原文链接:http://tecdat.cn/?p=6227
主题建模是一种在大量文档中查找抽象主题的艺术方法。一种作为监督无的机器学习方法,主题模型不容易评估,因为没有标记的“基础事实”数据可供比较。然而,由于主题建模通常需要预先定义一些参数(首先是要发现的主题ķ的数量),因此模型评估对于找到给定数据的“最佳”参数集是至关重要的。
概率LDA主题模型的评估方法
使用未标记的数据时,模型评估很难。这里描述的指标都试图用理论方法评估模型的质量,以便找到“最佳”模型。
评估后部分布的密度或发散度
有些指标仅用于评估后验分布(主题 - 单词和文档 - 主题分布),而无需以某种方式将模型与观察到的数据进行比较。
使用美联社数据查找最佳主题模型
计算和评估主题模型
主题建模的主要功能位于tmtoolkit.lda_utils。
import matplotlib.pyplot as plt # for plotting the results plt.style.use('ggplot') # for loading the data: from tmtoolkit.utils import unpickle_file # for model evaluation with the lda package: from tmtoolkit.lda_utils import tm_lda # for constructing the evaluation plot: from tmtoolkit.lda_utils.common import results_by_parameter from tmtoolkit.lda_utils.visualize import plot_eval_results
接下来,我们加载由文档标签,词汇表(唯一单词)列表和文档 - 术语 - 矩阵组成的数据dtm。我们确保dtm尺寸合适:
doc_labels, vocab, dtm = unpickle_file('ap.pickle') print('%d documents, %d vocab size, %d tokens' % (len(doc_labels), len(vocab), dtm.sum())) assert len(doc_labels) == dtm.shape[0] assert len(vocab) == dtm.shape[1]
现在我们定义应该评估的参数集我们设置了一个常量参数字典。const_params,它将用于每个主题模型计算并保持不变我们还设置了。varying_params包含具有不同参数值的字典的不同参数列表:
在这里,我们想要从一系列主题中计算不同的主题模型ks = [10, 20, .. 100, 120, .. 300, 350, .. 500, 600, 700]。由于我们有26个不同的值ks,我们将创建和比较26个主题模型。请注意,还我们alpha为每个模型定义了一个参数1/k(有关LDA中的α和测试超参数的讨论,请参见下文)。参数名称必须与所使用的相应主题建模包的参数匹配。在这里,我们将使用lda,因此我们通过参数,如n_iter或n_topics(例如,而与其他包的参数名称也会有所不同num_topics,不是而n_topics在gensim)。
我们现在可以使用模块中的evaluate_topic_models函数开始评估我们的模型tm_lda,并将不同参数列表和带有常量参数的字典传递给它:
默认情况下,这将使用所有CPU内核来计算模型并并行评估它们。
该plot_eval_results函数使用在评估期间计算的所有度量创建³³绘图。之后,如果需要,我们可以使用matplotlib方法调整绘图(例如添加绘图标题),最后我们显示和/或保存绘图。
结果
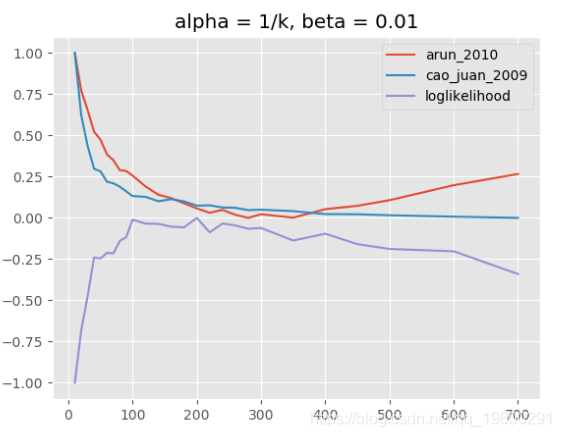
![]()
主题模型评估,alpha = 1 / k,beta = 0.01
请注意,对于“loglikelihood”度量,仅报告最终模型的对数似然估计,这与Griffiths和Steyvers使用的调和均值方法不同。无法使用Griffiths和Steyvers方法,因为它需要一个特殊的Python包(gmpy2) ,这在我运行评估的CPU集群机器上是不可用的。但是,“对数似然”将报告非常相似的结果。
阿尔法和贝塔参数
除了主题数量之外,还有alpha和beta(有时是文献中的eta)参数。两者都用于定义Dirichlet先验,用于计算各自的后验分布.Alpha是针对特定于文档的主题分布的先验的“浓度参数”,并且是针对主题特定的单词分布的先前的β 。
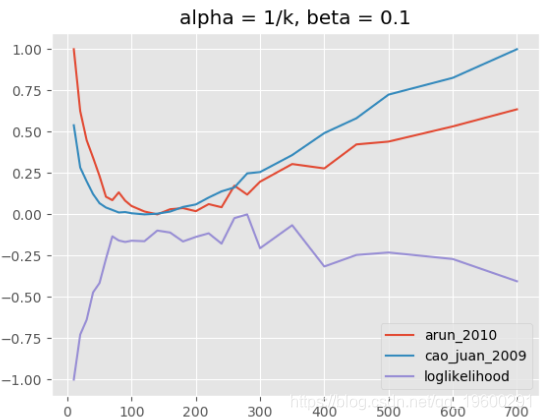
![]()
主题模型,alpha = 1 / k,beta = 0.1
当我们使用与上述相同的alpha参数和相同的k范围运行评估时,但是当β= 0.1而不是β= 0.01时,我们看到对数似然在k的较低范围内最大化,即大约70到300(见上图) 。
组合这些参数有很多种可能性,但是解释这些参数通常并不容易。下图显示了不同情景的评估结果:(1)α和β的固定值取决于k,(2)α和β都固定, (3)α和β均取决于k。
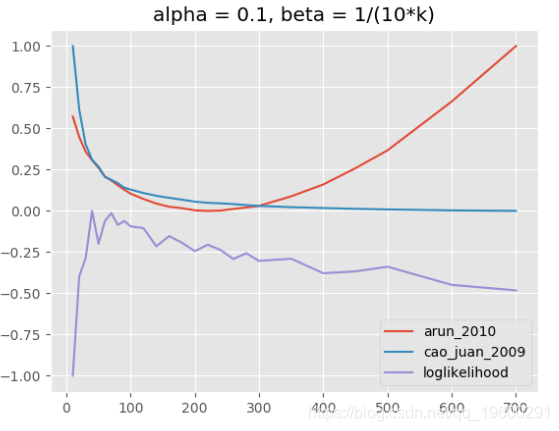
![]()
(1)主题模型,alpha = 0.1,beta = 1 /(10k)
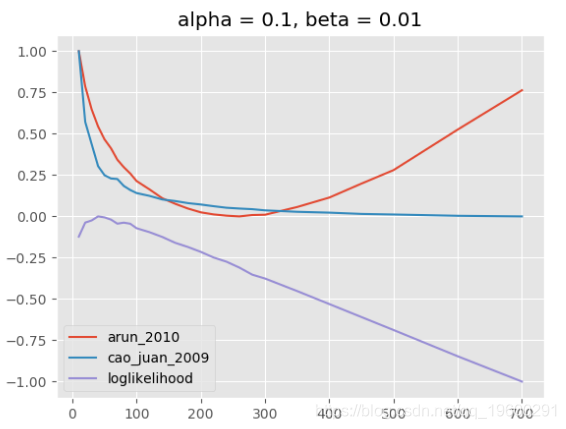
![]()
(2)主题模型,alpha = 0.1,beta = 0.01
![]()
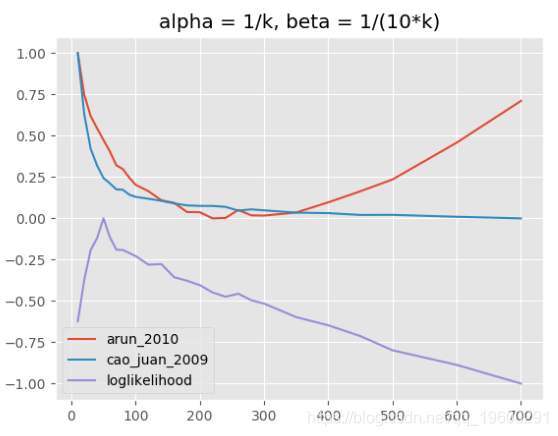
(3)主题模型,alpha = 1 / k,beta = 1 /(10k)
LDA超参数α,β和主题数量都相互关联,相互作用非常复杂。在大多数情况下,用于定义模型“粒度”的beta的固定值似乎是合理的,这也是Griffiths和Steyvers所推荐的。一个更精细的模型评估,具有不同的alpha参数(取决于k)使用解释的指标可以完成很多主题。