举,服务器1 也会投自己一票,但在投的时候会发现,服务器2的id值比服务器1的id值大,
服务器1会更改投票,将票投个服务器2,最终服务器2 收到了投票2票,依然没有到半数,没有完成选举,服务器2 状态继续保持looking
3. 服务器3 启动,再发起一次选举,与上面过程一致,最终服务器3投自己一票,加上服务器1和服务器2投给服务器3的两票,服务器3最终收获3票,超过半数,
服务器3当选leader,服务器1和服务器2状态也从looking变成following,服务器3从looking变成leading
4. 服务器4 启动,因为服务器3的状态是leading状态,并不是真的leader,所以服务器4 启动会再次发起选举,但是服务器1 和2 变成了following,
不会再次投票,服务器4会将票投给自身,但是服务器4发现服务器3已经收到了3票,过了半数,此时,服务器4遵从半数原则,会改投给服务器3,
5. 服务器5 启动,依然会再次发起一次选举,同服务器4一样,遵从半数原则,把票投给服务器3,此时服务器3票数为5票,最终leader确定服务器3
# 消息广播算法:
一旦进入广播模式,集群中非leader节点接受到事务请求,首先会将事务请求转发给leader服务器,leader服务器为其生成对应的事务提案proposal,并发送给集群中其他节点,如果过半则事务提交
· leader接受到消息后,消息通过全局唯一的64位自增事务id,zxid标识
· leader发送给follower的提案是有序的,leader会创建一个FIFO队列,将提案顺序写入到队列中发送给follower
· follower接受到提案后,会比较提案zxid和本地事务日志最大的zxid,若提案zxid比本地事务id大,将提案记录到本地日志中,反馈ack给leader,否则拒绝
· leader接受到过半ack后,leader向所有的follower发送commit,通知每个follower执行本地事务
zookeeper环境搭建
单机环境
# 1.安装jdk
1> 上传jdk安装包解压至/usr/local/目录下,并创建软连接
[root@db01 bin]# tar xf jdk-8u241-linux-x64.tar.gz -C /usr/local
[root@db01 local]# ln -s jdk1.8.0_241 jdk1.8.0
2> 配置环境变量并重载
[root@db01 bin]# cat /etc/profile.d/jdk.sh
jdk_PATH=/usr/local/jdk1.8.0
export PATH=$jdk_PATH/bin:$PATH
[root@db01 bin]# source /etc/profile
3> 查看jdk版本信息
[root@db01 bin]# java -version
java version "1.8.0_241"
Java(TM) SE Runtime Environment (build 1.8.0_241-b07)
Java HotSpot(TM) 64-Bit Server VM (build 25.241-b07, mixed mode)
# 2.安装zookeeper
· 官方下载路径:http://mirror.bit.edu.cn/apache/zookeeper/
1> 直接wget下载
[root@db01 local]# wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.5.9/apache-zookeeper-3.5.9-bin.tar.gz
2> 解压
[root@db01 local]# tar xf apache-zookeeper-3.5.9-bin.tar.gz -C /usr/local/
3> 创建数据目录
[root@db01 tmp]# cd apache-zookeeper-3.5.9-bin/
[root@db01 apache-zookeeper-3.5.9-bin]# mkdir data
4> 修改配置文件
[root@db01 apache-zookeeper-3.5.9]# cd conf/
[root@db01 conf]# mv zoo_sample.cfg zoo.cfg
5> 修改数据目录地址,其他不变
[root@db01 conf]# cat zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/apache-zookeeper-3.5.9-data/data
clientPort=2181
6> 进入bin目录启动zookeeper
[root@db01 conf]# cd ../
[root@db01 apache-zookeeper-3.5.9-bin]# cd bin/
[root@db01 bin]# ./zkServer.sh start
7> 查看端口
[root@db01 bin]# ss -lntup|grep 2181
tcp LISTEN 0 50 :::2181 :::* users:(("java",pid=18406,fd=50))
8> 查看状态
[root@db01 bin]# ./zkServer.sh status
/usr/local/jdk1.8.0/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/apache-zookeeper-3.5.9-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: standalone # standalone代表模式为单机
集群环境
准备3台主机实现集群环境,分别为10.0.0.51/52/53
# 1.jdk环境准备
[root@db01 tmp]# tar xf jdk-8u241-linux-x64.tar.gz -C /usr/local
[root@db02 tmp]# tar xf jdk-8u241-linux-x64.tar.gz -C /usr/local
[root@db03 tmp]# tar xf jdk-8u241-linux-x64.tar.gz -C /usr/local
# 2.创建软连接
[root@db01 local]# ln -s jdk1.8.0_241 jdk1.8.0
[root@db02 local]# ln -s jdk1.8.0_241 jdk1.8.0
[root@db03 local]# ln -s jdk1.8.0_241 jdk1.8.0
# 3.配置环境变量(3台同样操作)
[root@db01 bin]# cat /etc/profile.d/jdk.sh
jdk_PATH=/usr/local/jdk1.8.0
export PATH=$jdk_PATH/bin:$PATH
[root@db01 bin]# source /etc/profile
# 4.查看是否成功安装
[root@db03 local]# java -version
java version "1.8.0_241"
Java(TM) SE Runtime Environment (build 1.8.0_241-b07)
Java HotSpot(TM) 64-Bit Server VM (build 25.241-b07, mixed mode)
# 5.安装zookeeper
1> 解压zookeeper(三台同样操作)
[root@db01 tmp]# tar -xf apache-zookeeper-3.5.9-bin.tar.gz -C /usr/local/
2> 进入zookeeper目录中创建data目录(三台同样操作)
[root@db02 apache-zookeeper-3.5.9-bin]# mkdir data
3> 进入conf目录中,修改配置文件(三台同样操作)
[root@db02 conf]# mv zoo_sample.cfg zoo.cfg
[root@db02 conf]# cat zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/apache-zookeeper-3.5.9-bin/data
clientPort=2181
4> 在每个zookeeper的data目录下创建一个myid文件,分别为1,2,3,此文件记录每个服务器id
[root@db01 data]# cat /usr/local/apache-zookeeper-3.5.9-bin/data/myid
1
[root@db02 data]# cat /usr/local/apache-zookeeper-3.5.9-bin/data/myid
2
[root@db03 data]# cat /usr/local/apache-zookeeper-3.5.9-bin/data/myid
3
5> 在每个zookeeper配置文件中分别加入集群配置(注意:3888后面不要有空格)
# 注意:server后面的数字代表myid,后面的ip为myid主机对应ip
# 2888:对client提供服务 3888:选举leader使用
server.1=10.0.0.51:2888:3888
server.2=10.0.0.52:2888:3888
server.3=10.0.0.53:2888:3888
6> 依次启动集群,将会产生一个leader和两个follower
[root@db01 bin]# ./zkServer.sh start
[root@db02 bin]# ./zkServer.sh start
[root@db03 bin]# ./zkServer.sh start
7> 查看集群状态
[root@db01 bin]# ./zkServer.sh status
/usr/local/jdk1.8.0/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/apache-zookeeper-3.5.9-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@db02 bin]# ./zkServer.sh status
/usr/local/jdk1.8.0/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/apache-zookeeper-3.5.9-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
[root@db03 bin]# ./zkServer.sh status
/usr/local/jdk1.8.0/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/apache-zookeeper-3.5.9-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
· 由此可见db02成为了leader,成为leader的原因是myid和启动顺序相关。
zookeeper基本使用
数据结构
zookeeper数据模型结构与unix文件系统很类似,整体上可以看作是一颗树,每个节点称作一个ZNode,每个ZNode都可以通过其路径唯一标识。
Znode节点类型:
· 持久化目录节点(pesistent)
客户端与zookeeper断开连接后,该节点依旧存在
· 持久化顺序编号目录节点(pesistent_sequential)
客户端与zookeeper断开连接后,该节点依然存在,zookeeper会给改节点按照顺序编号
· 临时目录节点(ephemeral)
客户端与zookeeper断开连接后,该节点被删除
命令行使用
# 服务启动:
[root@db02 bin]# ./zkServer.sh start
# 进入zk客户端命令行
[root@db02 bin]# ./zkCli.sh
# 查看帮助
[zk: localhost:2181(CONNECTED) 0] help
# 使用ls命令查看当前znode中所包含的内容(后面接-w参数,可监听/下的变化,监听有效期仅一次)
[zk: localhost:2181(CONNECTED) 3] ls /
[zookeeper]
# 查看当前节点存放数据和更新次数
[zk: localhost:2181(CONNECTED) 4] ls2 /
'ls2' has been deprecated. Please use 'ls [-s] path' instead.
[zookeeper]
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = -1
dataVersion = 0 # 这里指更新次数
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
# 创建节点-s 含有序列 -e 临时
[zk: localhost:2181(CONNECTED) 5] create /tcy # 普通创建值为null
Created /tcy
[zk: localhost:2181(CONNECTED) 8] create /yjx yjxvalue # 创建带值
Created /yjx
# 获取节点值(后面接-w参数,可监听值的改变,监听有效期为1次)
[zk: localhost:2181(CONNECTED) 10] get /tcy
null
[zk: localhost:2181(CONNECTED) 9] get /yjx
yjxvalue
# 设置节点值
[zk: localhost:2181(CONNECTED) 13] set /yjx yjxvalue2 # 将原先值yjxvlaue改为yjxvalue2
[zk: localhost:2181(CONNECTED) 14] get /yjx
yjxvalue2
# 查看节点状态(但无法显示值)
[zk: localhost:2181(CONNECTED) 15] stat /yjx
cZxid = 0x100000007
ctime = Sun Jan 24 19:44:24 CST 2021
mZxid = 0x100000008
mtime = Sun Jan 24 19:46:44 CST 2021
pZxid = 0x100000007
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 9
numChildren = 0
# 删除节点
[zk: localhost:2181(CONNECTED) 16] delete /yjx
[zk: localhost:2181(CONNECTED) 17] ls /
[tcy, zookeeper]
[zk: localhost:2181(CONNECTED) 18] create /tcy/tcy1 # 创建子节点
Created /tcy/tcy1
[zk: localhost:2181(CONNECTED) 19] delete /tcy # 无法删除带子节点的节点
Node not empty: /tcy
[zk: localhost:2181(CONNECTED) 27] deleteall /tcy # 递归删除子节点
应用场景
配置中心
在平常的业务开发过程中,我们通常需要将系统的一些通用的全局配置,例如机器列表配置,运行时开关配置,数据库配置信息统一集中存储,
让集群所有机器共享配置信息,系统在启动会首先从配置中心读取配置信息,进行初始化,传统的实现方式,将配置存储在本地和内存中,
一旦机器规模更大,配置变更频繁情况下,本地文件和内存方式的配置维护成本较高,使用zookeeper作为分布式的配置中心就可以解决这个问题。
将配置信息存在zk中的一个节点中,同时给该节点注册一个数据节点变更的watcher监听,一旦节点数据发生变更,所有的订阅改节点的客户端可以获取数据变更通知。
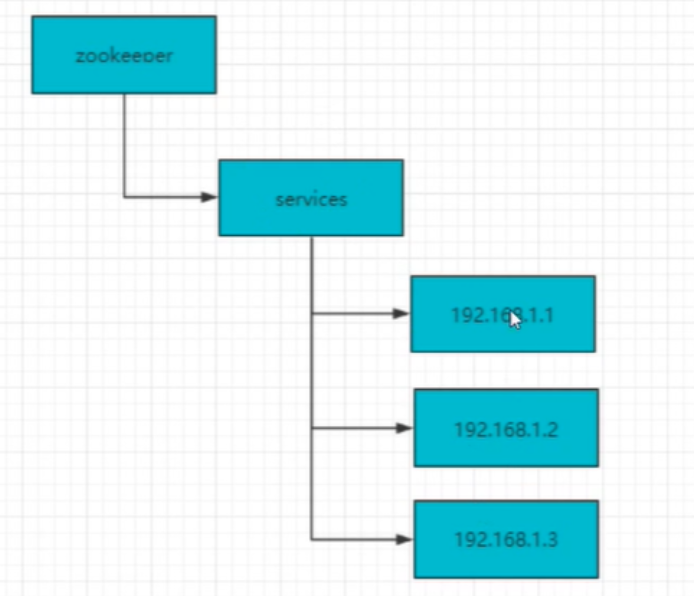
负载均衡
建立server节点,并建立监听器监视server子节点状态,(用于在服务器增添时及时同步当前集群中服务器列表)。在每个服务器启动时,
在server节点下建立具体服务器地址的子节点,并在对应的子节点下存入服务器相关信息,这样,我们在zk服务器上就可以获取当前集群中的服务器列表及相关信息,
可以自定义一个负载均衡算法,在每个请求过来时zk服务器中获取当前集群服务器列表,根据算法选出其中一个服务器来处理请求。
命名服务
命名服务是分布式系统中的基本服务器之一,被命名的实体通常可以是集群中的机器,提供的服务地址或者远程对象,这些都可以作为名字,
常见的就是一些分布式服务框架(RPC、RMI)中的服务器地址列表,通过使用名称服务客户端可以获取资源的实体、服务地址和提供者信息。
命名服务就是通过一个资源引用的方式来实现对资源的定位和使用。在分布式环境中,上层应用仅仅需要一个全局唯一名称,就像数据库中的主键。
在单库单表系统中可以通过自增ID来标识每一条记录,但是随着规模变大分库分表很常见,那么自增ID又仅能针对单一表生成ID,
所以在这种情况下无法依靠这个来标识唯一ID,UUID就是一种全局唯一标识符,但是长度不易识别
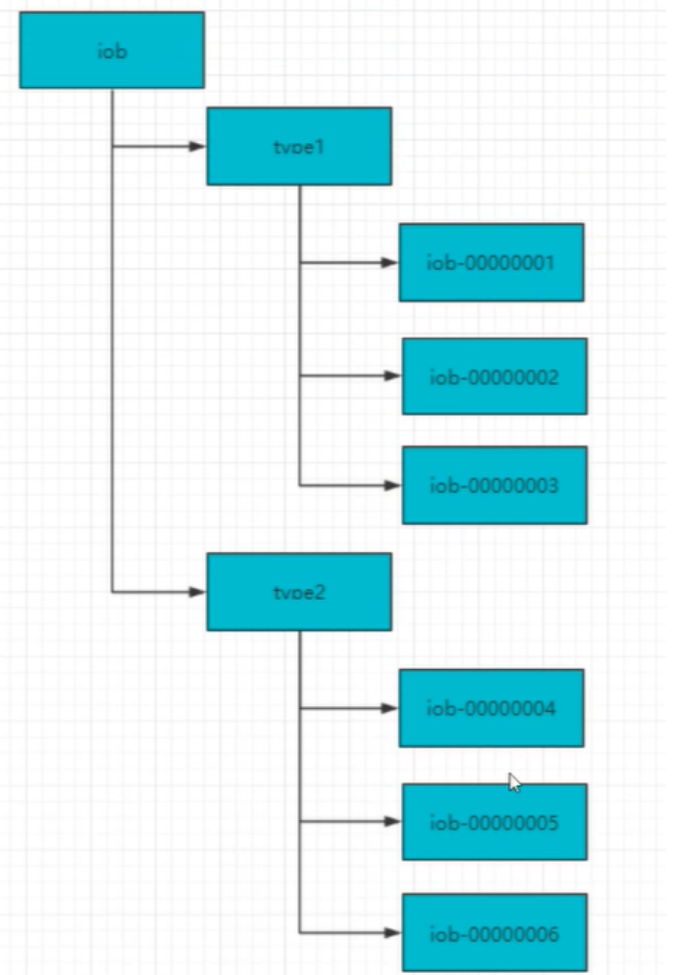
- 在zk中通过创建顺序节点可以实现,所有客户端都会根据自己的任务类型来创建一个顺序节点,例如job-00000001
- 节点创建完毕后,create()接口会返回一个完整的节点名,例如:job-00000002
· 拼接type类型和完整节点作为全局唯一的ID
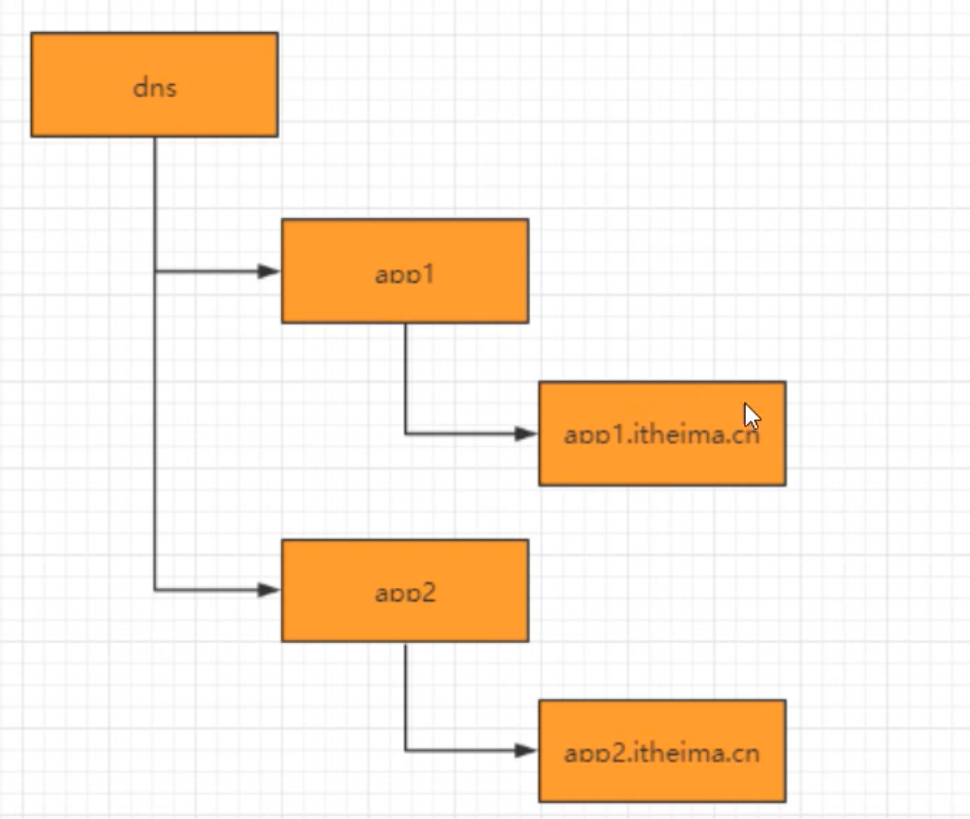
DNS服务
- 域名服务
在分布式系统应用中,每一个应用都需要分配一个域名,日常开发中,往往使用本地HOST绑定域名解析,开发阶段可以随时修改域名和ip的映射,
大大提高开发的测试效率。如果应用的机器规模达到一定程度后,需要频繁更新域名时,需要在规模的集群中变更,无法保证实时性,所以我们在zk上创建一个节点来进行域名配置。
· 域名解析
应用解析,首先从zk域名节点中获取域名映射的ip和端口
· 域名变更
每个应用都会在对应的域名节点注册一个数据变更的watcher监听,一旦监听的域名节点数据变更,zk会向所有订阅的客户端发送域名变更通知。
集群管理
集群控制:集群中节点操作和控制
集群监控:对集群节点运作状态的收集
# 在日常开发和运维中,我们经常会有类似如下的需求:
希望知道当前集群中有多少机器在工作
对集群中每台机器运作时状态进行数据收集
对集群中机器进行上下线操作
传统的方式采用agent代理方式,有统一的监控中心系统,agent主动汇报当前机器状态,传统agent管理方式弊端:大规模升级困难,编程语言多样性。
随着分布式规模日益扩大,集群中机器的数量越来越多,有效的集群管理越来越重要,zookeeper集群管理主要利用了watcher机制和创建临时节点来实现,以机器上下线和机器监控为例:
· 机器上下线
新增机器时,将agent部署到新增机器上,当agent部署启动时,会向zookeeper指定的节点下创建一个临时子节点,当agent在zk上创建完这个节点后,
当关注的节点zookeeper/machines下的子节点新加入新的节点或删除都会发送
通知,这样就对机器的上下线进行监控
· 机器监控
在机器运行过程中,agent会定时将主机的运行状态信息写入到/machines/hostn主机节点,监控中心通过订阅这些节点的数据变化来获取主机的运行信息
zookeeper实现分布式锁
# 实现原理:(有序临时节点+watch监听)
如下图所示,以减少库存示例为例,当client同时访问到zookeeper时,zk会根据访问顺序,为每个执行的线程创建一个有序的临时节点,
为了确保有序,每当创建完节点,会重新进行一次排序,排序过程中,每个线程要判断自己临时节点的需要是否是最小的
如果是最小的,将会获取到锁,也就是先执行相关操作,释放锁
如果不是最小的,那么会监听它的前一个节点,当它的前一个节点被删除时,他就会获得锁,依次类推

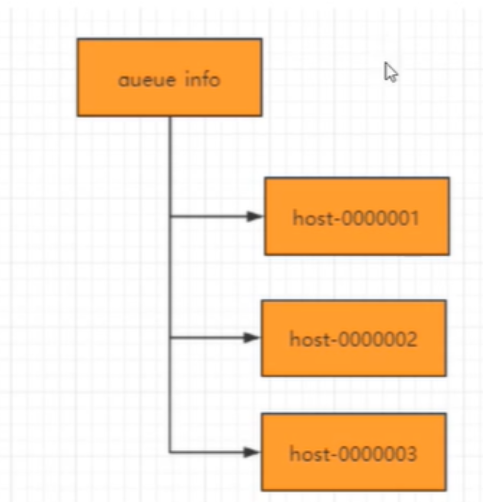
分布式队列
队列特性:FIFO(先入先出),zookeeper实现分布式队列的步骤:
· 在队列节点下创建临时顺序节点 例如/queue_info/192.168.1.1-0000001
· 比较自己节点是否是序号最小的节点,如果不是,则等待其他节点出队列,在需要最小的节点注册watcher
· 获取watcher通知后,重复步骤
dubbo
Apache Dubbo是一款高性能的java RPC框架,其前身是阿里巴巴公司开源的一个高性能,轻量级的开源java RPC框架,可以和spring框架无缝衔接。
Dubbo提供三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现,
官网:http://dubbo.apache.org/
# 什么是PRC
RPC全程remote procedure call,即远程过程调用,比如两台服务器A和B,A服务器上部署一个引用,B服务器上部署一个应用,A服务器上的应用想调用B服务器上的应用提供的方法,由于两个应用不在一个内存空间,不能被直接调用,所以需要网络来表达调用的语义和传达调用的数据。
需要注意的是RPC并不是一个具体的技术,而是指整个网络远程调用的过程。
而不需要了解底层网络技术的协议,在面向对象编程语言中,远程过程调用即是远程方法调用
java中RPC框架比较多,常见的有RMI,hessian,grpc(谷歌),brpc(百度),dubbo等,其实对于rpc框架而言,核心模块就是通讯和序列化,下面将介绍常见的RPC框架:
RMI
1> RMI(remote method invocation)是java原生支持的远程调用,RMI采用jrmp(java remotemessageing protocol)作为通讯协议,可以认为是纯java版本的分布式远程调用解决方案。
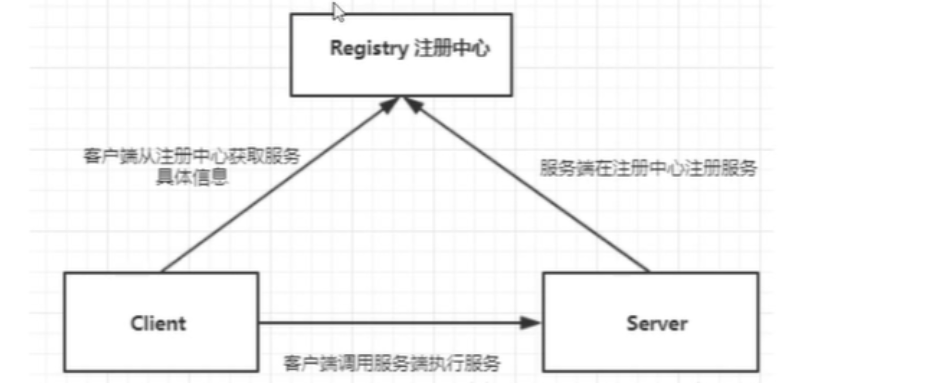
2> RMI的核心概念:
3> RMI步骤:
- 创建远程接口,并且继承java.rmi.Remote接口
- 实现远程接口,并且继承:UnicastRemoteObject
- 创建服务程序,createRegistry()方法注册远程对象
- 创建客户端程序(获取注册信息,调用接口方法)