原文链接:http://tecdat.cn/?p=6105
介绍
聚类模型是一个概念,用于表示我们试图识别的聚类类型。四种最常见的聚类方法模型是层次聚类,k均值聚类,基于模型的聚类和基于密度的聚类
可以基于两个主要目标评估良好的聚类算法:
- 高级内相似性
- 低级间相似性
基于模型的聚类是迭代方法,通过优化聚类中数据集的分布,将一组数据集拟合到聚类中。高斯分布只不过是正态分布。此方法分三步进行:
- 首先随机选择高斯参数并将其拟合到数据点集。
- 迭代地优化分布参数以适应尽可能多的点。
- 一旦收敛到局部最小值,您就可以将数据点分配到更接近该群集的分布。
有关高斯混合模型的详细信息
基于概率模型的聚类技术已被广泛使用,并且已经在许多应用中显示出有希望的结果,从图像分割,手写识别,文档聚类,主题建模到信息检索。基于模型的聚类方法尝试使用概率方法优化观察数据与某些数学模型之间的拟合。
生成模型通常使用EM方法求解,EM方法是用于估计有限混合概率密度的参数的最广泛使用的方法。基于模型的聚类框架提供了处理此方法中的几个问题的主要方法,例如组件密度(或聚类)的数量,参数的初始值(EM算法需要初始参数值才能开始),以及分量密度的分布(例如,高斯分布)。EM以随机或启发式初始化开始,然后迭代地使用两个步骤来解决计算中的循环:
- E-Step。使用当前模型参数确定将数据点分配给群集的预期概率。
- M-Step。通过使用分配概率作为权重来确定每种混合物的最佳模型参数。
R中的建模
mb = Mclust(iris[,-5])
#or specify number of clusters
mb3 = Mclust(iris[,-5], 3)
# optimal selected model
mb$modelName
# optimal number of cluster
mb$G
# probality for an observation to be in a given cluster
head(mb$z)
# get probabilities, means, variances
summary(mb, parameters = TRUE)
table(iris$Species, mb$classification)
# vs
table(iris$Species, mb3$classification)
比较每个群集中的数据量
在将数据拟合到模型中之后,我们基于聚类结果绘制模型。
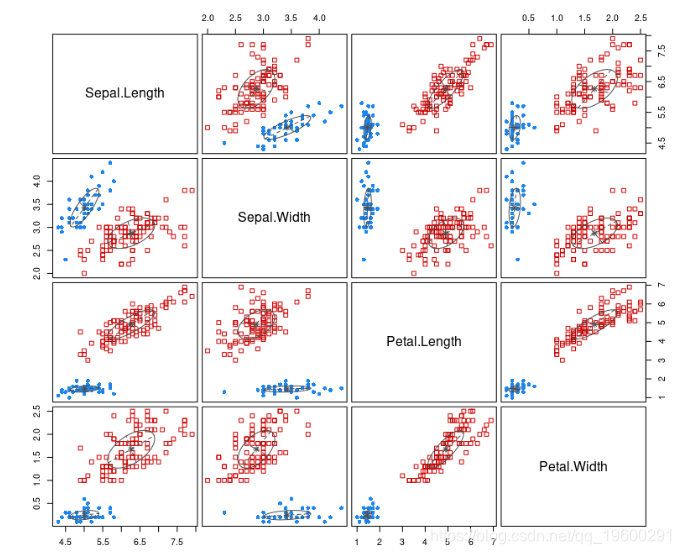
![]()
让我们绘制估计的密度。
plot(mb, "density")
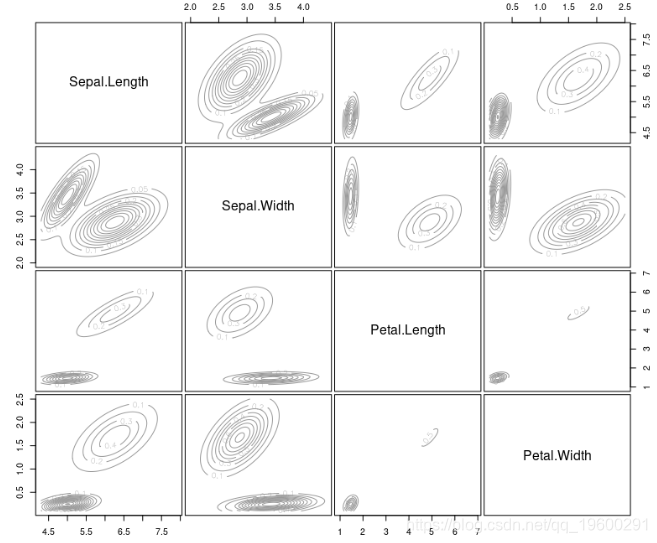
![]()
您还可以使用该summary()函数来获取最可能的模型和最可能数量的集群。对于此示例,最可能的簇数为5,BIC值等于-556.1142。
比较聚类方法
在使用不同的聚类方法将数据拟合到聚类中之后,您可能希望测量聚类的准确性。在大多数情况下,您可以使用集群内或集群间度量标准作为度量。集群间距离越高越好,集群内距离越低,越好。
接下来,检索聚类方法的集群验证统计信息:
通常,我们专注于使用within.cluster.ss和avg.silwidth验证聚类方法。该within.cluster.ss测量表示所述簇内总和的平方,和avg.silwidth表示平均轮廓宽度。
within.cluster.ss测量显示了相关对象在群集中的紧密程度; 值越小,集群中的对象越紧密。avg.silwidth是一种度量,它考虑了群集中相关对象的紧密程度以及群集之间的分离方式。轮廓值通常为0到1; 接近1的值表明数据更好地聚类。
k-means和GMM之间的关系
K均值可以表示为高斯混合模型的特例。通常,高斯混合更具表现力,因为数据项对群集的成员资格取决于该群集的形状,而不仅仅取决于其接近度。
与k-means一样,用EM训练高斯混合模型可能对初始启动条件非常敏感。如果我们将GMM与k-means进行比较和对比,我们会发现前者的初始条件比后者更多。
结果
每个聚类被建模为多元高斯分布,并通过给出以下内容来指定模型:
- 集群数量。
- 每个群集中所有数据点的分数。
- 每个聚类的均值和它的d-by-d协方差矩阵。