原文链接:http://tecdat.cn/?p=13518
在课程中进行案例研究(使用真实数据)时,学生都会惊讶地发现很难获得“好”模型,而当试图对索赔的概率进行建模时,他们总是会惊讶地发现AUC较低。因为保险中存在很多'随机性'。
更具体地说,我决定进行一些模拟,并计算AUC以查看发生了什么。而且由于我不想浪费时间进行拟合模型,因此我们假设每次都有一个完美的模型。因此,我想表明AUC的上限实际上很低!因此,这不是建模问题,而是保险业的基础问题。
我们使用协变量(例如在汽车保险中的汽车驾驶员的年龄或在人寿保险中的保单持有人的年龄等)。然后我们使用它们来训练模型。然后,我们使用从混淆矩阵获得的ROC曲线来检查我们的模型是否良好。在这里,我不会尝试构建模型。我会预测每次真实基础概率超过阈值!
在这里 p( omega_1)表示索赔损失,欺诈等的可能性。这里存在异质性,这种异质性可以很小,也可以很大。请看下面的图表来说明,
![]()
在这两种情况下,平均有25%的机会要求赔偿损失。但是在左边,存在更多的异构性,更多的分散性。为了说明这一点,我使用了箭头。
考虑一些带有伯努利变量的数据集 y,用这些概率得出p( omega),p (ω )。然后,我们假设我们能够得到一个完美的模型:我不会基于某些协变量来估计模型,在这里,我假设我完全知道概率。更具体地说,为了生成概率向量,在这里我使用具有给定均值和给定方差的Beta分布(以捕获上面提到的异质性).
a=m*(m*(1-m)/v-1)
b=(1-m)*(m*(1-m)/v-1)
p=rbeta(n,a,b)从这些概率中,我模拟了索赔或死亡的发生,
Y=rbinom(n,size = 1,prob = p)然后,我计算出“完美”模型的AUC,
auc.tmp=performance(prediction(p,Y),"auc")然后,我将生成许多样本,以计算AUC的平均值。我们可以对Beta分布的均值和方差的许多值执行此操作。这是代码
Vm=seq(.025,.975,by=.025)
Vi=seq(.01,.5,by=.01)
V=outer(X = Vm,Y = Vi, Vectorize(function(x,y)
Sim_AUC_mean_inter(x,y)$moy_AUC))
library("RColorBrewer")
image(Vm,Vi,V,
xlab="Probability (Average)",
ylab="Dispersion (Q95-Q5)",
col=
colorRampPalette(brewer.pal(n = 9, name = "YlGn"))(101))
contour(Vm,Vi,V,add=TRUE,lwd=2)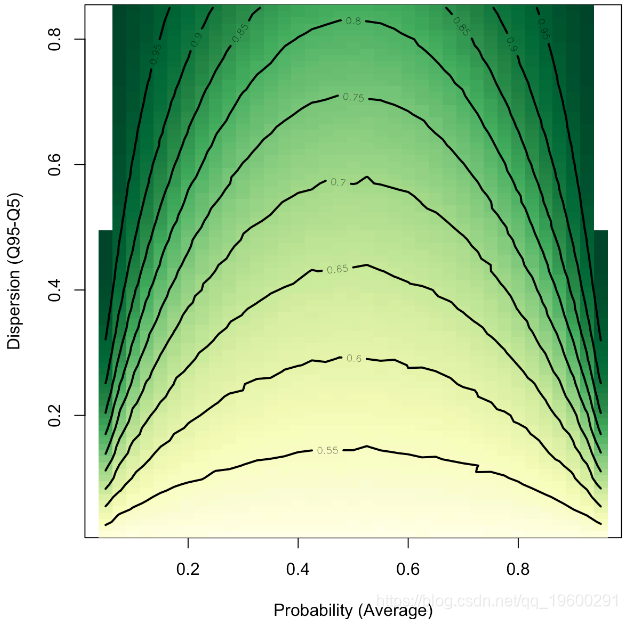
![]()
在x轴上,我们有索赔的平均概率。当然,这里是对称的。在y轴上,我们具有分散性:投资组合中的异质性越低,其混合性就越小。例如,平均有30%的机会要求损失,分散度为20%(这意味着在投资组合中,90%的被保险人有20%至40%的机会主张损失),我们平均有60%的AUC。
根据我的经验,在汽车保险中,90%的被保险人有3%到20%的机会要求赔偿,在那种情况下,即使(平均)概率很小,也期望AUC很难高于60%或65%。