原文链接:http://tecdat.cn/?p=19095
本文对R中的文本内容进行情感分析。此实现利用了各种现有的字典,此外,还可以创建自定义词典。自定义词典使用LASSO正则化作为一种统计方法来选择相关词语。最后,评估比较所有方法。
介绍
情感分析是自然语言处理(NLP),计算语言学和文本挖掘的核心研究分支。它是指从文本文档中提取主观信息的方法。换句话说,它提取表达意见的积极负面极性。人们也可能将情感分析称为 观点挖掘 (Pang and Lee 2008)。
研究中的应用
最近,情感分析受到了广泛的关注(K. Ravi和Ravi 2015; Pang和Lee 2008),我们将在下面进行探讨。当前在金融和社会科学领域的研究利用情感分析来理解人类根据文本材料做出的决策。这立即揭示了对从业者以及金融研究和社会科学领域的从业者的多种含义:研究人员可以使用R提取与读者相关的文本成分,并在此基础上检验其假设。同样,从业人员可以衡量哪种措辞对他们的读者而言实际上很重要,并相应地提高他们的写作水平(Pröllochs,Feuerriegel和Neumann 2015)。在下面的两个案例研究中,我们从金融和社会科学中论证了增加的收益。
应用
几个应用程序演示了情感分析在组织和企业中的用途:
-
金融: 金融市场的投资者在行使股票所有权之前,会以金融新闻披露的形式参考文本信息。有趣的是,它们不仅依赖数据,而且还依赖信息,例如语气和情感(Henry 2008; Loughran和McDonald 2011; Tetlock 2007),从而极大地影响了股价。通过利用情感分析,自动化交易者可以分析财务披露中传达的情感,以便进行投资决策。
-
市场营销: 市场营销部门通常对跟踪品牌形象感兴趣。为此,他们从社交媒体上收集了大量用户意见,并评估个人对品牌,产品和服务的感受。
-
评级和评论平台: 评级和评论平台通过收集用户对某些产品和服务的评级或偏好来实现有价值的功能。在这里,人们可以自动处理大量用户生成的内容(UGC)并利用由此获得的知识。例如,人们可以确定哪些提示传达了积极或者负面的意见,甚至可以自动验证其可信度。
情感分析方法
随着情感分析被应用于广泛的领域和文本来源,研究已经设计出各种测量情感的方法。最近的文献综述(Pang and Lee 2008)提供了一个全面的,与领域无关的调查。
一方面,当机器学习方法追求高预测性能时,它是首选。但是,机器学习通常充当黑匣子,从而使解释变得困难。另一方面,基于字典的方法会生成肯定和否定单词的列表。然后,将这些单词的相应出现组合为单个情感评分。因此,基本的决定变得可追溯,研究人员可以理解导致特定情感的因素。
另外, SentimentAnalysis 允许生成定制的字典。它们针对特定领域进行了定制,与纯字典相比,提高了预测性能,并具有完全的可解释性。可以在(Pröllochs,Feuerriegel和Neumann 2018)中找到此方法的详细信息。
在执行情感分析的过程中,必须将正在运行的文本转换为一种机器可读的格式。这是通过执行一系列预处理操作来实现的。首先,将文本标记为单个单词,然后执行常见的预处理步骤:停用词的删除,词干,标点符号的删除以及小写的转换。这些操作也默认在中进行 SentimentAnalysis,但可以根据个人需要进行调整。
简短示范
-
# 分析单个字符极性(正/负)
-
-
anaSen("是的,这对德国队来说是一场很棒的足球比赛!")
-
## [1] positive
-
## Levels: negative positive
-
# 创建字符串向量
-
-
-
documents <- c("哇,我真的很喜欢新的轻型军刀!",
-
-
"那本书很棒。",
-
-
"R是一种很棒的语言。",
-
-
"这家餐厅的服务很糟糕。"
-
-
"这既不是正面也不是负面。",
-
-
"服务员忘了我的甜点-多么糟糕的服务!")
-
-
# 分析情感
-
-
-
anaSen(documents)
-
-
# 根据QDAP词典提取基于词典的情感
-
-
-
sentiment$SentimentQDAP
## [1] 0.3333333 0.5000000 0.5000000 -0.3333333 0.0000000 -0.4000000-
#查看情感方向(即正面,中性和负面)
-
-
-
ToDirection(sentiment$SentimentQDAP)
-
## [1] positive positive positive negative neutral negative
-
## Levels: negative neutral positive
-
response <- c(+1, +1, +1, -1, 0, -1)
-
-
comToRne(sentiment, response)
-
## WordCount SentimentGI NegativityGI
-
## cor -0.18569534 0.990011498 -9.974890e-01
-
## cor.t.statistic -0.37796447 14.044046450 -2.816913e+01
-
## cor.p.value 0.72465864 0.000149157 9.449687e-06
-
## lm.t.value -0.37796447 14.044046450 -2.816913e+01
-
## r.squared 0.03448276 0.980122766 9.949843e-01
-
## RMSE 3.82970843 0.450102869 1.186654e+00
-
## MAE 3.33333333 0.400000000 1.100000e+00
-
## Accuracy 0.66666667 1.000000000 6.666667e-01
-
## Precision NaN 1.000000000 NaN
-
## Sensitivity 0.00000000 1.000000000 0.000000e+00
-
## Specificity 1.00000000 1.000000000 1.000000e+00
-
## F1 0.00000000 0.500000000 0.000000e+00
-
## BalancedAccuracy 0.50000000 1.000000000 5.000000e-01
-
## avg.sentiment.pos.response 3.25000000 0.333333333 8.333333e-02
-
## avg.sentiment.neg.response 4.00000000 -0.633333333 6.333333e-01
-
## PositivityGI SentimentHE NegativityHE
-
## cor 0.942954167 0.4152274 -0.083045480
-
## cor.t.statistic 5.664705543 0.9128709 -0.166666667
-
## cor.p.value 0.004788521 0.4129544 0.875718144
-
## lm.t.value 5.664705543 0.9128709 -0.166666667
-
## r.squared 0.889162562 0.1724138 0.006896552
-
## RMSE 0.713624032 0.8416254 0.922958207
-
## MAE 0.666666667 0.7500000 0.888888889
-
## Accuracy 0.666666667 0.6666667 0.666666667
-
## Precision NaN NaN NaN
-
## Sensitivity 0.000000000 0.0000000 0.000000000
-
## Specificity 1.000000000 1.0000000 1.000000000
-
## F1 0.000000000 0.0000000 0.000000000
-
## BalancedAccuracy 0.500000000 0.5000000 0.500000000
-
## avg.sentiment.pos.response 0.416666667 0.1250000 0.083333333
-
## avg.sentiment.neg.response 0.000000000 0.0000000 0.000000000
-
## PositivityHE SentimentLM NegativityLM
-
## cor 0.3315938 0.7370455 -0.40804713
-
## cor.t.statistic 0.7029595 2.1811142 -0.89389841
-
## cor.p.value 0.5208394 0.0946266 0.42189973
-
## lm.t.value 0.7029595 2.1811142 -0.89389841
-
## r.squared 0.1099545 0.5432361 0.16650246
-
## RMSE 0.8525561 0.7234178 0.96186547
-
## MAE 0.8055556 0.6333333 0.92222222
-
## Accuracy 0.6666667 0.8333333 0.66666667
-
## Precision NaN 1.0000000 NaN
-
## Sensitivity 0.0000000 0.5000000 0.00000000
-
## Specificity 1.0000000 1.0000000 1.00000000
-
## F1 0.0000000 0.3333333 0.00000000
-
## BalancedAccuracy 0.5000000 0.7500000 0.50000000
-
## avg.sentiment.pos.response 0.2083333 0.2500000 0.08333333
-
## avg.sentiment.neg.response 0.0000000 -0.1000000 0.10000000
-
## PositivityLM RatioUncertaintyLM SentimentQDAP
-
## cor 0.6305283 NA 0.9865356369
-
## cor.t.statistic 1.6247248 NA 12.0642877257
-
## cor.p.value 0.1795458 NA 0.0002707131
-
## lm.t.value 1.6247248 NA 12.0642877257
-
## r.squared 0.3975659 NA 0.9732525629
-
## RMSE 0.7757911 0.9128709 0.5398902495
-
## MAE 0.7222222 0.8333333 0.4888888889
-
## Accuracy 0.6666667 0.6666667 1.0000000000
-
## Precision NaN NaN 1.0000000000
-
## Sensitivity 0.0000000 0.0000000 1.0000000000
-
## Specificity 1.0000000 1.0000000 1.0000000000
-
## F1 0.0000000 0.0000000 0.5000000000
-
## BalancedAccuracy 0.5000000 0.5000000 1.0000000000
-
## avg.sentiment.pos.response 0.3333333 0.0000000 0.3333333333
-
## avg.sentiment.neg.response 0.0000000 0.0000000 -0.3666666667
-
## NegativityQDAP PositivityQDAP
-
## cor -0.944339551 0.942954167
-
## cor.t.statistic -5.741148345 5.664705543
-
## cor.p.value 0.004560908 0.004788521
-
## lm.t.value -5.741148345 5.664705543
-
## r.squared 0.891777188 0.889162562
-
## RMSE 1.068401367 0.713624032
-
## MAE 1.011111111 0.666666667
-
## Accuracy 0.666666667 0.666666667
-
## Precision NaN NaN
-
## Sensitivity 0.000000000 0.000000000
-
## Specificity 1.000000000 1.000000000
-
## F1 0.000000000 0.000000000
-
## BalancedAccuracy 0.500000000 0.500000000
-
## avg.sentiment.pos.response 0.083333333 0.416666667
-
## avg.sentiment.neg.response 0.366666667 0.000000000
-
## WordCount SentimentGI NegativityGI PositivityGI
-
## Accuracy 0.6666667 1.0000000 0.66666667 0.6666667
-
## Precision NaN 1.0000000 NaN NaN
-
## Sensitivity 0.0000000 1.0000000 0.00000000 0.0000000
-
## Specificity 1.0000000 1.0000000 1.00000000 1.0000000
-
## F1 0.0000000 0.5000000 0.00000000 0.0000000
-
## BalancedAccuracy 0.5000000 1.0000000 0.50000000 0.5000000
-
## avg.sentiment.pos.response 3.2500000 0.3333333 0.08333333 0.4166667
-
## avg.sentiment.neg.response 4.0000000 -0.6333333 0.63333333 0.0000000
-
## SentimentHE NegativityHE PositivityHE
-
## Accuracy 0.6666667 0.66666667 0.6666667
-
## Precision NaN NaN NaN
-
## Sensitivity 0.0000000 0.00000000 0.0000000
-
## Specificity 1.0000000 1.00000000 1.0000000
-
## F1 0.0000000 0.00000000 0.0000000
-
## BalancedAccuracy 0.5000000 0.50000000 0.5000000
-
## avg.sentiment.pos.response 0.1250000 0.08333333 0.2083333
-
## avg.sentiment.neg.response 0.0000000 0.00000000 0.0000000
-
## SentimentLM NegativityLM PositivityLM
-
## Accuracy 0.8333333 0.66666667 0.6666667
-
## Precision 1.0000000 NaN NaN
-
## Sensitivity 0.5000000 0.00000000 0.0000000
-
## Specificity 1.0000000 1.00000000 1.0000000
-
## F1 0.3333333 0.00000000 0.0000000
-
## BalancedAccuracy 0.7500000 0.50000000 0.5000000
-
## avg.sentiment.pos.response 0.2500000 0.08333333 0.3333333
-
## avg.sentiment.neg.response -0.1000000 0.10000000 0.0000000
-
## RatioUncertaintyLM SentimentQDAP NegativityQDAP
-
## Accuracy 0.6666667 1.0000000 0.66666667
-
## Precision NaN 1.0000000 NaN
-
## Sensitivity 0.0000000 1.0000000 0.00000000
-
## Specificity 1.0000000 1.0000000 1.00000000
-
## F1 0.0000000 0.5000000 0.00000000
-
## BalancedAccuracy 0.5000000 1.0000000 0.50000000
-
## avg.sentiment.pos.response 0.0000000 0.3333333 0.08333333
-
## avg.sentiment.neg.response 0.0000000 -0.3666667 0.36666667
-
## PositivityQDAP
-
## Accuracy 0.6666667
-
## Precision NaN
-
## Sensitivity 0.0000000
-
## Specificity 1.0000000
-
## F1 0.0000000
-
## BalancedAccuracy 0.5000000
-
## avg.sentiment.pos.response 0.4166667
-
## avg.sentiment.neg.response 0.0000000
从文本挖掘中执行了一组预处理操作。将标记每个文档,最后将输入转换为文档项矩阵。
输入
提供了具有其他几种输入格式的接口,其中包括
-
字符串向量。
-
在
tm软件包中实现的DocumentTermMatrix和 TermDocumentMatrix(Feinerer,Hornik和Meyer 2008)。 -
tm软件包实现的语料库对象 (Feinerer,Hornik和Meyer 2008)。
我们在下面提供示例。
向量的字符串
-
documents <- c("这很好",
-
-
"这不好",
-
-
"这介于两者之间")
-
convertToDirection(analyzeSentiment(documents)$SentimentQDAP)
-
## [1] positive negative neutral
-
## Levels: negative neutral positive
文档词语矩阵
-
corpus <- VCorpus(VectorSource(documents))
-
convertToDirection(analyzeSentiment(corpus)$SentimentQDAP)
-
## [1] positive negative neutral
-
## Levels: negative neutral positive
语料库对象
-
## [1] positive negative neutral
-
## Levels: negative neutral positive
可以直接与文档术语矩阵一起使用,因此一开始就可以使用自定义的预处理操作。之后,可以计算情感分数。例如,可以使用其他列表中的停用词替换停用词。
字典
可区分三种不同类型的词典。它们所存储的数据各不相同,这些数据最终还控制着可以应用哪种情感分析方法。字典如下:
-
SentimentDictionaryWordlist包含属于一个类别的单词列表。 -
SentimentDictionaryBinary存储两个单词列表,一个用于肯定条目,一个用于否定条目。 -
SentimentDictionaryWeighted允许单词的情感评分。
情感词典词表
-
# 替代
-
-
d <- Dictionary(c(“不确定”,“可能”,“有可能”))
-
summary(d)
-
## Dictionary type: word list (single set)
-
## Total entries: 3
情感词典
-
d <- DictionaryBin(c(“增加”,“上升”,“更多”),
-
c(“下降”))
-
summary(d)
-
## Dictionary type: binary (positive / negative)
-
## Total entries: 5
-
## Positive entries: 3 (60%)
-
## Negative entries: 2 (40%)
情感词典加权
-
d <- SentimentDictionaryWeighted(c(“增加”,“减少”,“退出”),
-
c(+1, -1, -10),
-
rep(NA, 3))
-
summary(d)
-
## Dictionary type: weighted (words with individual scores)
-
## Total entries: 3
-
## Positive entries: 1 (33.33%)
-
## Negative entries: 2 (66.67%)
-
## Neutral entries: 0 (0%)
-
##
-
## Details
-
## Average score: -3.333333
-
## Median: -1
-
## Min: -10
-
## Max: 1
-
## Standard deviation: 5.859465
-
## Skewness: -0.6155602
-
d <- SentimentDictionary(c(“增加”,“减少”,“退出”),
-
c(+1, -1, -10),
-
rep(NA, 3))
-
summary(d)
-
## Dictionary type: weighted (words with individual scores)
-
## Total entries: 3
-
## Positive entries: 1 (33.33%)
-
## Negative entries: 2 (66.67%)
-
## Neutral entries: 0 (0%)
-
##
-
## Details
-
## Average score: -3.333333
-
## Median: -1
-
## Min: -10
-
## Max: 1
-
## Standard deviation: 5.859465
-
## Skewness: -0.6155602
字典生成
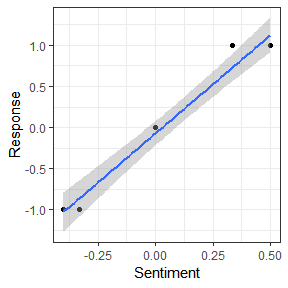
用向量的形式表示因变量。此外,变量给出了单词在文档中出现的次数。然后,该方法估计具有截距和系数的线性模型。估计基于LASSO正则化,它执行变量选择。这样,它将某些系数设置为正好为零。然后可以根据剩余单词的系数按极性对它们进行排序。
-
# 创建字符串向量
-
-
-
documents <- c(“这是一件好事!”,
-
-
“这是一件非常好的事!”,
-
-
“没关系。”
-
-
“这是一件坏事。”,
-
-
“这是一件非常不好的事情。”
-
-
)
-
response <- c(1, 0.5, 0, -0.5, -1)
-
-
# 使用LASSO正则化生成字典
-
-
-
dict
-
## Type: weighted (words with individual scores)
-
## Intercept: 5.55333e-05
-
## -0.51 bad
-
## 0.51 good
summary(dict)-
## Dictionary type: weighted (words with individual scores)
-
## Total entries: 2
-
## Positive entries: 1 (50%)
-
## Negative entries: 1 (50%)
-
## Neutral entries: 0 (0%)
-
##
-
## Details
-
## Average score: -5.251165e-05
-
## Median: -5.251165e-05
-
## Min: -0.5119851
-
## Max: 0.5118801
-
## Standard deviation: 0.7239821
-
## Skewness: 0
有几种微调选项。只需更改参数,就可以用弹性网络模型替换LASSO 。
最后,可以使用read() 和 保存和重新加载字典 write()
评估
最终,例程允许人们进一步挖掘生成的字典。一方面,可以通过summary() 例程显示简单的概述 。另一方面,核密度估计也可以可视化正词和负词的分布。
-
## Comparing: wordlist vs weighted
-
##
-
## Total unique words: 4213
-
## Matching entries: 2 (0.0004747211%)
-
## Entries with same classification: 0 (0%)
-
## Entries with different classification: 2 (0.0004747211%)
-
## Correlation between scores of matching entries: 1
-
## $totalUniqueWords
-
## [1] 4213
-
##
-
## $totalSameWords
-
## [1] 2
-
##
-
## $ratioSameWords
-
## [1] 0.0004747211
-
##
-
## $numWordsEqualClass
-
## [1] 0
-
##
-
## $numWordsDifferentClass
-
## [1] 2
-
##
-
## $ratioWordsEqualClass
-
## [1] 0
-
##
-
## $ratioWordsDifferentClass
-
## [1] 0.0004747211
-
##
-
## $correlation
-
## [1] 1
-
## Dictionary
-
## cor 0.94868330
-
## cor.t.statistic 5.19615237
-
## cor.p.value 0.01384683
-
## lm.t.value 5.19615237
-
## r.squared 0.90000000
-
## RMSE 0.23301039
-
## MAE 0.20001111
-
## Accuracy 1.00000000
-
## Precision 1.00000000
-
## Sensitivity 1.00000000
-
## Specificity 1.00000000
-
## F1 0.57142857
-
## BalancedAccuracy 1.00000000
-
## avg.sentiment.pos.response 0.45116801
-
## avg.sentiment.neg.response -0.67675202
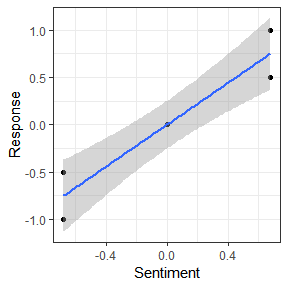
下面的示例演示如何将计算出的字典用于预测样本外数据的情感。然后通过将其与内置词典进行比较来评估预测性能。
-
test_documents <- c(“这既不是好事也不是坏事”,
-
-
“真是好主意!”,
-
-
“不错”
-
)
-
-
pred <- predict(dict, test_documents)
-
-
## Dictionary
-
## cor 5.922189e-05
-
## cor.t.statistic 5.922189e-05
-
## cor.p.value 9.999623e-01
-
## lm.t.value 5.922189e-05
-
## r.squared 3.507232e-09
-
## RMSE 8.523018e-01
-
## MAE 6.666521e-01
-
## Accuracy 3.333333e-01
-
## Precision 0.000000e+00
-
## Sensitivity NaN
-
## Specificity 3.333333e-01
-
## F1 0.000000e+00
-
## BalancedAccuracy NaN
-
## avg.sentiment.pos.response 1.457684e-05
-
## avg.sentiment.neg.response NaN
-
## WordCount SentimentGI NegativityGI
-
## cor -0.8660254 -0.18898224 0.18898224
-
## cor.t.statistic -1.7320508 -0.19245009 0.19245009
-
## cor.p.value 0.3333333 0.87896228 0.87896228
-
## lm.t.value -1.7320508 -0.19245009 0.19245009
-
## r.squared 0.7500000 0.03571429 0.03571429
-
## RMSE 1.8257419 1.19023807 0.60858062
-
## MAE 1.3333333 0.83333333 0.44444444
-
## Accuracy 1.0000000 0.66666667 1.00000000
-
## Precision NaN 0.00000000 NaN
-
## Sensitivity NaN NaN NaN
-
## Specificity 1.0000000 0.66666667 1.00000000
-
## F1 0.0000000 0.00000000 0.00000000
-
## BalancedAccuracy NaN NaN NaN
-
## avg.sentiment.pos.response 2.0000000 -0.16666667 0.44444444
-
## avg.sentiment.neg.response NaN NaN NaN
-
## PositivityGI SentimentHE NegativityHE
-
## cor -0.18898224 -0.18898224 NA
-
## cor.t.statistic -0.19245009 -0.19245009 NA
-
## cor.p.value 0.87896228 0.87896228 NA
-
## lm.t.value -0.19245009 -0.19245009 NA
-
## r.squared 0.03571429 0.03571429 NA
-
## RMSE 0.67357531 0.67357531 0.8164966
-
## MAE 0.61111111 0.61111111 0.6666667
-
## Accuracy 1.00000000 1.00000000 1.0000000
-
## Precision NaN NaN NaN
-
## Sensitivity NaN NaN NaN
-
## Specificity 1.00000000 1.00000000 1.0000000
-
## F1 0.00000000 0.00000000 0.0000000
-
## BalancedAccuracy NaN NaN NaN
-
## avg.sentiment.pos.response 0.27777778 0.27777778 0.0000000
-
## avg.sentiment.neg.response NaN NaN NaN
-
## PositivityHE SentimentLM NegativityLM
-
## cor -0.18898224 -0.18898224 0.18898224
-
## cor.t.statistic -0.19245009 -0.19245009 0.19245009
-
## cor.p.value 0.87896228 0.87896228 0.87896228
-
## lm.t.value -0.19245009 -0.19245009 0.19245009
-
## r.squared 0.03571429 0.03571429 0.03571429
-
## RMSE 0.67357531 1.19023807 0.60858062
-
## MAE 0.61111111 0.83333333 0.44444444
-
## Accuracy 1.00000000 0.66666667 1.00000000
-
## Precision NaN 0.00000000 NaN
-
## Sensitivity NaN NaN NaN
-
## Specificity 1.00000000 0.66666667 1.00000000
-
## F1 0.00000000 0.00000000 0.00000000
-
## BalancedAccuracy NaN NaN NaN
-
## avg.sentiment.pos.response 0.27777778 -0.16666667 0.44444444
-
## avg.sentiment.neg.response NaN NaN NaN
-
## PositivityLM RatioUncertaintyLM SentimentQDAP
-
## cor -0.18898224 NA -0.18898224
-
## cor.t.statistic -0.19245009 NA -0.19245009
-
## cor.p.value 0.87896228 NA 0.87896228
-
## lm.t.value -0.19245009 NA -0.19245009
-
## r.squared 0.03571429 NA 0.03571429
-
## RMSE 0.67357531 0.8164966 1.19023807
-
## MAE 0.61111111 0.6666667 0.83333333
-
## Accuracy 1.00000000 1.0000000 0.66666667
-
## Precision NaN NaN 0.00000000
-
## Sensitivity NaN NaN NaN
-
## Specificity 1.00000000 1.0000000 0.66666667
-
## F1 0.00000000 0.0000000 0.00000000
-
## BalancedAccuracy NaN NaN NaN
-
## avg.sentiment.pos.response 0.27777778 0.0000000 -0.16666667
-
## avg.sentiment.neg.response NaN NaN NaN
-
## NegativityQDAP PositivityQDAP
-
## cor 0.18898224 -0.18898224
-
## cor.t.statistic 0.19245009 -0.19245009
-
## cor.p.value 0.87896228 0.87896228
-
## lm.t.value 0.19245009 -0.19245009
-
## r.squared 0.03571429 0.03571429
-
## RMSE 0.60858062 0.67357531
-
## MAE 0.44444444 0.61111111
-
## Accuracy 1.00000000 1.00000000
-
## Precision NaN NaN
-
## Sensitivity NaN NaN
-
## Specificity 1.00000000 1.00000000
-
## F1 0.00000000 0.00000000
-
## BalancedAccuracy NaN NaN
-
## avg.sentiment.pos.response 0.44444444 0.27777778
-
## avg.sentiment.neg.response NaN NaN
预处理
如果需要,可以实施适合特定需求的预处理阶段。如函数 ngram_tokenize() ,用于从语料库中提取n-gram。
-
tdm <- TermDocumentMatrix(corpus,
-
control=list(wordLengths=c(1,Inf),
-
tokenize=function(x) ngram_tokenize(x, char=FALSE,
-
ngmin=1, ngmax=2)))
-
## Dictionary type: weighted (words with individual scores)
-
## Total entries: 7
-
## Positive entries: 4 (57.14%)
-
## Negative entries: 3 (42.86%)
-
## Neutral entries: 0 (0%)
-
##
-
## Details
-
## Average score: 5.814314e-06
-
## Median: 1.602469e-16
-
## Min: -0.4372794
-
## Max: 0.4381048
-
## Standard deviation: 0.301723
-
## Skewness: 0.00276835
dict-
## Type: weighted (words with individual scores)
-
## Intercept: -5.102483e-05
-
## -0.44 不好
-
## -0.29 非常糟糕
-
## 0.29 好
-
-
性能优化
-
## SentimentLM
-
## 1 0.5
-
## 2 0.5
-
## 3 0.0
-
## 4 -0.5
-
## 5 -0.5
语言支持和可扩展性
可以适应其他语言使用。为此,需要在两点上进行更改:
-
预处理:使用参数
language=""来执行所有预处理操作。 -
字典: 可以使用附带的字典生成方法 。然后,这可以自动生成可应用于给定语言的正负词词典。
下面的示例使用德语示例。最后,我们进行情感分析。
-
documents <- c("Das ist ein gutes Resultat",
-
"Das Ergebnis war schlecht")
-
-
sentiment <- ana(documents,
-
language="german",
-
sentiment
-
## GermanSentiment
-
## 1 0.0
-
## 2 -0.5
-
## [1] positive negative
-
## Levels: negative positive
同样,可以使用自定义情感分数来实现字典。
-
woorden <- c("goed","slecht")
-
scores <- c(0.8,-0.5)
-
## DutchSentiment
-
## 1 -0.5
实例
我们利用了tm 包中的路透社石油新闻 。
-
-
# 分析情感
-
-
-
sentiment <- ana(crude)
-
-
# 计算正面和负面新闻发布数量
-
-
-
table(coToB(sentiment$SentimentLM))
-
##
-
## negative positive
-
## 16 4
-
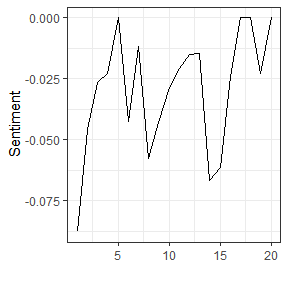
# 情感最高和最低的新闻
-
## [1] "HOUSTON OIL <HO> RESERVES STUDY COMPLETED"crude[[which.min(sentiment$SentimentLM)]]$meta$heading## [1] "DIAMOND SHAMROCK (DIA) CUTS CRUDE PRICES"-
# 查看情感变量的摘要统计
-
-
-
summary(sentiment$SentimentLM)
-
## Min. 1st Qu. Median Mean 3rd Qu. Max.
-
## -0.08772 -0.04366 -0.02341 -0.02953 -0.01375 0.00000
-
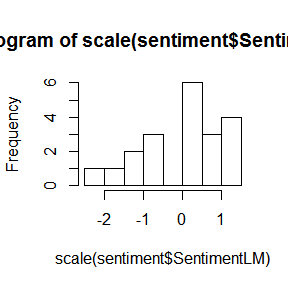
# 可视化标准化情感变量的分布
-
-
-
hist(scale(sentiment$SentimentLM))
# 计算相关
-
## SentimentLM SentimentHE SentimentQDAP
-
## SentimentLM 1.0000000 0.2769878 0.4769730
-
## SentimentHE 0.2769878 1.0000000 0.6141075
-
## SentimentQDAP 0.4769730 0.6141075 1.0000000
-
# 1987-02-26 1987-03-02之间的原油新闻
-
-
-
plot(senti$Sentime)
plot(SenLM, x=date, cumsum=TRUE)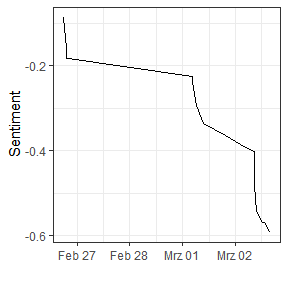
单词计算
对单词进行计数 。
#词(无停用词)
-
## WordCount
-
## 1 3
# 计算所有单词(包括停用词)
-
## WordCount
-
## 1 4
参考文献
Feinerer,Ingo,Kurt Hornik和David Meyer。2008年。“ R中的文本挖掘基础结构”。 统计软件杂志 25(5):1–54。
Tetlock,Paul C.,2007年。“将内容传递给投资者的情感:媒体在股票市场中的作用。” 金融杂志 62(3):1139–68。

最受欢迎的见解
3.r语言文本挖掘tf-idf主题建模,情感分析n-gram建模研究
4.python主题建模可视化lda和t-sne交互式可视化