逻辑回归对用户收入进行预测


![]()
对于某企业新用户,会利用大数据来分析该用户的信息来确定是否为付费用户,弄清楚用户属性,从而针对性的进行营销,提高运营人员的办事效率。
对于付费用户预测,主要是思考收入由哪些因素推动,再对每个因素做预测,最后得出付费预测。这其实不是一个财务问题,是一个业务问题。
流失预测。这方面会偏向于大额付费用户,提取额特征向量运用到应用场景的用户流失和预测里面去。
方法
回归是一种极易理解的模型,就相当于y=f(x),表明自变量x与因变量y的关系。最常见问题有如医生治病时的望、闻、问、切,之后判定病人是否生病或生了什么病,其中的望闻问切就是获取自变量x,即特征数据,判断是否生病就相当于获取因变量y,即预测分类。
问题描述
我们尝试并预测用户是否可以根据数据中可用的人口信息变量使用逻辑回归预测月度付费是否超过 50K。
在这个过程中,我们将:
1.导入数据
2.检查类别偏差
3.创建训练和测试样本
4.建立logit模型并预测测试数据
5.模型诊断
检查类偏差
理想情况下,Y变量中事件和非事件的比例大致相同。 所以,我们首先检查因变量ABOVE 50K中的类的比例。
0 1
24720 7841
显然,不同付费人群比例 有偏差 。 所以我们必须以大致相等的比例对观测值进行抽样,以获得更好的模型。
构建Logit模型和预测
确定模型的最优预测概率截止值
默认的截止预测概率分数为0.5或训练数据中1和0的比值。 但有时,调整概率截止值可以提高开发和验证样本的准确性。InformationValue :: optimalCutoff功能提供了找到最佳截止值,减少错误分类错误。
optCutOff <- optimalCutoff(testData$ABOVE50K, predicted)[1]
=> 0.71
模型诊断
错误分类错误
错误分类错误是预测与实际的不匹配百分比 。 错误分类错误越低, 模型越好。
misClassError(testData$ABOVE50K, predicted, threshold = optCutOff)
[1] 0.0892
ROC曲线
ROC曲线指受试者工作特征曲线 / 接收器操作特性曲线(receiver operating characteristic curve), 是反映敏感性和特异性连续变量的综合指标,是用构图法揭示敏感性和特异性的相互关系,它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性,再以敏感性为纵坐标、(1-特异性)为横坐标绘制成曲线,曲线下面积越大,诊断准确性越高。在ROC曲线上,最靠近坐标图左上方的点为敏感性和特异性均较高的临界值。
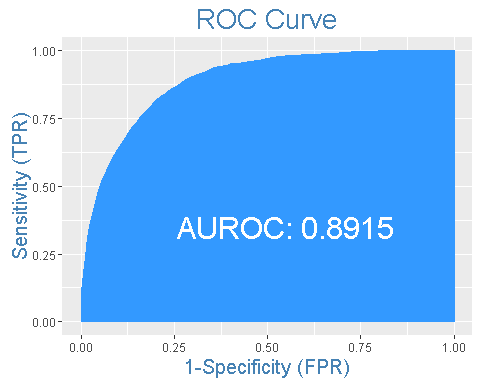
上述型号的ROC曲线面积为89%,相当不错。
一致性
简单来说,在1-0 的所有组合中,一致性是预测对的百分比 ,一致性越高,模型的质量越好。
$Concordance
[1] 0.8915107
$Discordance
[1] 0.1084893
$Tied
[1] -2.775558e-17
$Pairs
[1] 45252896
上述型号的89.2%的一致性确实是一个很好的模型。
混淆矩阵
在人工智能中,混淆矩阵(confusion matrix)是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。其每一列代表预测值,每一行代表的是实际的类别。这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class)。
confusionMatrix(testData$ABOVE50K, predicted, threshold = optCutOff)
0 1
0 18849 1543
1 383 810
结论
这里仅仅介绍了模型的建立和评估。通过模型的结论,我们可以得到一些已经为公众所接受和熟知的现象是:付费和受教育程度、智力、年龄以及性别等相关。 基于此用户规模预测模型,结合用户的人口信息,即可粗略预估产品在一般情况下的收入情况, 从而判断就得到了付费用户预测模型,如果把收入分类转换成流失用户和有效用户,就得到了流失用户预测模型。