原文链接: http://tecdat.cn/?p=23312
原文出处:拓端数据部落公众号
引言
结构方程模型是一个线性模型框架,它对潜变量同时进行回归方程建模。 诸如线性回归、多元回归、路径分析、确认性因子分析和结构回归等模型都可以被认为是SEM的特例。在SEM中可能存在以下关系。
- 观察到的变量与观察到的变量之间的关系(γ,如回归)。
- 潜变量与观察变量(λ,如确认性因子分析)。
- 潜变量与潜变量(γ,β,如结构回归)。
SEM独特地包含了测量和结构模型。测量模型将观测变量与潜变量联系起来,结构模型将潜变量与潜变量联系起来。目前有多种软件处理SEM模型,包括Mplus、EQS、SAS PROC CALIS、Stata的sem和最近的R的lavaan。R的好处是它是开源的,可以免费使用,而且相对容易使用。
本文将介绍属于SEM框架的最常见的模型,包括
- 简单回归
- 多元回归
- 多变量回归
- 路径分析
- 确认性因素分析
- 结构回归
目的是在每个模型中介绍其
- 矩阵表述
- 路径图
lavaan语法- 参数和输出
在这次训练结束时,你应该能够理解这些概念,足以正确识别模型,认识矩阵表述中的每个参数,并解释每个模型的输出。
语法简介
语法一:f3~f1+f2(路径模型)
结构方程模型的路径部分可以看作是一个回归方程。而在R中,回归方程可以表示为y~ax1+bx2+c,“~”的左边的因变量,右边是自变量,“+”把多个自变量组合在一起。那么把y看作是内生潜变量,把x看作是外生潜变量,略去截距,就构成了语法一。
语法二:f1 =~ item1 + item2 + item3(测量模型)
"=~"的左边是潜变量,右边是观测变量,整句理解为潜变量f1由观测变量item1、item2和item3表现。
语法三:item1 ~~ item1 , item1 ~~ item2
"~~"的两边相同,表示该变量的方差,不同的话表示两者的协方差
语法四:f1 ~ 1
表示截距
基础知识
加载数据
在这种情况下,我们将模拟数据。
-
y ~ .5*f #有外部标准的回归强度
-
-
-
f =~ .8*x1 + .8*x2 + .8*x3 + .8*x4 + .8*x5 #定义因子f,在5个项目上的载荷。
-
-
-
x1 ~~ (1-.8^2)*x1 #残差。请注意,通过使用1平方的载荷,我们在每个指标中实现了1.0的总变异性(标准化的)。
-
......
-
-
#产生数据;注意,标准化的lv是默认的
-
simData
-
-
#看一下数据
-
describe(simData)[,1:4]

指定模型
-
-
y ~ f # "~回归"
-
f =~ x1+ x2 + x3 + x4 + x5 # "=~被测量的是"
-
x1 ~~ x1 # 方差
-
x2 ~~ x2 #方差
-
x3~~x3 #变量
-
x4~~x4 #变量
-
x5~~x5 #变量
-
#x4~~x5将是协方差的一个例子
-
拟合模型
summary(model_m)

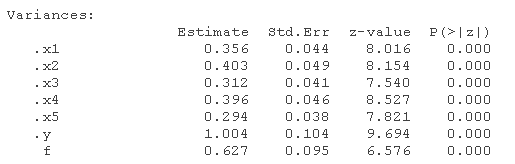
inspect(model_m)
Paths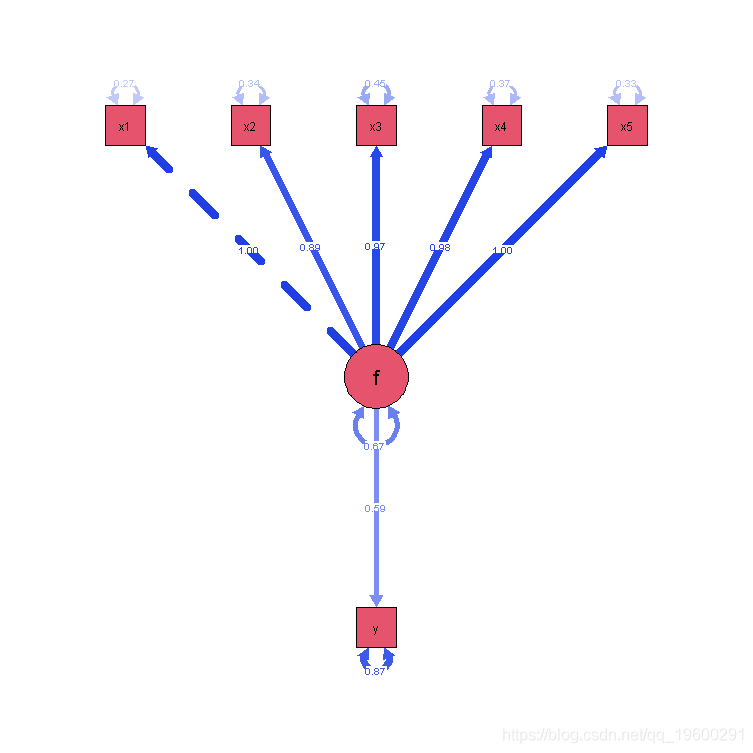
路径分析
与上述步骤相同,但主要侧重于回归路径。值得注意的是这种方法对调节分析的效用。
-
##加载数据
-
set.seed(1234)
-
-
Data <- data.frame(X = X, Y = Y, M = M)
指定模型
-
# 直接效应
-
Y ~ c*X #使用字符来命名回归路径
-
# 调节变量
-
M ~ a*X
-
Y ~ b*M
-
# 间接效应(a*b)
-
ab := a*b #定义新参数
-
# 总效应
-
total := c + (a*b) #使用":="定义新参数
-
拟合模型
summary(model_m)


Paths(model)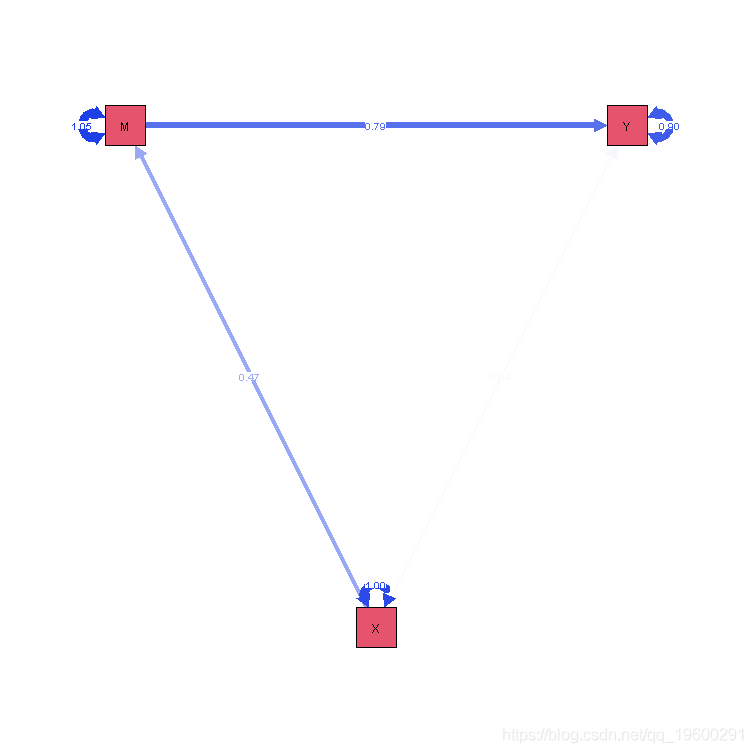
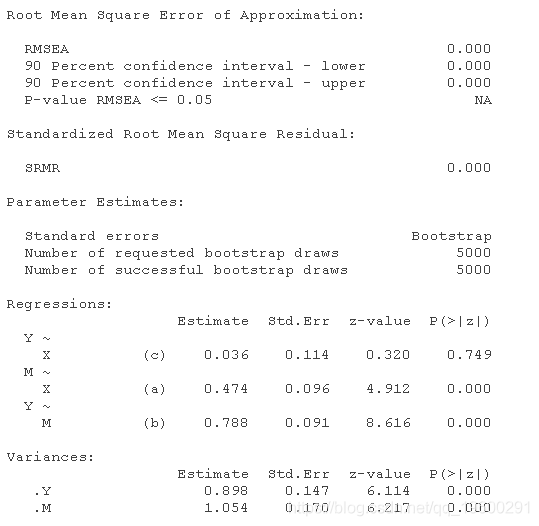
间接效应的Bootstrapping置信区间
除了指定对5000个样本的标准误差进行bootstrapping外,下面的语法还指出标准误差应进行偏差校正(但不是accelearted)。这种方法将产生与SPSS中的PROCESS宏程序类似的结果,即对标准误差进行偏差修正。
sem(medmodel,se = "bootstrap")


确认性因素分析
加载数据
我们将使用例子中的相同数据
指定模型
-
'
-
f =~ x1 + x2 + x3 +x4 + x5
-
x1~~x1
-
x2~~x2
-
x3~~x3
-
x4~~x4
-
x5~~x5
-
'
拟合模型
sem(fit, simData)
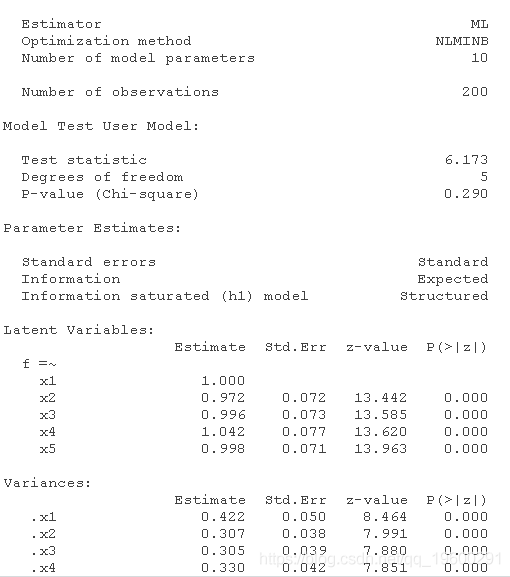
![]()
Paths(fit)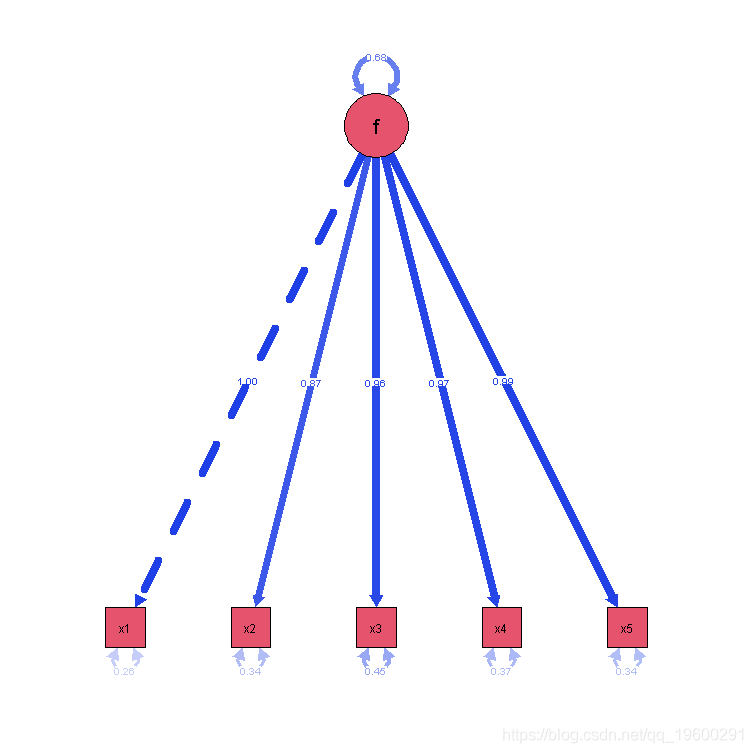
anova
正如各模型的LRT所示,sem()和cfa()是具有相同默认值的软件包。CFA可以很容易地使用cfa()或sem()完成 结构方程模型
加载数据
在这种情况下,我将模拟数据。
-
-
#结构成分
-
y ~ .5*f1 + .7*f2 #用外部标准回归的强度
-
-
-
#测量部分
-
f1 =~ .8*x1 + .6*x2 + .7*x3 + .8*x4 + .75*x5 #定义因子f,在5个项目上的载荷。
-
-
x1 ~~ (1-.8^2)*x1 #残差。注意,通过使用1平方的载荷,我们实现了每个指标的总变异性为1.0(标准化)。
-
...
-
-
#生成数据;注意,标准化的lv是默认的
-
sim <- sim(tosim)
-
-
#看一下数据
-
describe(sim )
-
指定模型
测试正确的模型
-
-
#结构性
-
y ~ f1+ f2
-
#测量
-
f1 =~ x1 + x2 + x3 + x4 + x5
-
f2 =~ x6 + x7
-
-
测试不正确的模型。假设我们错误地认为X4和X5负载于因子2。
-
-
incorrect
-
#结构性
-
y ~ f1+ f2
-
#测量
-
f1 =~ x1 + x2 + x3
-
f2 =~ x6 + x7 + x4 + x5
-
拟合模型
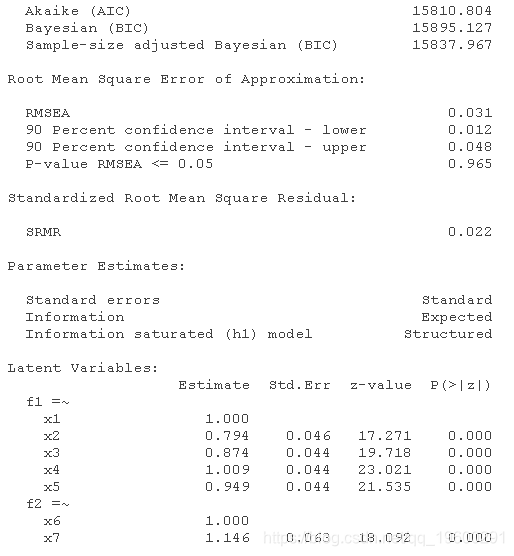
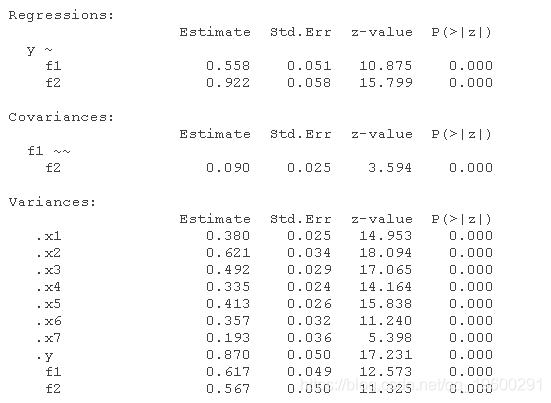
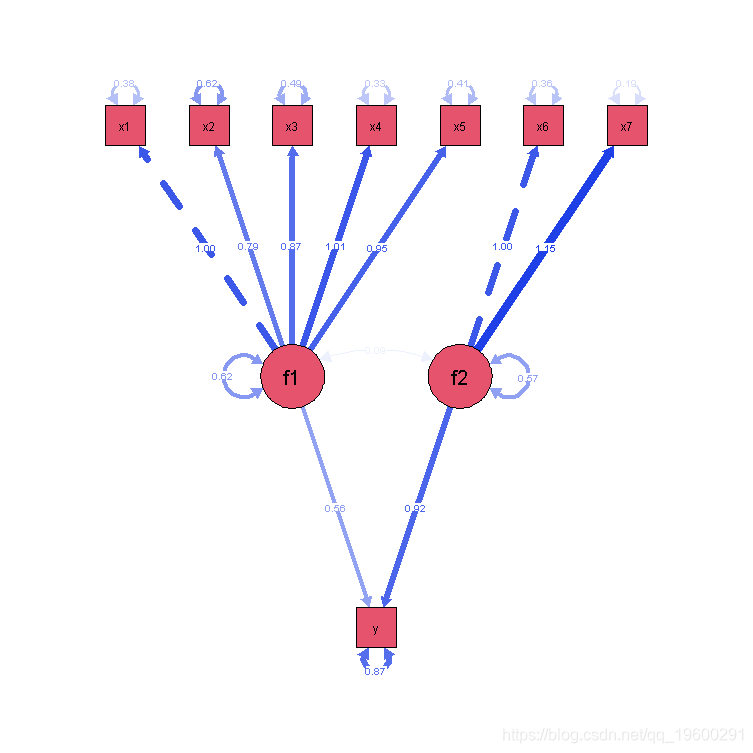
正确的模型
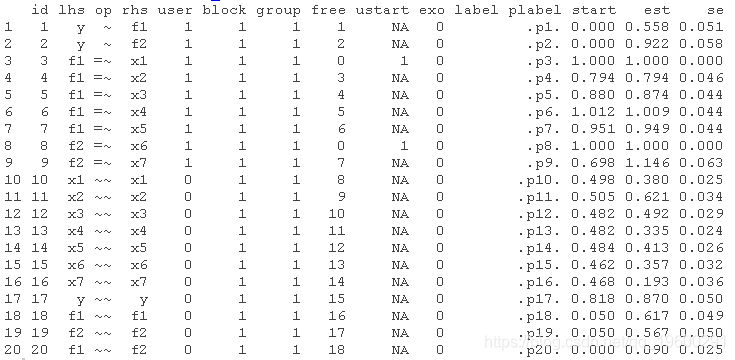
summary(model_m)
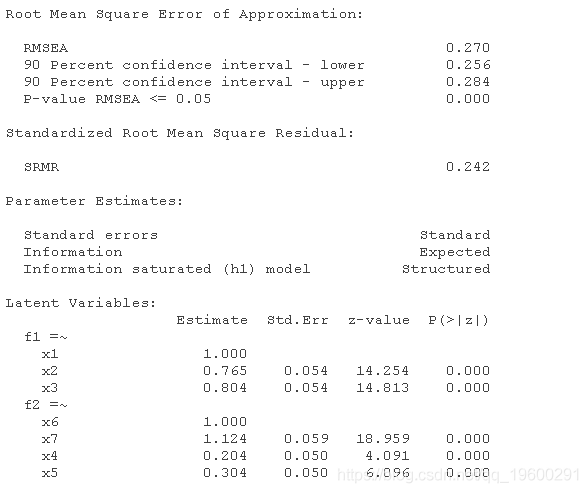
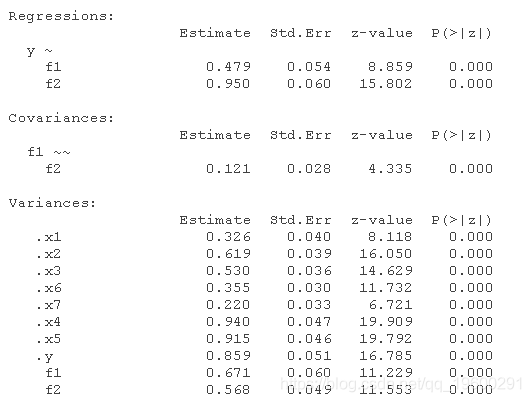
不正确的模型

summary(incorrectmodel_m, fit.measures = TRUE)
比较模型
正确模型
不正确模型
Paths(incorrec)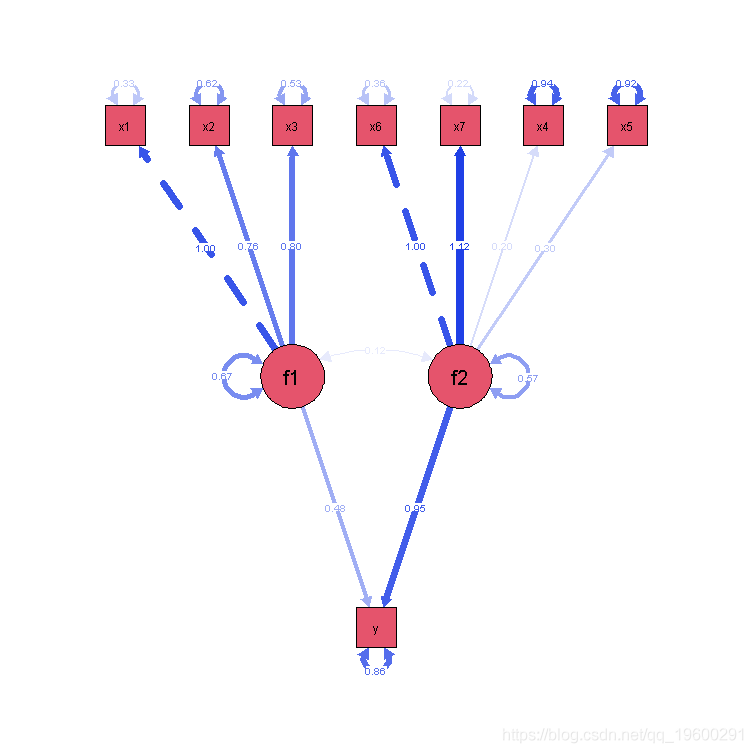
anova
除了不正确模型的整体拟合指数较差--如CFI<0.95,RMSEA>0.06,SRMR>0.08和Chi-square test<0.05所示,正确模型也优于不正确模型,如正确模型的AIC和BIC低得多所示。

最受欢迎的见解
3.matlab中的偏最小二乘回归(PLSR)和主成分回归(PCR)
6.r语言中对LASSO回归,Ridge岭回归和Elastic Net模型实现