原文链接:http://tecdat.cn/?p=23151
原文出处:拓端数据部落公众号
这个例子展示了如何使用深度学习长短期记忆(LSTM)网络对文本数据进行分类。
文本数据是有顺序的。一段文字是一个词的序列,它们之间可能有依赖关系。为了学习和使用长期依赖关系来对序列数据进行分类,可以使用LSTM神经网络。LSTM网络是一种递归神经网络(RNN),可以学习序列数据的时间顺序之间的长期依赖关系。
要向LSTM网络输入文本,首先要将文本数据转换成数字序列。你可以使用单词编码来实现这一点,该编码将文件映射为数字指数的序列。为了获得更好的结果,还可以在网络中加入一个词嵌入层。词汇嵌入将词汇映射为数字向量,而不是标量索引。这些嵌入发现了单词的语义细节,因此具有相似含义的单词具有相似的向量。它们还通过向量算术来模拟单词之间的关系。例如,"罗马之于意大利就像巴黎之于法国 "的关系由方程式意大利-罗马+巴黎=法国来描述。
在这个例子中,训练和使用LSTM网络有四个步骤。
- 导入并预处理数据。
- 使用单词编码将单词转换为数字序列。
- 创建并训练一个带有单词嵌入层的LSTM网络。
- 使用训练好的LSTM网络对新的文本数据进行分类。
导入数据
导入工厂报告数据。该数据包含对工厂事件的标签化文本描述。要把文本数据导入为字符串,指定文本类型为 "字符串"。
-
-
head(data)

这个例子的目的是通过类别栏中的标签对事件进行分类。为了将数据划分为类别,将这些标签转换为分类的。
Category = categorical(Category);使用直方图查看数据中的类别分布。
-
figure
-
histogram(Category);
下一步是将其划分为训练和验证的集合。将数据划分为一个训练分区和一个用于验证和测试的保留分区。指定保留的百分比为20%。
cvp = cv(Category,'Holdout',0.2);
从分区的表中提取文本数据和标签。
-
DataTrain = Description;
-
DataValidation = Description;
为了检查你是否正确地导入了数据,可以用词云来可视化训练文本数据。
wordcloud(DataTrain);
预处理文本数据
创建一个函数,对文本数据进行标记和预处理。列在例子末尾的函数preprocessText,执行这些步骤。
- 使用tokenizedDocument对文本进行标记。
- 使用lower将文本转换为小写。
- 使用 erasePunctuation 擦除标点符号。
对训练数据和验证数据进行预处理。
Train = preprocessText(DataTrain);
查看最初几个预处理的训练文件。
documentsTrain(1:5)

将文件转换为序列
为了将文档输入到LSTM网络中,使用一个单词编码将文档转换为数字指数序列。
创建一个词的编码
下一个转换步骤是对文件进行填充和截断,使它们的长度都相同。
要填充和截断文件,首先要选择一个目标长度,然后截断比它长的文件,左移比它短的文件。为了达到最佳效果,目标长度应该很短,而不会丢弃大量的数据。为了找到一个合适的目标长度,可以查看训练文档长度的直方图。
-
-
histogram(documentLengths)
大多数的训练文件都少于10个标记。将此作为截断和填充的目标长度。
将文档转换为数字索引序列。要截断或向左填充序列的长度为10,将 "长度 "选项设置为10。
-
doc2sequence(enc,'Length');
-

使用相同的选项将验证文件转换为序列。
sequence(Length);创建和训练LSTM网络
定义LSTM网络结构。为了向网络输入序列数据,包括一个序列输入层,并将输入大小设置为1。接下来,包括一个维度为50的词嵌入层,词的数量与词的编码相同。接下来,包括一个LSTM层,并将隐藏单元的数量设置为80。最后,添加一个与类的数量相同的全连接层,一个softmax层,以及一个分类层。
-
inputSize = 1;
-
Dimension = 50;
-
HiddenUnits = 80;

指定训练选项
-
使用Adam优化器进行训练.
-
指定一个16的小批处理量。
-
每隔一段时间对数据进行随机化。
-
通过设置 "Plots "选项为 "training-progress "来监测训练进度。
-
使用'ValidationData'选项指定验证数据。
-
通过将'Verbose'选项设置为false来抑制输出。
默认情况下,如果有GPU,会使用GPU(需要并行计算工具箱™和支持CUDA®的计算能力3.0以上的GPU)。否则,它将使用CPU。在CPU上训练的时间可能比在GPU上训练的时间长很多。
-
options('adam', ...
-
'BatchSize',16, ...
-
'Shuffle','every-epoch', ...);
训练LSTM网络。
使用新数据进行预测
对三个新报告的事件类型进行分类。创建一个包含新报告的字符串数组。
使用预处理步骤对文本数据进行预处理,作为训练文档。
preprocessText(New);将文本数据转换为序列,选项与创建训练序列时相同。
sequence(enc,sequenceLength);使用训练好的LSTM网络对新序列进行分类。
-
classify(XNew)
-
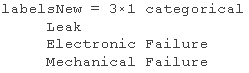

最受欢迎的见解
3.r语言文本挖掘tf-idf主题建模,情感分析n-gram建模研究
4.python主题建模可视化lda和t-sne交互式可视化