原文链接:http://tecdat.cn/?p=23825
原文出处:拓端数据部落公众号
简介
本文介绍了基于有限正态混合模型在r软件中的实现,用于基于模型的聚类、分类和密度估计。提供了通过EM算法对具有各种协方差结构的正态混合模型进行参数估计的函数,以及根据这些模型进行模拟的函数。此外,还包括将基于模型的分层聚类、混合分布估计的EM和贝叶斯信息准则(BIC)结合在一起的功能,用于聚类、密度估计和判别分析的综合策略。其他功能可用于显示和可视化拟合模型以及聚类、分类和密度估计结果。
聚类
-
-
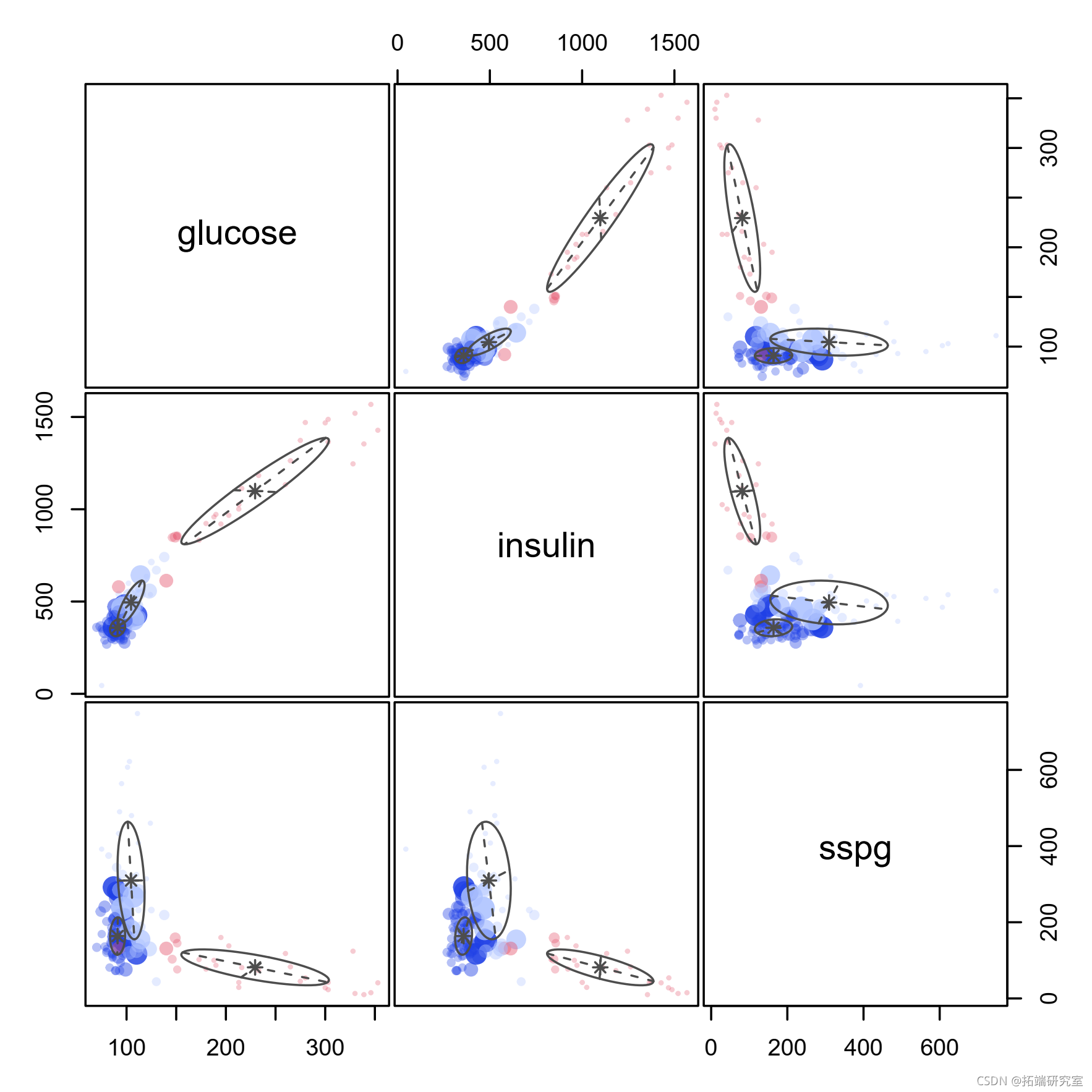
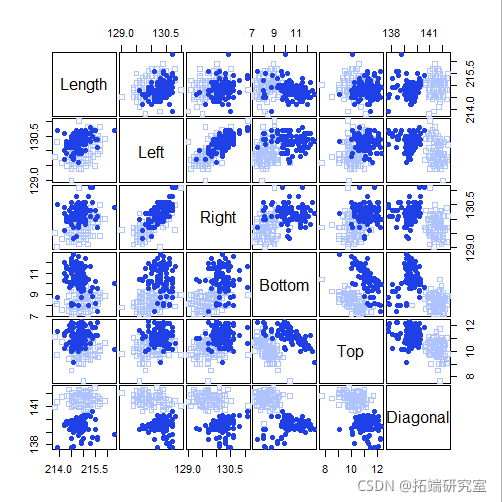
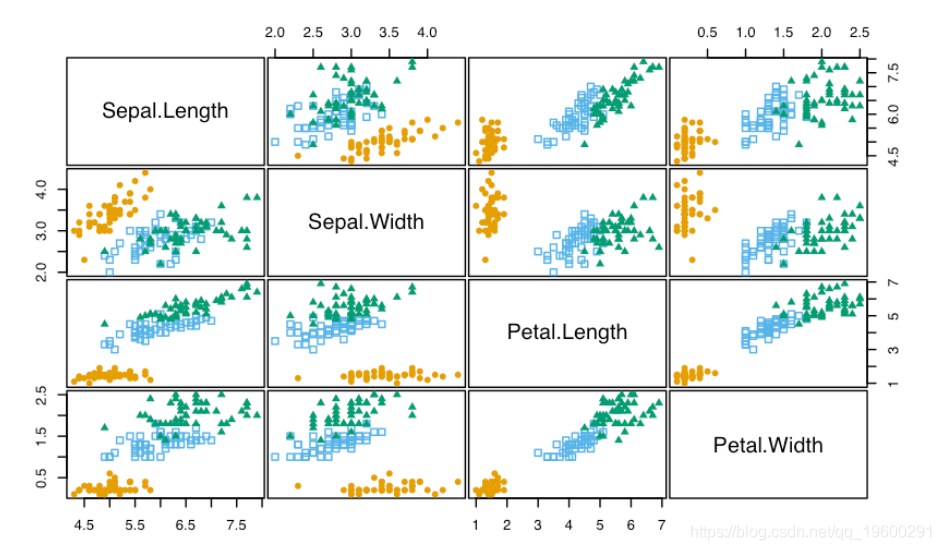
head(X)
pairs(X)
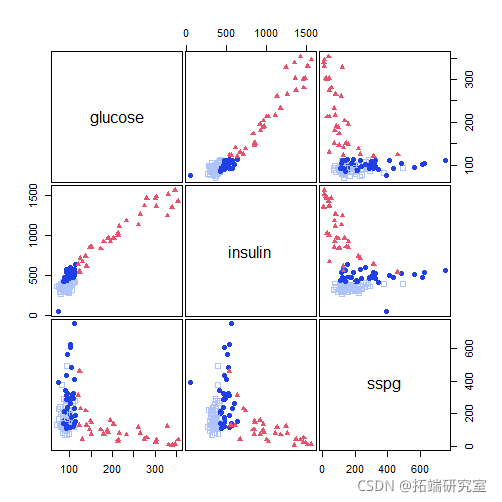
-
-
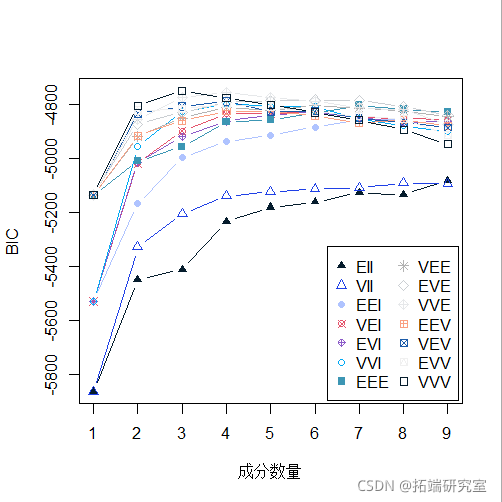
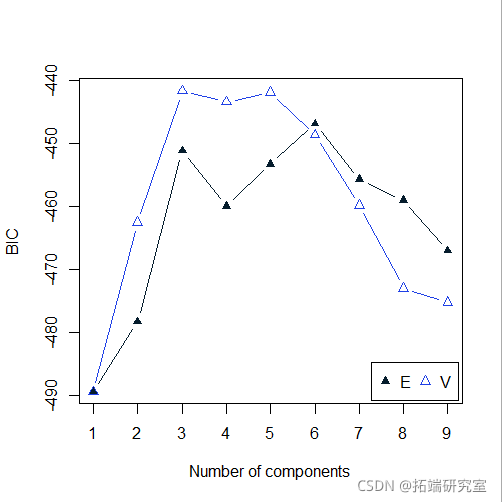
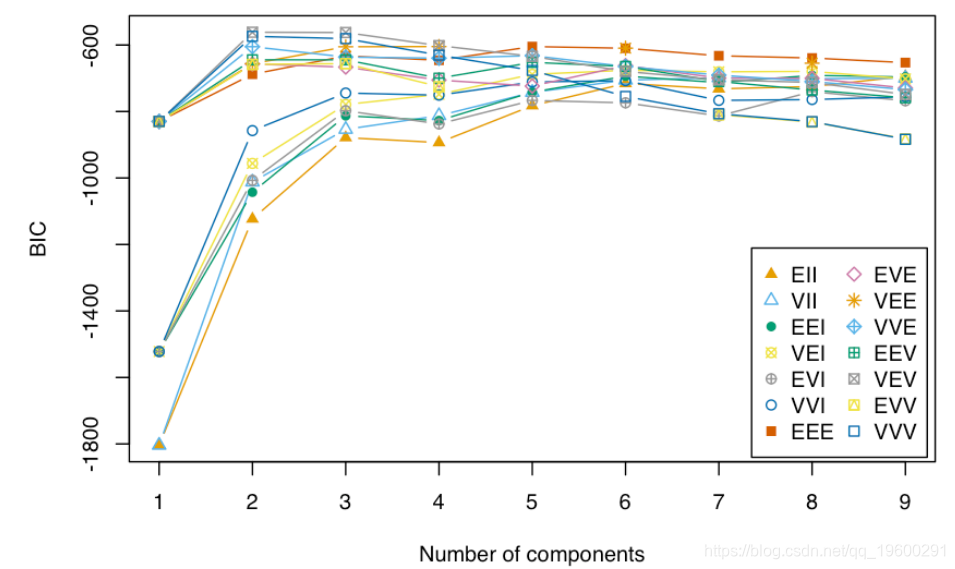
plot(BIC)
-
-
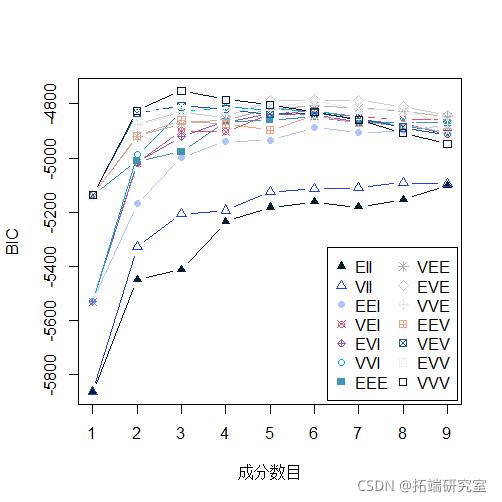
-
-
-
summary(BIC)

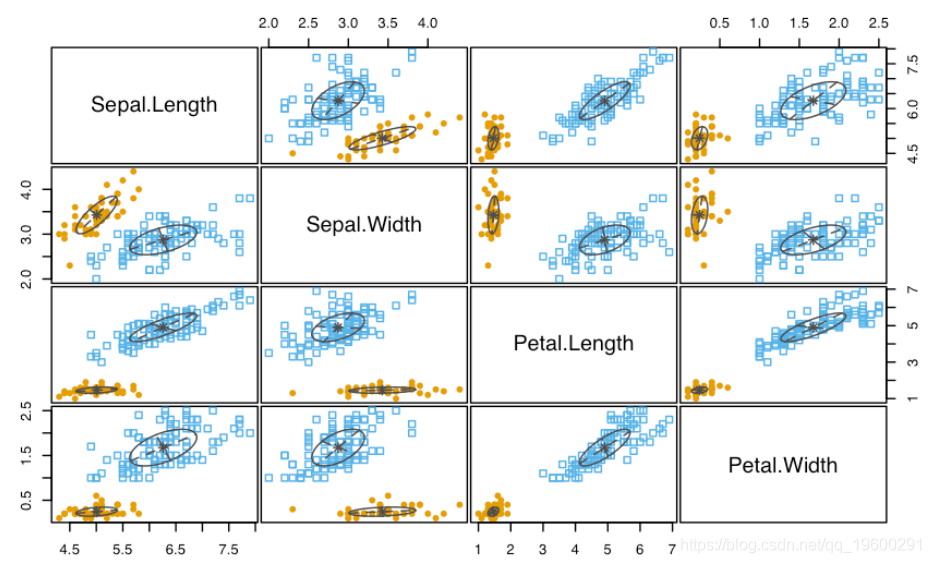
summary(mod1, parameters = TRUE)
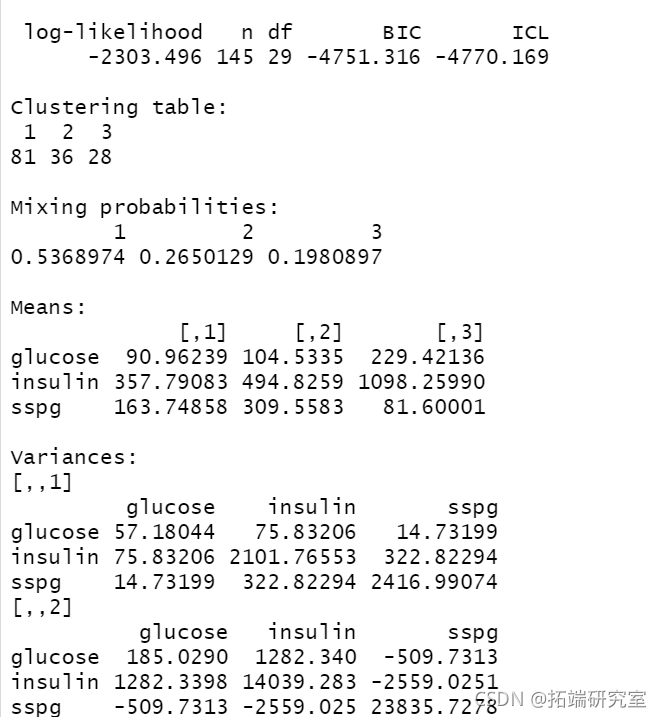

plot(mod1)
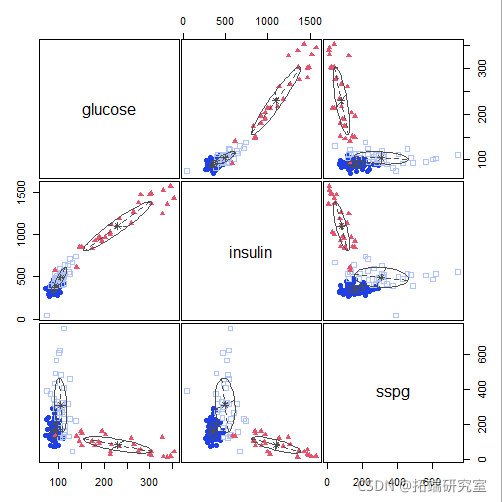
-
table(class, classification)
-
-
-
plot(mod1, what = "uncertainty")
-
clustICL(X)
-
summary(ICL)
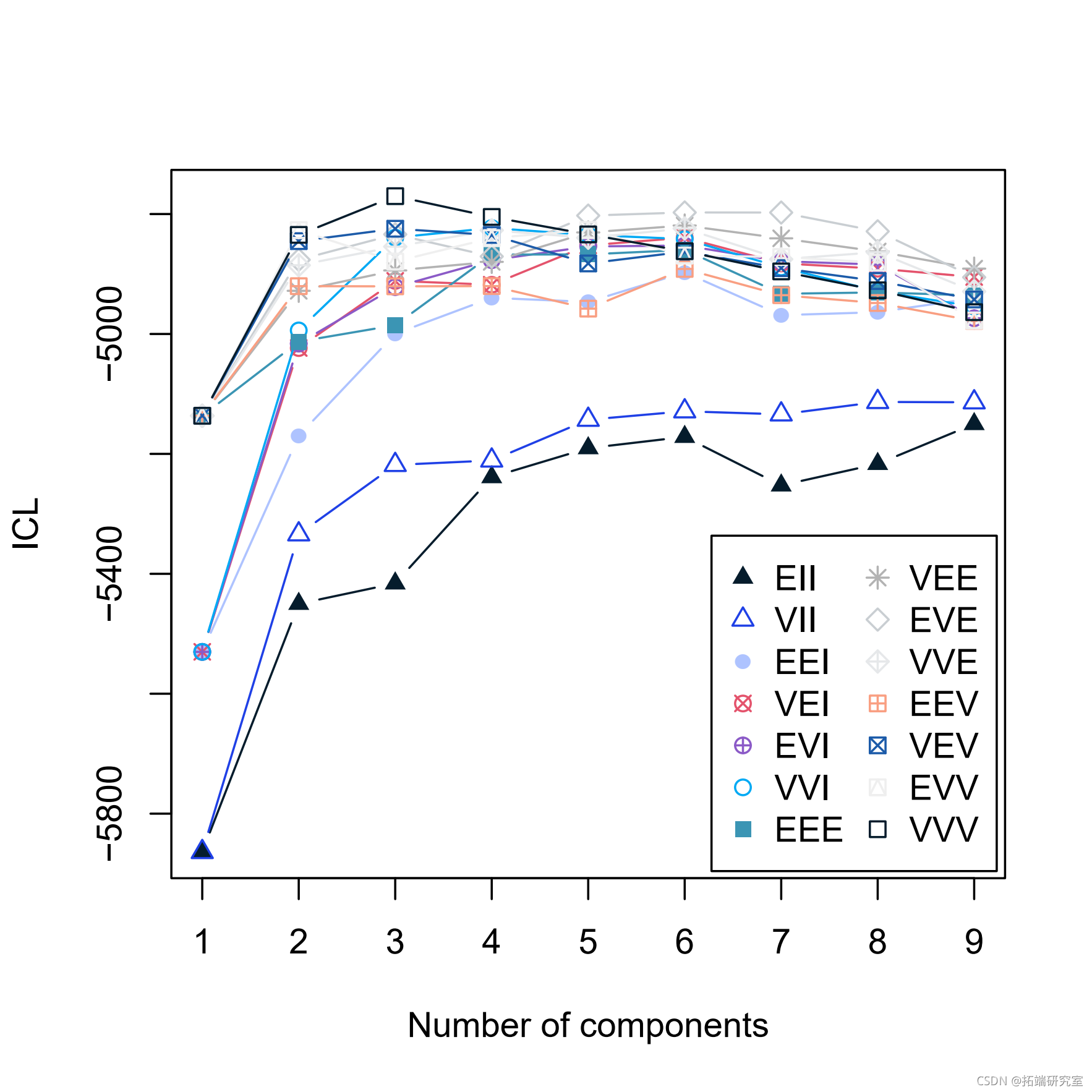
-
-
-
BootstrapLRT(X)
-
初始化
使用EM算法进行最大似然估计。EM的初始化是使用从聚类层次结构聚类中获得的分区来进行的。
-
-
hclust(X, use = "SVD"))
-

clustBIC(X, initialization )) # 默认

hc2 
clustBIC(X, initialization )

hclust(X, model= "EEE"))

-
-
summary(BIC3)

通过合并最佳结果来更新BIC。
BIC(BIC1, BIC2, BIC3)

使用随机起点进行单变量拟合,通过创建随机集聚和合并最佳结果获得。
-
-
for(j in 1:20)
-
{
-
rBIC <- mclustBIC(
-
initi ))
-
BIC <- update(BIC, rBIC)
-
}
-
-
clust(ga, BIC)

分类
EDDA
-
X <- iris[,1:4]
-
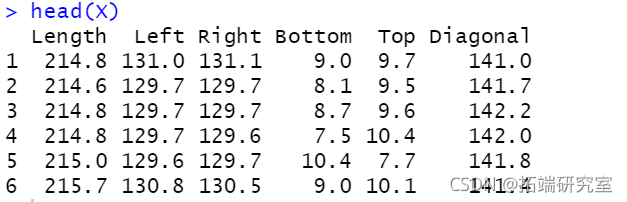
head(X)
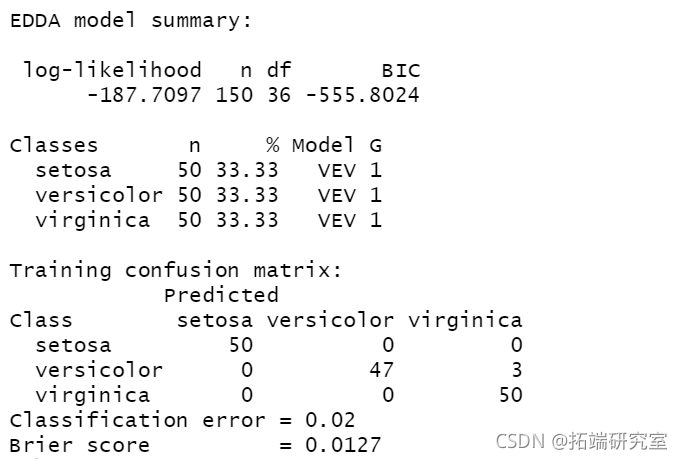
clustDA(X, class, "EDDA")
-
-
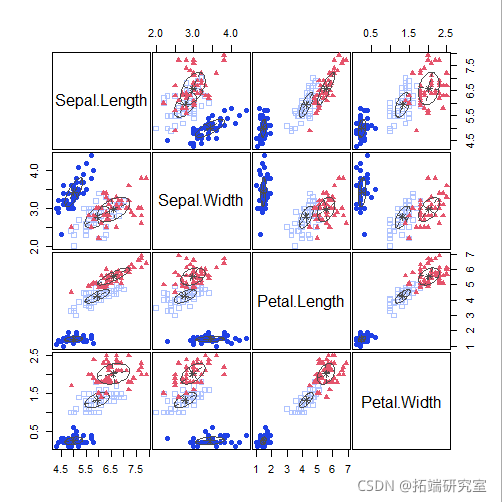
plot(mod2)
-
MclustDA
-
-
-
table(class)
-

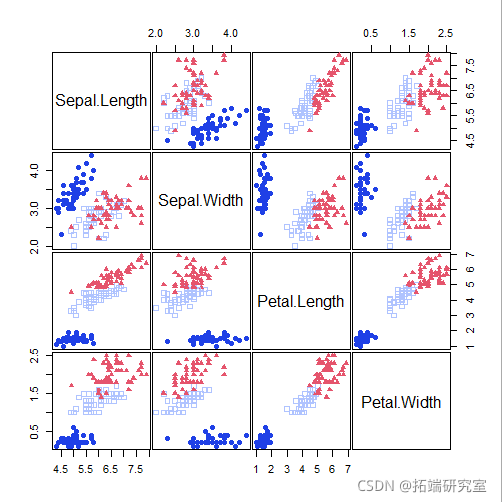
head(X)
clustDA(X, class)
-
-
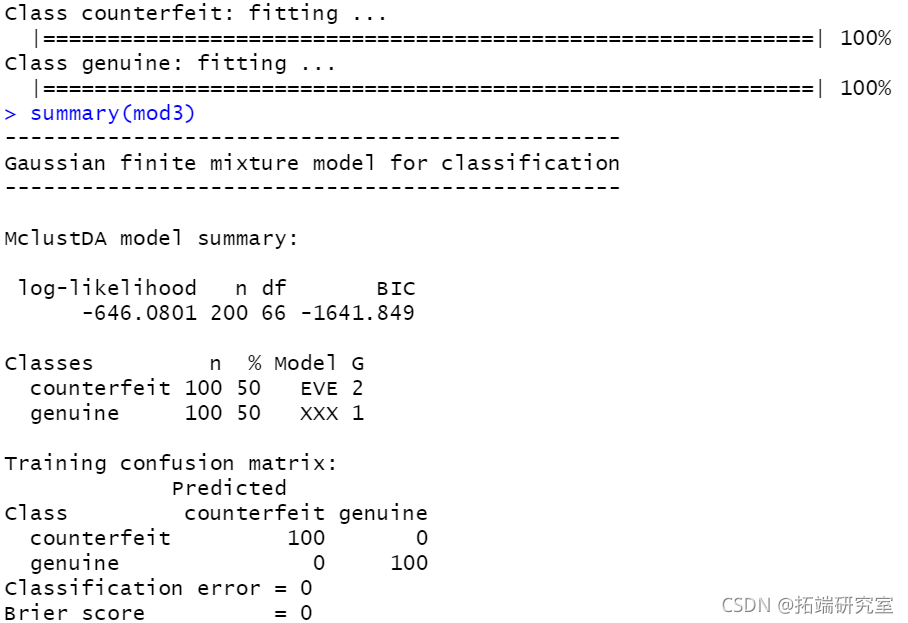
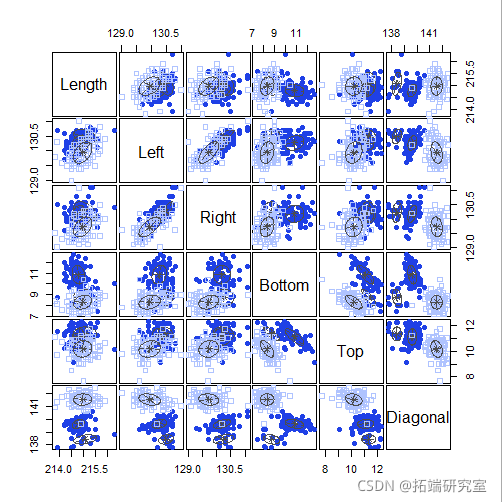
plot(mod3, 2)
-
-
-
-
-
plot(mod3, 3)
-
交叉验证误差
-
-
cv(mod2, nfold = 10)

-
-
unlist(cv[3:4])

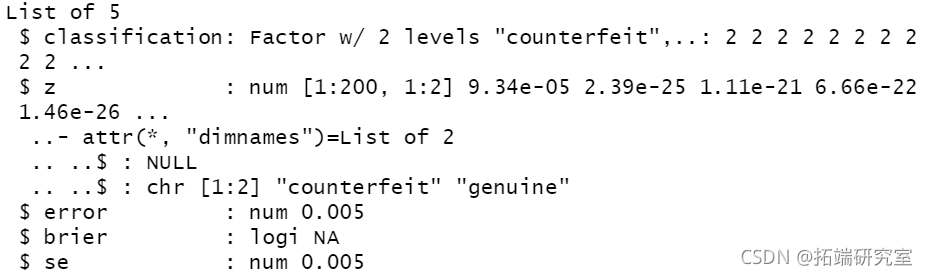
cv(mod3, nf = 10)
-
-
unlist(cv[3:4])

密度估计
单变量
clust(acid)

-
-
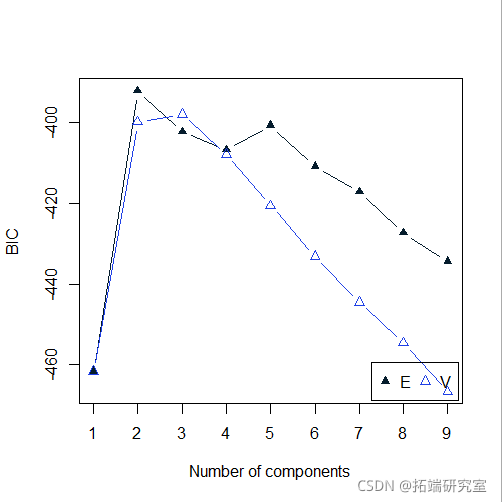
plot(mod4, "BIC")
-
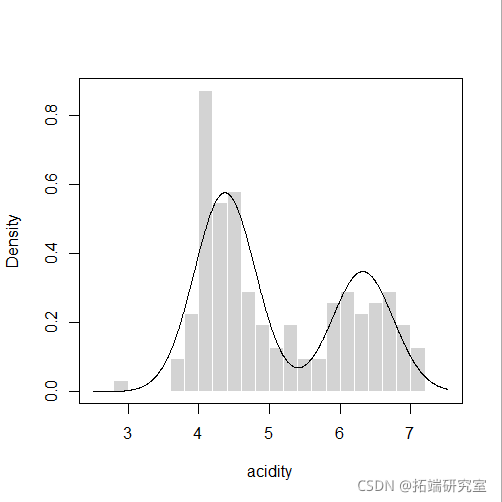
-
plot(mod4, "density", acidity)
-
-
-
-
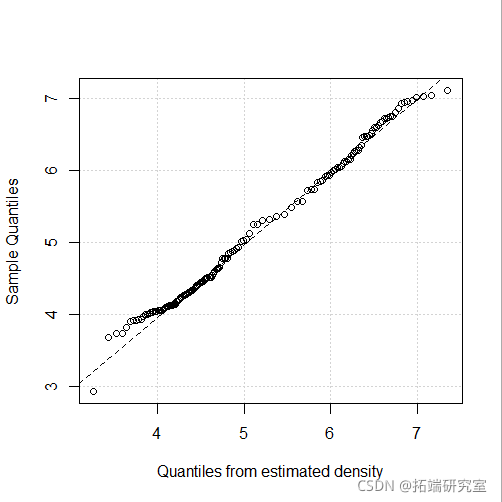
plot(mod4, "diagnostic", "cdf")
-
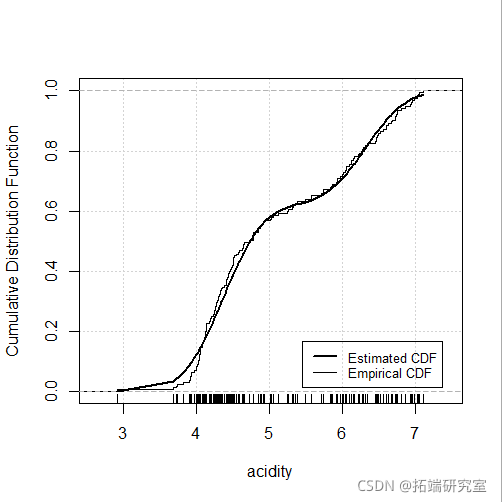
多变量
-
clu(faithful)
-
summary(mod5)

-
-
plot(mod5, "BIC")
-
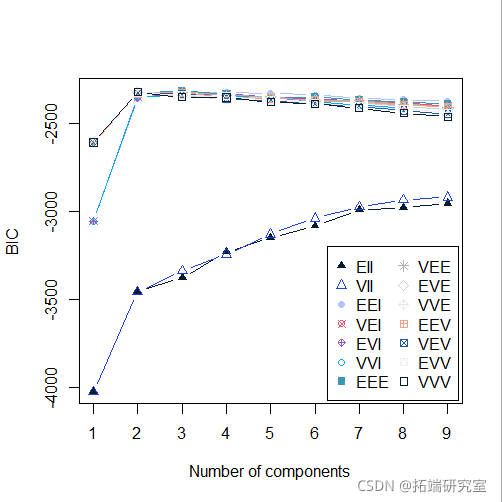
-
-
-
-
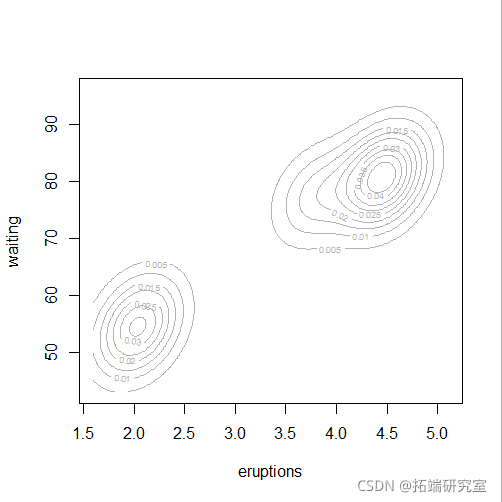
plot(mod5, "density",faithful)
-
-
-
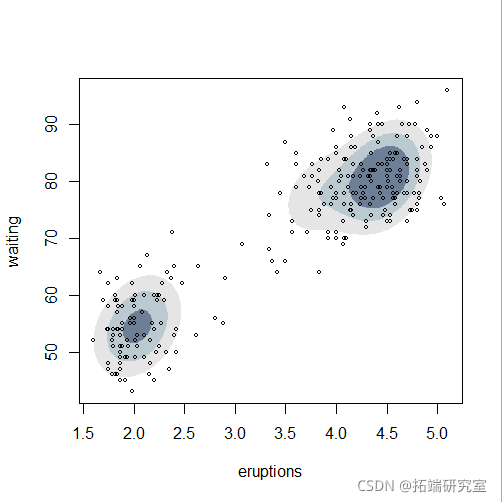
Bootstrap推理
-
-
summary(boot1, what = "se")
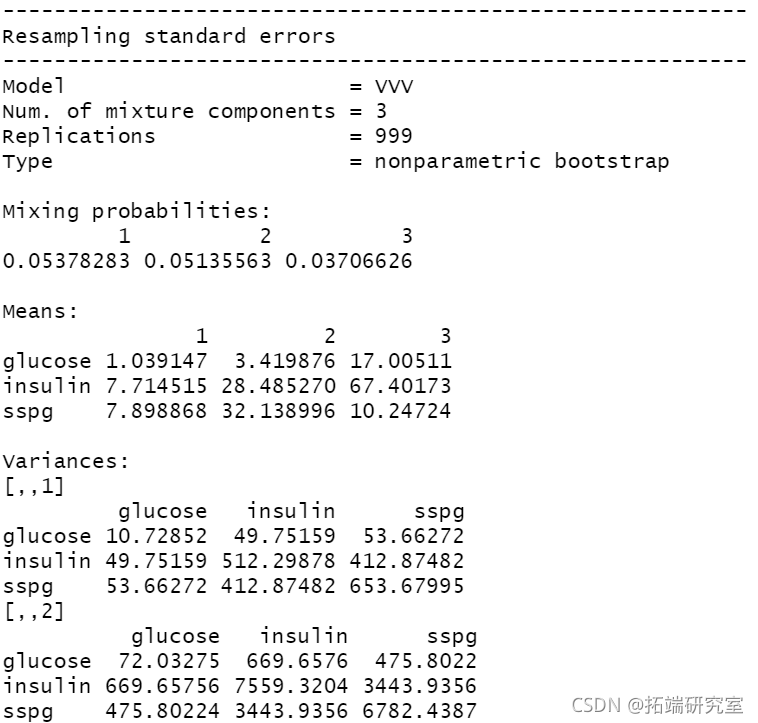

summary(boot1, what = "ci") 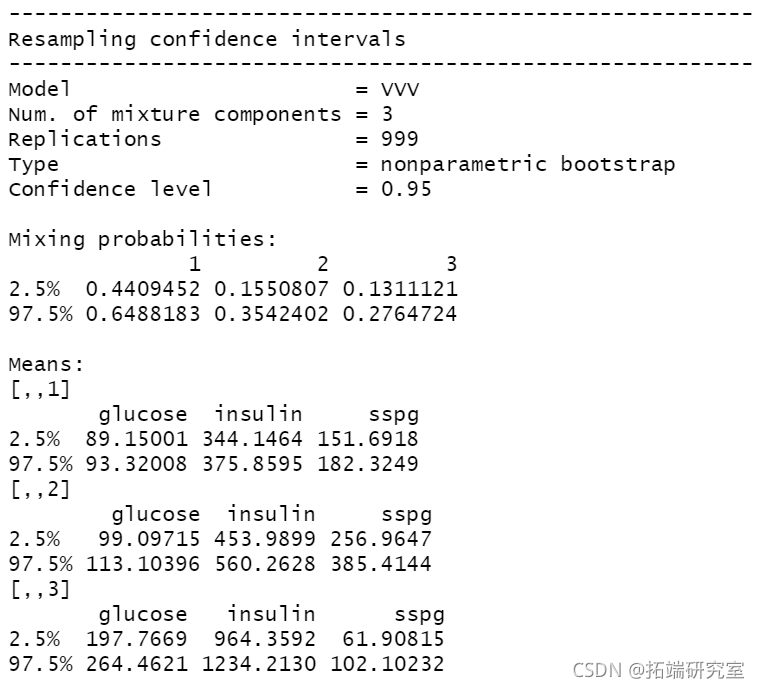
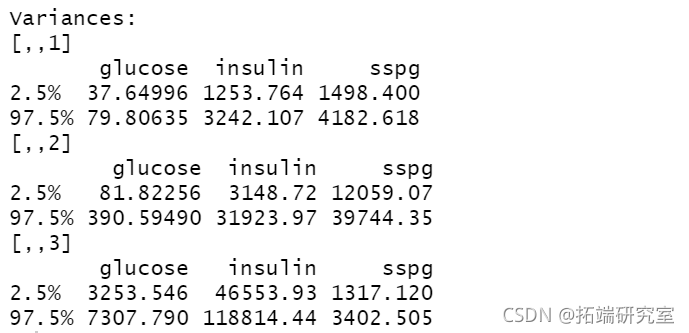
-
-
summary(boot4, what = "se")
-
-
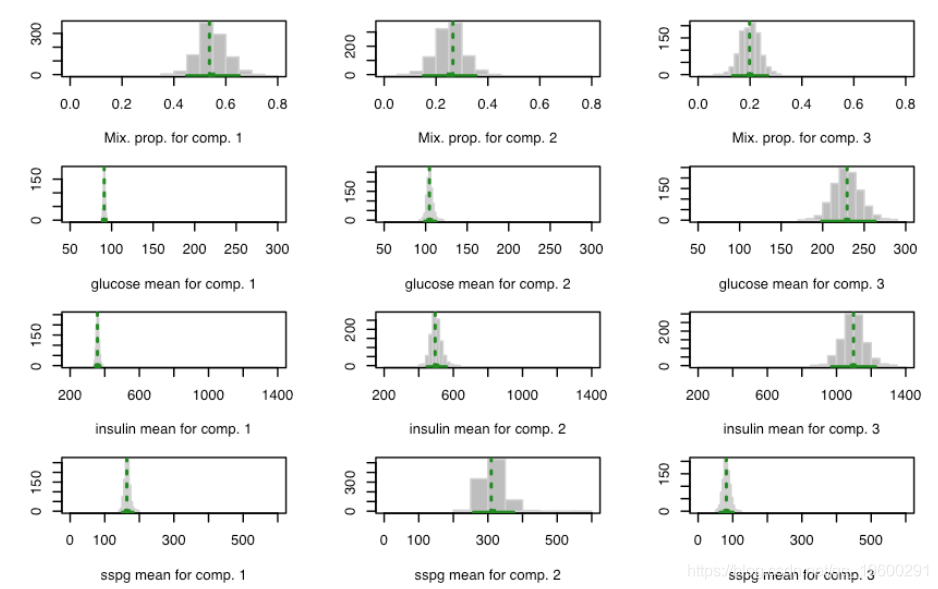
plot(boot4)
-

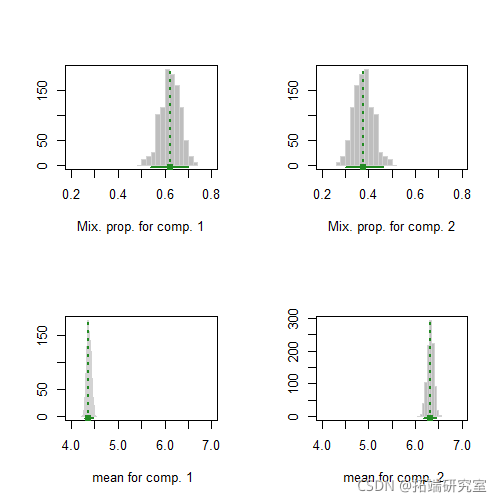
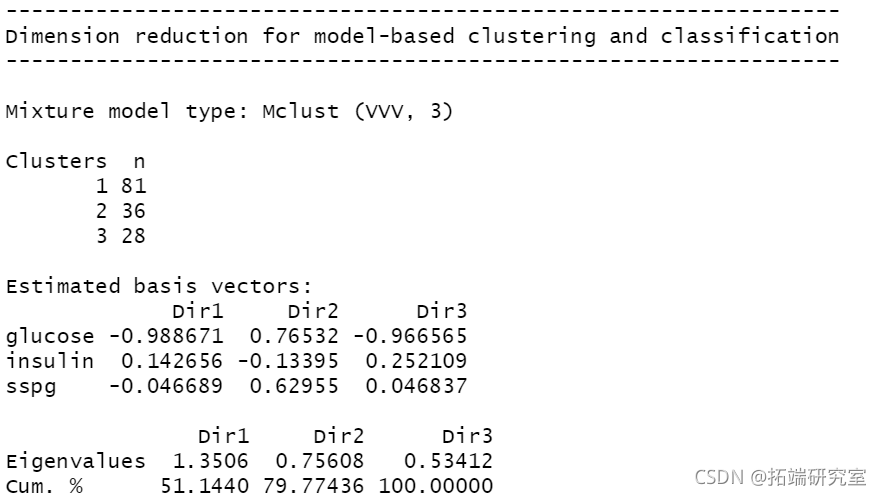
降维
聚类
-
-
-
plot(mod1dr, "pairs")
-
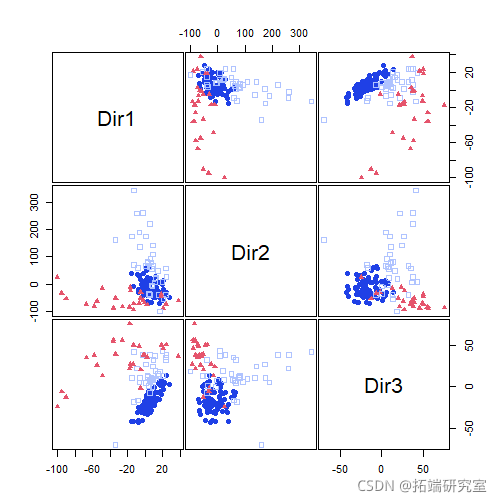
plot(mod1dr)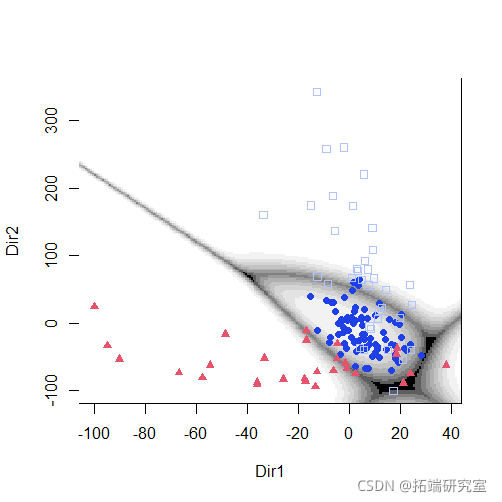
plot(mod1dr, "scatterplot")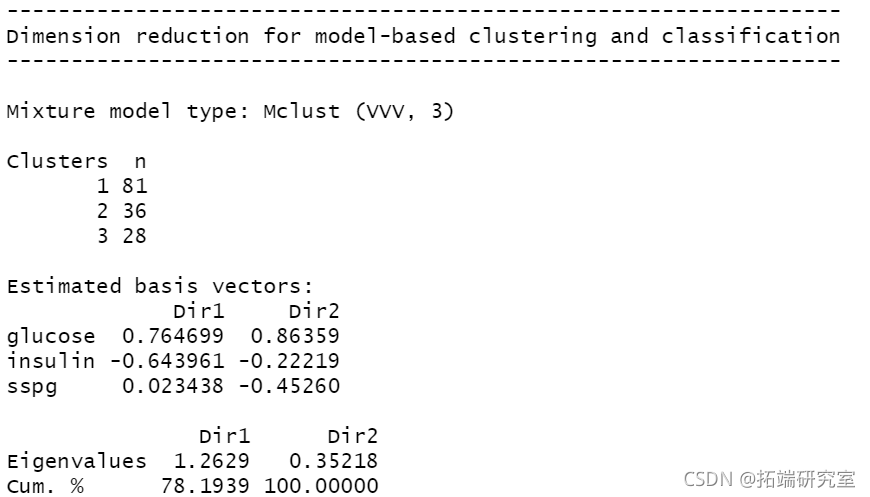
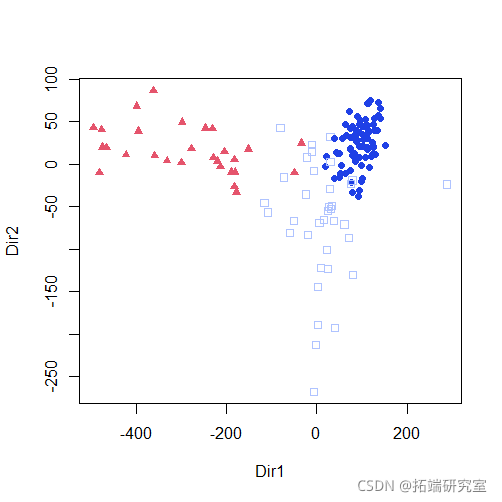
plot(mod1dr)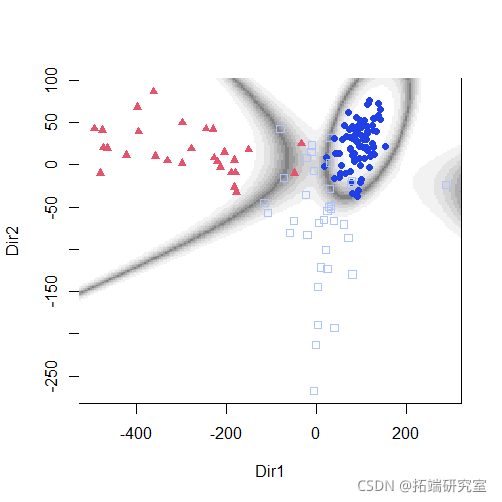
分类
-
-
-
summary(mod2dr)
-
-
plot(mod2d)
-

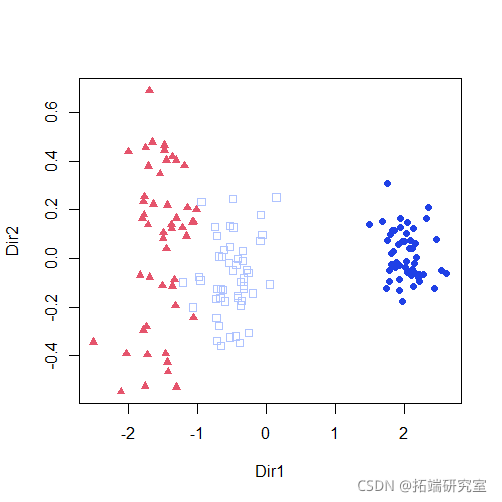
-
plot(mod2dr)
-
-
-
-
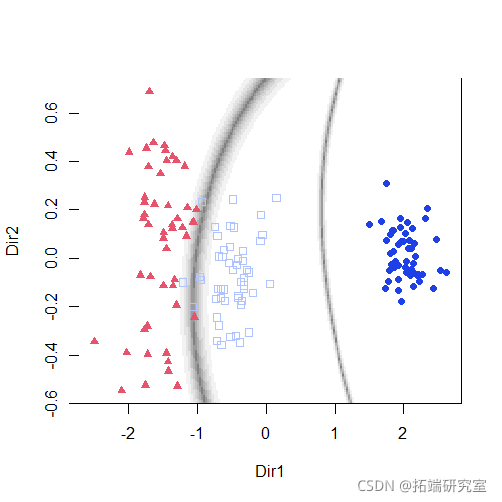
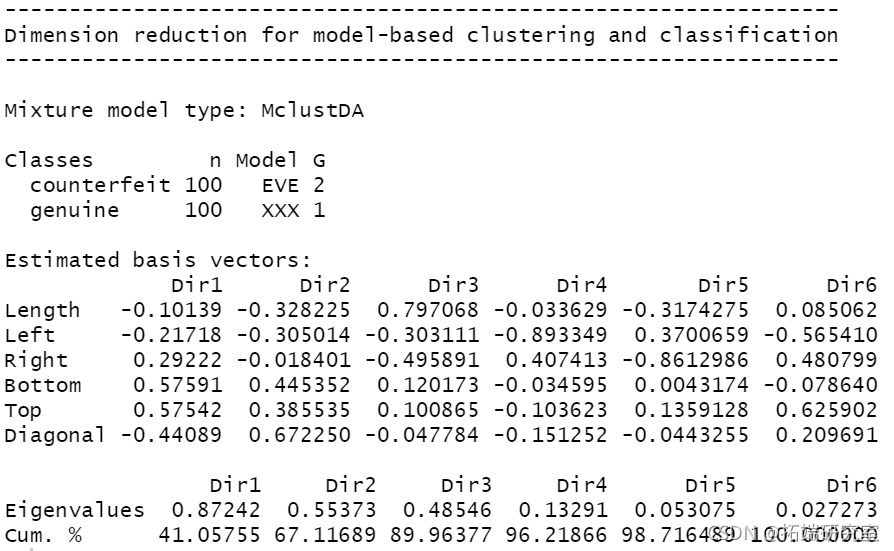
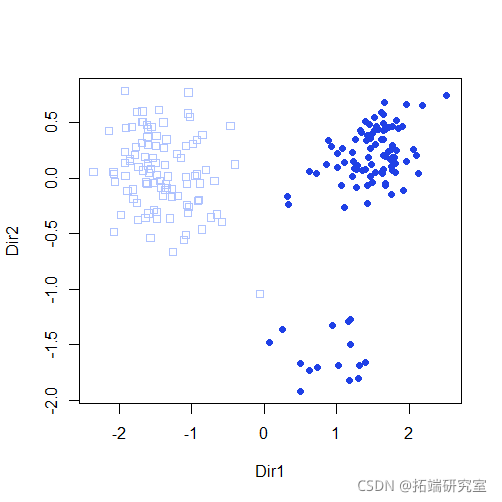
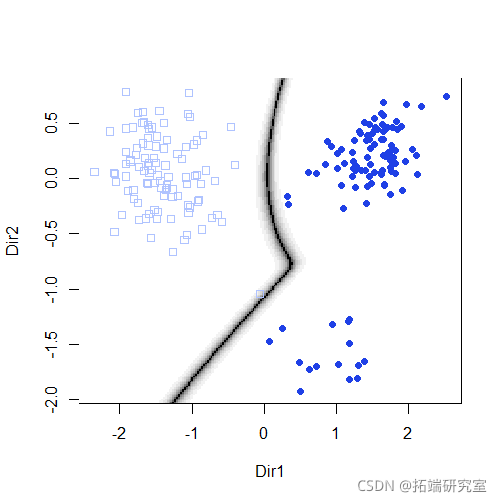
summary(mod3dr)
-
-
plot(mod3dr)
-
-
plot(mod3dr)
-
-
-
使用调色板
大多数图形都使用默认的颜色。
调色板可以定义并分配给上述选项,具体如下。
-
options("Colors" = Palette )
-
Pairs(iris[,-5], Species)
-
-
如果需要,用户可以很容易地定义自己的调色板。
参考文献
Fraley C. and Raftery A. E. (2002) Model-based clustering, discriminant analysis and density estimation, Journal of the American Statistical Association, 97/458, pp. 611-631.

最受欢迎的见解
3.matlab中的偏最小二乘回归(PLSR)和主成分回归(PCR)
5.R语言回归中的Hosmer-Lemeshow拟合优度检验