原文链接:http://tecdat.cn/?p=24121
原文出处:拓端数据部落公众号
此示例说明如何使用从传感器获得的数据分析共享单车交通模式, 来预处理带时间戳的数据。数据来自传感器。
此示例展示了如何执行各种数据清理、调整和预处理任务,例如删除缺失值和同步具有不同时间步长的时间戳数据。此外,突出显示数据探索,包括使用timetable 数据容器的可视化和分组计算 :
-
探索日常自行车交通
-
将自行车交通与当地天气条件进行比较
-
分析一周中不同天数和一天中不同时间的自行车流量
将自行车交通数据导入时间表
从逗号分隔的文本文件中导入自行车交通数据示例。使用该head 函数显示前八行 。
-
head(bkTb)
-
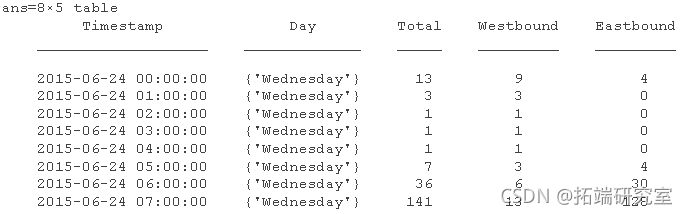
数据有时间戳,方便使用时间表来存储和分析数据。时间表类似于表,但包括与数据行关联的时间戳。时间戳或行时间由datetime 或 duration 值表示 。 datetime 和 duration 分别是用于表示时间点或经过时间的推荐数据类型。
转换 为时间表 。您必须使用转换函数,因为 readtable 返回一个表。 行时间是标记行的元数据。但是,当您显示时间表时,行时间和时间表变量以类似的方式显示。请注意,该表有五个变量,而时间表有四个。
tabe2tmeabe(biel);
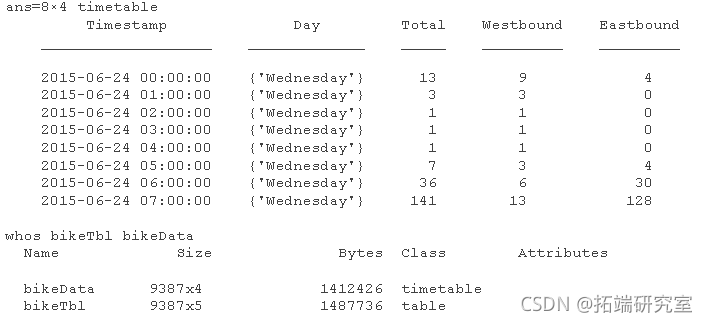
访问时间和数据
将Day 变量转换 为分类变量。分类数据类型专为包含有限离散值集的数据而设计,例如一周中的日期名称。列出类别,以便它们按天顺序显示。使用点下标按名称访问变量。
在时间表中,时间与数据变量分开处理。访问 Properties 时间表的 显示行时间是时间表的第一维,变量是第二维。该 DimensionNames 属性显示两个维度的名称,而该 VariableNames 属性显示沿第二个维度的变量的名称。
bkDta.Poetis

默认情况下, 在将表转换为时间表时table2timetable 指定 Timestamp为第一个维度名称,因为这是原始表中的变量名称。您可以通过 Properties.
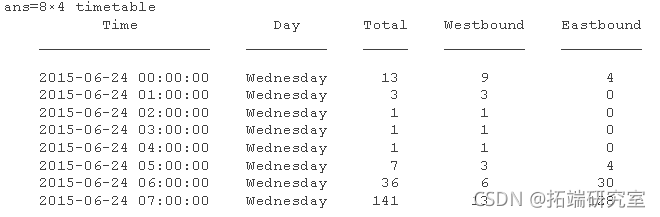
将维度的名称更改为 Time 和 Data。
DmesiNams = {'Time' 'Data'};

显示时间表的前八行。
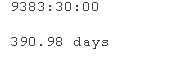
确定最晚和最早的行时间之间经过的天数。一次引用一个变量时,可以通过点表示法访问这些变量。
-
lpsTie = max(bkeDa.Tme) - min(bkData.me)
-
要检查特定日期的典型自行车数量,请计算自行车总数以及向西和向东行驶的数量的平均值。
通过对bikeData 使用大括号的内容进行索引,将数字数据作为矩阵返回 。显示前八行。使用标准表下标访问多个变量。
-
cs(1:8,)
-

由于均值仅适用于数值数据,因此您可以使用该 vartype 函数来选择数值变量。 vartype 比手动索引到表或时间表以选择变量更方便。计算平均值并忽略 NaN 值。
-
-
mean(cots,'omitn')
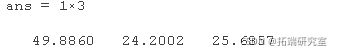
按日期和时间选择数据
要确定假期期间有多少人骑自行车,请检查 7 月 4 日假期的数据。按 7 月 4 日的行时间索引时间表。当您索引行时间时,必须完全匹配时间。可以将时间索引指定为 datetime 或 duration 值,或者指定为可以转换为日期和时间的字符向量。可以多次指定为数组。
bikeData 使用特定日期和时间进行索引 以提取 7 月 4 日的数据。如果仅指定日期,则假定时间为午夜或 00:00:00。
-
-
d = {'208:00:00','09:00:00'};
-
bieDta(d,:)

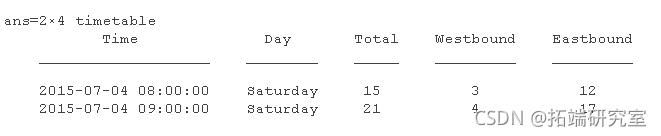
使用这种策略来提取一整天会很麻烦。您还可以指定时间范围而不对特定时间进行索引。创建时间范围下标,使用 timerange 函数。
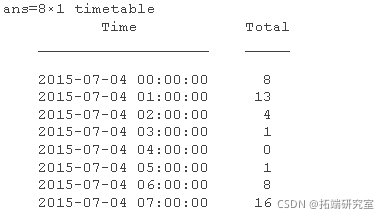
使用 7 月 4 日一整天的时间范围在时间表中下标。指定开始时间为 7 月 4 日午夜,结束时间为 7 月 5 日午夜。默认情况下, timerange 涵盖从开始时间开始的所有时间和直到但不包括结束时间。绘制一天中的自行车数量。
-
jul4 = bikeData(tr,'Total');
-
hea(jl4)
-
-
-
bar(4Tie,jl4otl)
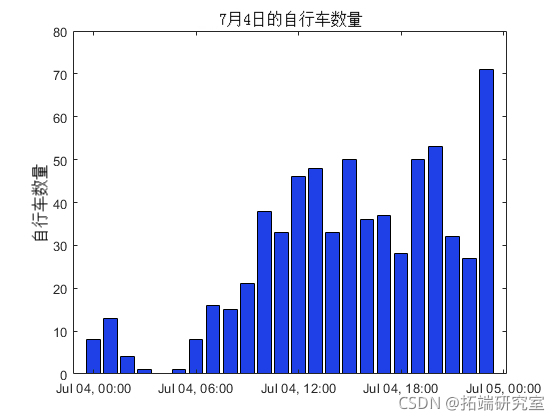
从图中可以看出,全天成交量更大,下午趋于平稳。由于许多企业都关门了,所以图中没有显示通勤时间的典型交通情况。晚上晚些时候的峰值可归因于在晚上的庆祝活动。为了更仔细地检查这些趋势,应将数据与典型日子的数据进行比较。
将 7 月 4 日的数据与 7 月其他时间的数据进行比较。
-
plot(jul.Time,ju.Toal)
-
hold o
-
plot(jl.Tme,ju4.otal)
-
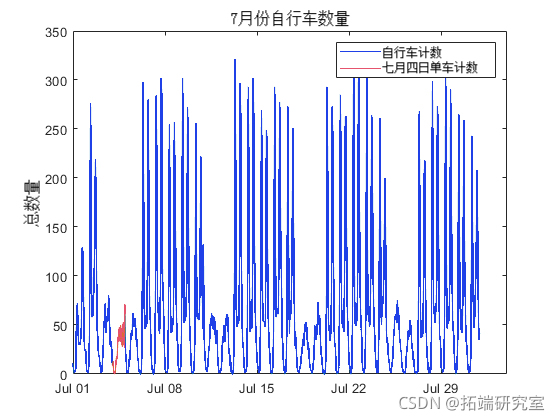
该图显示了工作日和周末之间交通差异的变化。7 月 4 日和 5 日的交通模式与周末交通模式一致。通过进一步的预处理和分析,可以更仔细地检查这些趋势。
预处理时间和数据使用 timetable
带时间戳的数据集通常很混乱,可能包含异常或错误。时间表非常适合解决异常和错误。
时间表的行时间不必按任何特定顺序排列。它可以包含未按行时间排序的行。时间表还可以包含具有相同行时间的多行,尽管这些行可以具有不同的数据值。即使行时间已排序且唯一,它们也可能因不同大小的时间步长而不同。时间表甚至可以包含 NaT 或 NaN 值来指示缺失的行时间。
该 timetable 数据类型提供了许多不同的方式解决失踪,复制或不均匀倍。您还可以重新采样或汇总数据以创建 定期 时间表。当时间表是规则的时,它的行时间是经过排序且唯一的,并且在它们之间具有统一或均匀区间的时间步长。
-
要查找缺失的行时间,请使用
ismissing. -
要删除缺失的时间和数据,请使用
rmmissing. -
要按行时间对时间表进行排序,请使用
sortrows。 -
要生成具有唯一且已排序的行时间的时间表,请使用
unique和retime。 -
要生成常规时间表,请指定均匀区间的时间向量并使用
retime。
按时间顺序排序
确定时间表是否已排序。如果时间表的行时间按升序列出,则该时间表已排序。
-
issorted(bikeData)
-
![]()
对时间表进行排序。该 sortrows 函数按行时间对行进行排序,从最早到最晚。如果存在具有重复行时间的行,则将 sortrows 所有重复项复制到输出。
-
bikeData = sortrows(bikeData);
-
issorted(bikeData)
-
![]()
识别和删除缺失的时间和数据
时间表的变量或其行时间中可能缺少数据指示符。例如,您可以将缺失的数值表示为 NaNs,将缺失的日期时间值表示为 NaTs。您可以分配,查找,删除,并用填充缺失值 standardizeMissing, ismissing, rmmissing,和 fillmissing 功能。
查找并计算时间表变量中的缺失值。在此示例中,缺失值表示未收集数据的情况。
-
ismssng(bieDa);
-
sum(isata)
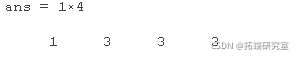
来自的输出 ismissing 是一个 logical 矩阵,与表的大小相同,将缺失的数据值标识为真。显示缺少数据指示符的任何行。
any(misDta,2);

仅查找时间表变量中的缺失数据,而不是时间。要查找缺失的行时间,请调用 ismissing 时间。
ismisig(bikDa.time);

在本例中,缺失时间或数据值表示测量错误,可以排除。使用 删除表中包含缺失数据值和缺失行时间的行 rmmissing。
rmising(bieDaa);

miissing(ieDta.Time) ![]()
删除重复的时间和数据
确定是否有重复的时间和/或重复的数据行。您可能希望排除重复项,因为这些也可以被视为测量误差。通过查找排序时间之间的差异恰好为零的位置来识别重复时间。
-
idx = diff(biDat.Tme) == 0;
-
dup = biDaime(idx)
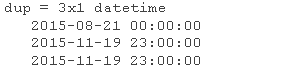
重复三次, 11 月 19 日重复两次。检查与重复次数相关的数据。
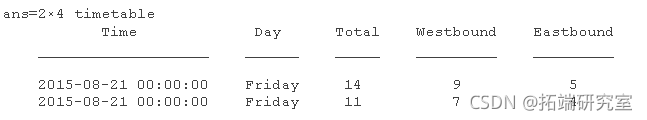

第一个有重复的次数但没有重复的数据,而其他的则完全重复。当时间表行在行中包含相同的行时间和相同的数据值时,它们被视为重复。您可以使用 unique 删除时间表中的重复行。该 unique 函数还按行时间对行进行排序。
bkeata = unique(biketa); 具有重复时间但非重复数据的行需要一些解释。检查那些时间前后的数据。
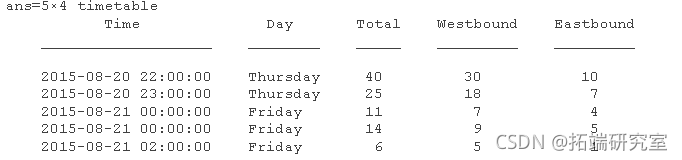
在这种情况下,由于数据和周围时间是一致的,因此重复时间可能是错误的。虽然它似乎代表 01:00:00,但不确定这应该是什么时间。可以累积数据以说明两个时间点的数据。
sum(Dta{dup(1),2:end})
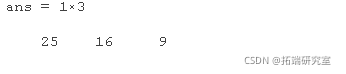
这只是一种可以手动完成的情况。但是,对于许多行,该 retime 函数可以执行此计算。使用sum 聚合函数对唯一次数的数据进行累加 。总和适用于数字数据,但不适用于时间表中的分类数据。使用 vartype 标识数值变量。
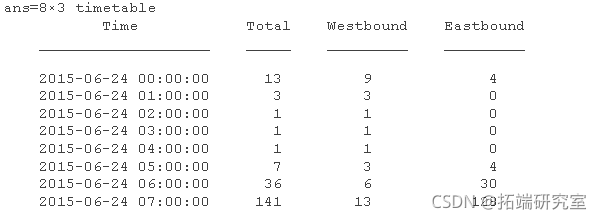
您不能对分类数据求和,但由于一个标签代表一整天,因此取每一天的第一个值。您可以retime 使用相同的时间向量再次执行 操作并将时间表连接在一起。
-
-
cata = retme(ikat(:,vc,t,'frtvle');
-
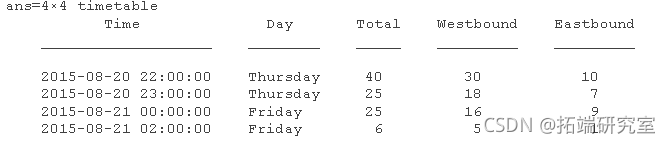
检查时间区间的均匀性
数据似乎具有一小时的统一时间步长。要确定时间表中的所有行时间是否都如此,使用该 isregular 函数。 isregular 返回 true 有序的、均匀区间的时间(单调递增),没有重复或丢失的时间(NaT 或 NaN)。
![]()
0或 的输出 false表明时间表中的时间区间不均匀。更详细地探索时间区间。
[min(dt); max(dt)]

要将时间表置于固定时间区间,请使用 retime 或 synchronize 并指定感兴趣的时间区间。
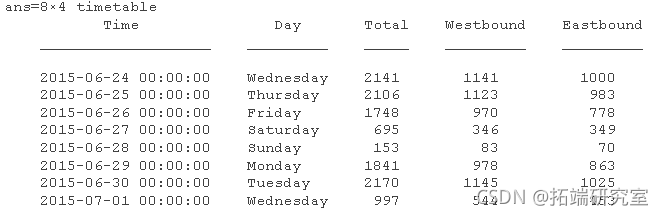
确定每日自行车量
使用该retime 函数确定每天的计数 。使用该sum 方法累积每天的计数数据 。这适用于数值数据,但不适用于时间表中的分类数据。用于 vartype 按数据类型标识变量。
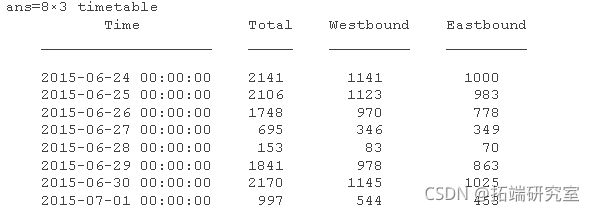
如上所述,您可以retime 再次执行 操作以使用适当的方法表示分类数据并将时间表连接在一起。
-
dantat = rtime(bkeat(:,vc),'dily','firtau');
-
比较自行车数量和天气数据
通过将自行车数量与天气数据进行比较,检查天气对骑行行为的影响。加载天气时间表,其中包括来自历史天气数据,包括暴风雨事件。
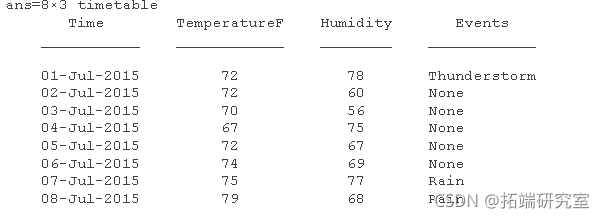
要汇总时间表中的时间和变量,请使用 summary 函数。
summary(wetherta)


使用 将自行车数据与天气数据组合成一个时间向量 synchronize。您可以使用synchronize 重新采样或聚合时间表数据 。
将两个时间表中的数据同步到一个公共时间向量,该时间向量是从它们各自的每日时间向量的交集构建的。
syhrone(dayout,wethrDta,'inseon';
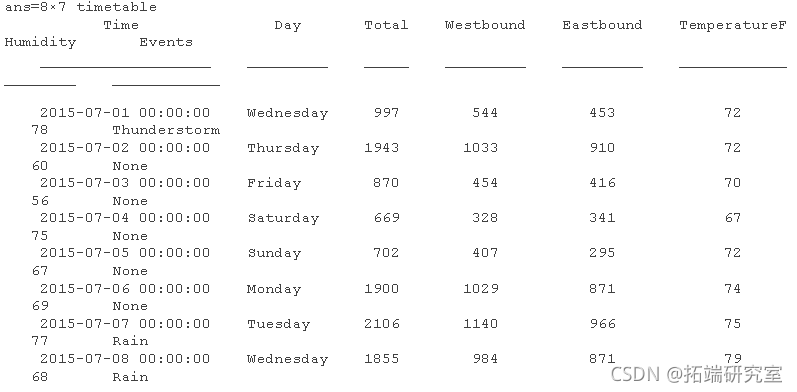
比较单独 y 轴上的自行车交通数量和室外温度来检查趋势。从数据中删除周末进行可视化。
-
-
yyaxis left
-
plot(wekata.Time, ekdaaa.Tol)
-
yyaxis right
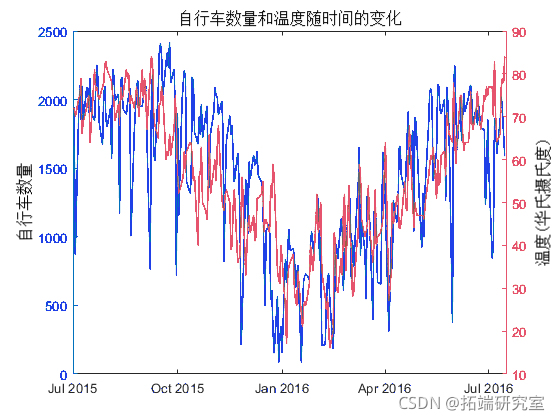
该图显示交通和天气数据可能遵循类似的趋势。
趋势相似,表明在寒冷的日子里骑自行车的人更少。
按星期几和一天中的时间分析
根据不同的时间区间(例如星期几和一天中的时间)检查数据。使用varfun 对变量执行分组计算来确定每天的总计数 。sum 使用名称-值对指定 具有函数句柄和分组变量和首选输出类型的函数。
-
bDa = varn(suket,'GpigVrles','Day',...
-
'Otpuoat''tale')
-
-
-
fgue
-
bar(by{:,{'smestund',sumEbound'}})
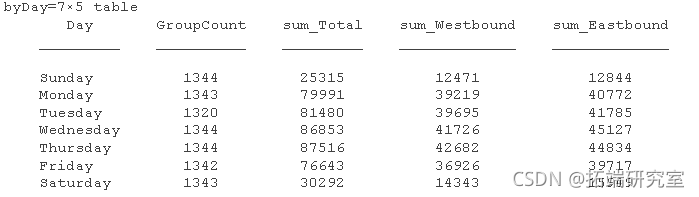
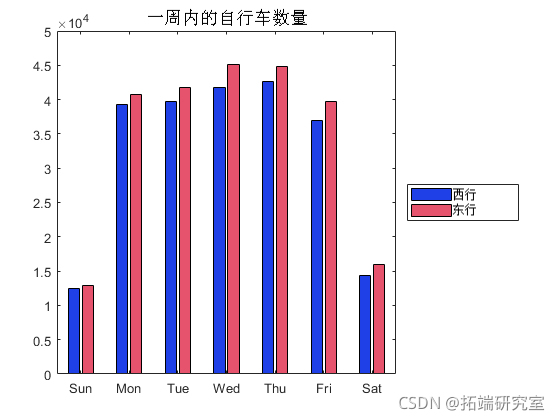
条形图表示工作日的交通量较大。此外,东行和西行方向也有所不同。这可能表明人们在进出城市时往往会选择不同的路线。另一种可能是,有些人一天进去,另一天回来。
确定一天中的小时 varfun 用于按组计算。
-
varn(@mean,bketa(:,{'Wesbund','Estund','HfDay'}),...
-
'GrunVabes','fDay','Outputrmat','te');
-
-
-
bar(byr})

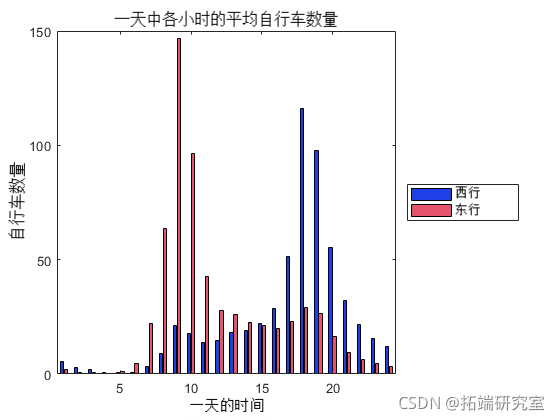
在典型的通勤时间(上午 9:00 和下午 5:00 左右)出现交通高峰。此外,东行和西行方向之间的趋势不同。一般来说,西行方向是朝向地区周围的住宅区和大学。东行方向是朝向市中心。
与东行方向相比,当天晚些时候西行方向的交通量更大。由于该地区的餐馆,这可能表明大学的时间表和交通。按星期几和一天中的小时检查趋势。
-
byra = varfun(@mikaa,'Grpiaibes',{'HOfDay','ay'},...
-
'OuutFort','tbl')
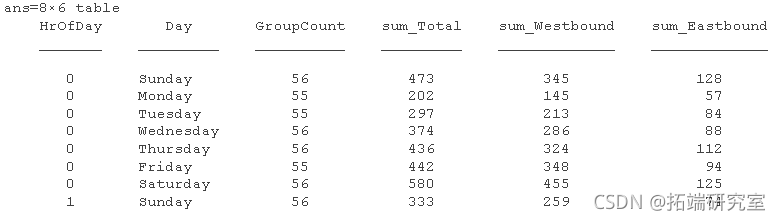
要安排时间表以便将一周中的几天作为变量,请使用该 unstack 函数。
-
hrnaWk = unstack(byD(:,{HrOfa','ay','u_Toal'),smTota','Da');
-
ribbon(hrnaW)
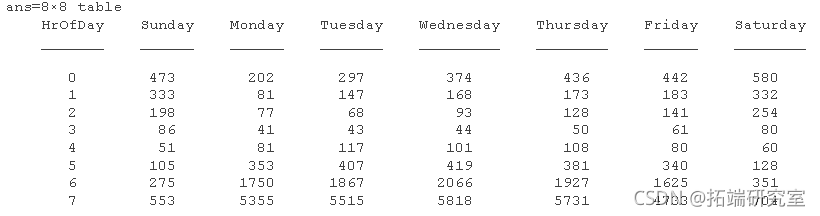
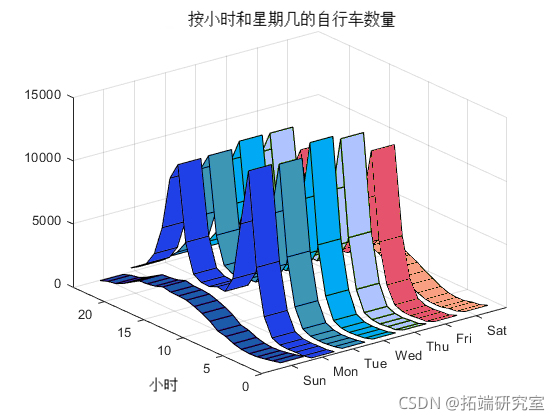
周一至周五的正常工作日也有类似的趋势,高峰时段出现高峰,晚上交通逐渐减少。周五的交易量较少,但总体趋势与其他工作日相似。周六和周日的趋势彼此相似,没有高峰时段,但在当天晚些时候成交量更大。周一至周五的深夜趋势也相似,周五成交量较少。
分析高峰时段的交通
要检查一天中的总体时间趋势,请按高峰时间拆分数据。使用discretize 可以使用一天中的不同时间或时间单位 。例如,将数据分成 AM、 AMRush、 Day、 PMRush、 的组 PM。然后用于 varfun 按组计算平均值。
-
-
brBn = varfun(@mean,beData:{'Toa','HLbel'})','Hbel',...
-
'Otpuorat',le)
-
-
bar(brBn.en)
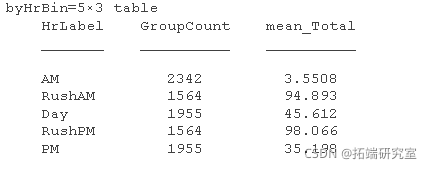
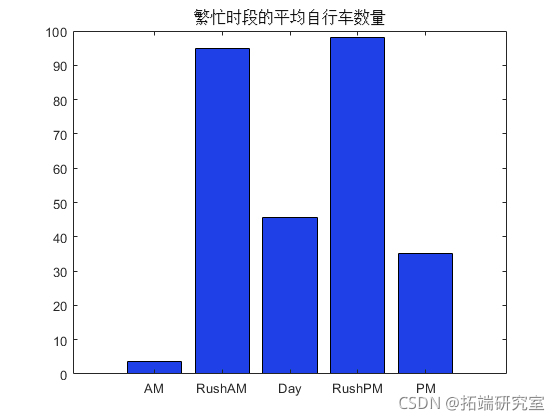
一般来说,与一天中的其他时间相比,该区域在傍晚和早高峰时段的交通量大约是该区域的两倍。该区域清晨车流量很少,但傍晚和深夜的车流量仍然很大,堪比早晚高峰时段以外的白天。

最受欢迎的见解