原文链接:http://tecdat.cn/?p=6663
此示例中,神经网络用于使用2011年4月至2013年2月期间的数据预测都柏林市议会公民办公室的能源消耗。
每日数据是通过总计每天提供的15分钟间隔的消耗量来创建的。
LSTM简介
LSTM(或长期短期存储器网络)允许分析具有长期依赖性的顺序或有序数据。当涉及到这项任务时,传统的神经网络不足,在这方面,LSTM将用于预测这种情况下的电力消耗模式。
与ARIMA等模型相比,LSTM的一个特殊优势是数据不一定需要是固定的(常数均值,方差和自相关),以便LSTM对其进行分析 - 即使这样做可能会导致性能提升。
自相关图,Dickey-Fuller测试和对数变换
为了确定我们的模型中是否存在平稳性:
- 生成自相关和部分自相关图
- 进行Dickey-Fuller测试
- 对时间序列进行对数变换,并再次运行上述两个过程,以确定平稳性的变化(如果有的话)
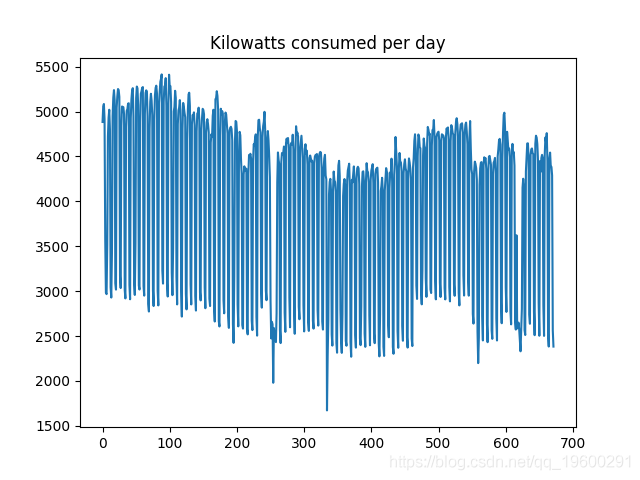
首先,这是时间序列图:

![]()
![]()
据观察,波动性(或消费从一天到下一天的变化)非常高。在这方面,对数变换可以用于尝试稍微平滑该数据。在此之前,生成ACF和PACF图,并进行Dickey-Fuller测试。
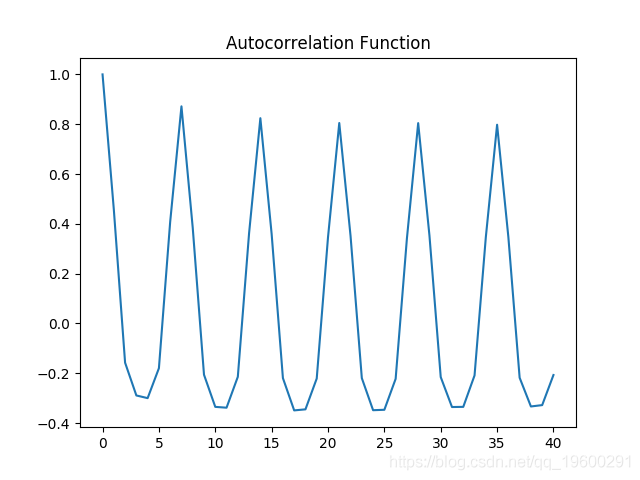
自相关图
![]()
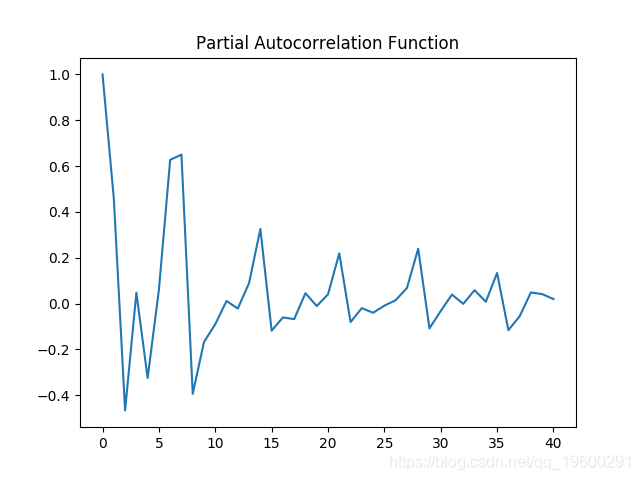
部分自相关图
![]()
自相关和部分自相关图都表现出显着的波动性,这意味着时间序列中的几个区间存在相关性。
运行Dickey-Fuller测试时,会产生以下结果:
当p值高于0.05时,不能拒绝非平稳性的零假设。
STD1
954.7248
4043.4302
0.23611754
变异系数(或平均值除以标准差)为0.236,表明该系列具有显着的波动性。
现在,数据被转换为对数格式。
虽然时间序列仍然不稳定,但当以对数格式表示时,偏差的大小略有下降:

![]()
此外,变异系数已显着下降至0.0319,这意味着与平均值相关的趋势的可变性显着低于先前。
STD2 = np.std(数据集)
mean2 = np.mean(数据集)
cv2 = std2 / mean2 #Cafficient of Variation std2
0.26462445 mean2
8.272395 cv2
0.031988855 同样,在对数数据上生成ACF和PACF图,并再次进行Dickey-Fuller测试。
自相关图

![]()
偏自相关图

![]()
Dickey-Fuller测试
... print(' t%s:%。3f'%(键,值))
1%:-3.440
5%: - 2.866
10%: - 2.569 Dickey-Fuller检验的p值降至0.0576。虽然这在技术上没有输入拒绝零假设所需的5%显着性阈值,但对数时间序列已显示基于CV度量的较低波动率,因此该时间序列用于LSTM的预测目的。
LSTM的时间序列分析
现在,LSTM模型本身用于预测目的。
数据处理
首先,导入相关库并执行数据处理
LSTM生成和预测
模型训练超过100个时期,并生成预测。
#生成LSTM网络
model = Sequential()
model.add(LSTM(4,input_shape =(1,previous)))
model.fit(X_train,Y_train,epochs = 100,batch_size = 1,verbose = 2)
#生成预测
trainpred = model.predict(X_train)
#将预测转换回正常值
trainpred = scaler.inverse_transform(trainpred)
#calculate RMSE
trainScore = math.sqrt(mean_squared_error(Y_train [0],trainpred [:,0]))
#训练预测
trainpredPlot = np.empty_like(dataset)
#测试预测
#绘制所有预测
inversetransform,= plt.plot(scaler.inverse_transform(dataset))
准确性
该模型显示训练数据集的均方根误差为0.24,测试数据集的均方根误差为0.23。平均千瓦消耗量(以对数格式表示)为8.27,这意味着0.23的误差小于平均消耗量的3%。
以下是预测消费与实际消费量的关系图:

![]()
有趣的是,当在原始数据上生成预测(未转换为对数格式)时,会产生以下训练和测试错误:
在每天平均消耗4043千瓦的情况下,测试分数的均方误差占总日均消耗量的近20%,并且与对数数据产生的相比非常高。
也就是说,重要的是要记住,使用1天的先前数据进行预测,即Y表示时间t的消耗,而X表示时间t-1的消耗,由代码中的前一个变量设置先前。让我们来看看这增加到个究竟10和50天。
10天

![]()
# 50天

![]()
我们可以看到测试误差在10天和50天期间显着降低,并且考虑到LSTM模型在预测时考虑了更多的历史数据,消耗的波动性得到了更好的捕获。
鉴于数据是对数格式,现在可以通过获得数据的指数来获得预测的真实值。
例如,testpred变量用(1,-1)重新整形:
testpred.reshape(1,-1)
array([[7.7722197,8.277015,8.458941,8.455311,8.447589,8.445035,
......
8.425287,8.404881,8.457063,8.423954,7.98714,7.9003944,
8.240862,8.41654,8.423854,8.437414,8.397851,7.9047146]],
dtype = float32)结论
对于这个例子,LSTM被证明在预测电力消耗波动方面非常准确。此外,以对数格式表示时间序列允许平滑数据的波动性并提高LSTM的预测准确度。
![]()