原文链接:http://tecdat.cn/?p=5334
几何布朗运动(GBM)是模拟大多数依赖某种形式的路径依赖的金融工具的标准主力。虽然GBM基于有根据的理论,但人们永远不应忘记它的最初目的 - 粒子运动的建模遵循严格的正态分布脉冲。基本公式由下式给出:
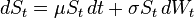
标准维纳过程代表创新。在对气体进行建模时效果很好,在财务建模方面存在一些严重的缺陷。问题是维纳过程有两个非常严格的条件:
a)创新通常是分布式的,平均零和方差为t
b)创新是独立的
现在,至少有一些金融市场数据暴露的人都知道股票回报不满足第一个条件,有时甚至不满足第二个条件。普遍的共识是,股票收益是扭曲的,是有效的,并且尾巴不均匀。虽然股票收益趋于收敛于正常分布且频率递减(即月收益率比日收益率更正常),但大多数学者会同意t分布或Cauchy分布更适合收益。
然而,在实践中,大多数人在模拟布朗运动时只是采用正态分布,并接受由此产生的资产价格不是100%准确。另一方面,我不满足于这种半解决方案,我将在下面的例子中展示盲目信任GBM的成本是多少。我提出了一种伪布朗方法,其中随机创新是从经验回报的核密度估计而不是假设的正态分布中采样的。这种方法的好处在于它产生的结果更接近于过去观察到的结果而没有完全复制过去(这将是直接从过去的创新中抽样随机创新的结果)。
介绍性例子
在我们进入有趣的部分之前,我们展示了市场上浪费了多少钱,我们从一个简单的例子开始。我们需要加载三个包及其依赖项(您可以在页面底部下载此帖子的R-)
install.packages("quantmod")
require(quantmod)
对于我们的第一个例子,我们将尝试模拟AT&T的回报。以下命令允许我们从雅虎财经下载价格信息并计算每月日志回报为了确定我在开始时所做的观点,我们将比较回报分布与正态分布。
att <- getSymbols("T", from = "1985-01-01", to = "2015-12-31", auto.assign = FALSE)
plot(density(attr), main = "Distribution of AT&T Returns")
rug(jitter(attr))
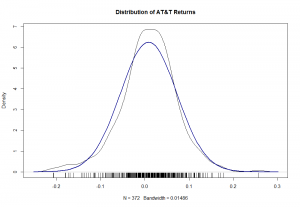
即使没有艺术史硕士学位,大多数人也会同意这两行不匹配。对于那些不依赖于这种视觉方法的人来说,可靠的Kolmogorov-Smirnov测试提供了一种更正式的方法。
set.seed(2013)
ks.test(attr, rnorm(n = length(attr), mean = mean(attr), sd = sd(attr)))
测试返回的p值为0.027,这远远不够(p值越小,我们必须得出的结论是两个分布不同)。接下来我们设置标准GBM功能。我完全清楚各种GBM函数作为众多包的一部分存在。尽管如此,我还是决定创建自己的函数,以使内部工作更加透明。
m((mu * dt * x) + #drift
rnorm(1, mean = 0, sd = 1) * sqrt(dt) * sigma * x) #random innovation
x
}
在这个简单的函数中(我知道有更优雅的方法来实现这一点,但结果保持不变)rnorm函数充当Wiener进程驱动程序。毋庸置疑,这并不尊重我们上面所看到的。相比之下,我的伪布朗函数从过去经验回报的核密度估计中抽样随机创新。
pseudoGBM <- function(x, rets, n, ...) {
N <
y[[i]] <- x + x * (mean(rets) + samp[i])
x <- y[[i]]
}
return(y)
}
不可否认,这个函数有点简洁,因为它假设静态增量(即dt = 1)并且几乎不需要用户输入。它只需要一个起始值(x),一个过去返回的向量(rets)和指定的路径长度(n)。...输入允许用户将其他命令传递给密度函数。这使用户可以通过添加带宽命令(bw =)来控制核密度估计的平滑度。没有任何进一步的麻烦,让我们开始使用上述功能进行模拟。在第一个例子中,我们仅使用起始值x中的两个函数来模拟一个价格路径,即系列中的最后一个价格。 要查看两个方法的执行情况,我们计算模拟序列的回报并将它们的分布与经验分布进行比较。
x <- as.numeric(tail(att$T.Adjusted, n = 1))
set.seed(2013)
attPGBMr <- diff(log(attPGBM))[-1]
d1 <- density(attr)
d2 <- density(attGBMr)
d3 <- density(attPGBMr)
plot(range(d1$x, d3$x), range(d1$y, d3$y), type = "n",
ylab = "Density", xlab = "Returns", main = "Comparison of Achieved Densities")
lines(d1, col = "black", lwd = 1)
lines(d2, col = "red", lty = 2)
lines(d3, col = "blue", lty = 3)

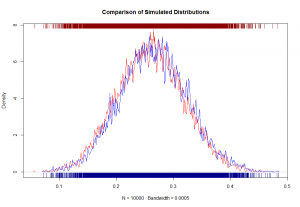
显然,我们看到PGBM函数(蓝线)在产生接近经验回报分布(黑线)的回报时优于标准GBM函数(红线)。同样,关键(或视觉上无能)的读者可以查看KS测试的结果。
ks.test(attr, attPGBMr)
ks.test(attr, attGBMr)
我们再次看到PGBM函数(p值= 0.41)远远优于GBM函数(p值= 0.02)。
高级示例
正如所承诺的那样,我们的第二个例子将展示当一个人在不能代表基础数据时错误地假设正态分布时,在线上有多少钱。自从金融黑暗时代醒来以来,欧洲特别表现出对结构性金融产品的渴望,这些产品可以参与股票市场,同时限制或消除下行风险。此类证券通常依赖于路径,因此通常使用GBM进行建模。
我们将使用Generali Germany提供的一种特定产品 - Rente Chance Plus - 这是我开发PGBM功能的最初原因。当我在私人银行工作时,我的任务是评估这个特定的安全性,从基于GBM的标准蒙特卡罗模拟开始,但很快意识到这还不够。Rente Chance Plus提供20%参与EUROSTOXX 50指数上限至15%的上限,初始投资和实现收益均无下行。安全性在每年年底评估。尽管Generali可以在20年的投资期内自由改变参与率和资本化率,但为了论证,我们将假设这些因素保持不变。
从上面反映我们的程序,我们首先从雅虎财经下载EUROSTOXX 50价格信息。
eu <- getSymbols("^STOXX50E", from = "1990-01-01", to = "2015-12-31", auto.assign = FALSE)
接下来,我们看看数据与正态分布的拟合程度如何,或者说多么糟糕。
plot(density(eur), main ibution of EUROSTOXX 50 Returns")
ks.tst(eu.r, rnm(n = length(eu.r), mean = mean(eu.r), sd = sd(eu.r)))
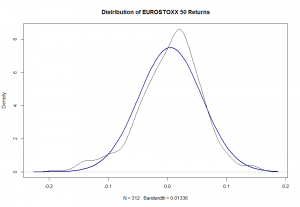
从严格的视角来看,这看起来比AT&T分布更糟糕。EUROSTOXX的回报显然是负面偏差,有点leptokurtic。KS测试返回p值为0.06,确认视觉不匹配。现在我们已经确定正态分布不是最合适的,我们可以看看错误地假设它的后果。我们将使用标准GBM和我的PGBM函数运行10,000次迭代的模拟并比较结果(如果您正在复制以下代码,请在等待时给自己喝杯咖啡。这将花费一些时间来运行)。
x <- as.numer
SIM1 <- as.data.frame(matrix(replicate(10000, {eu.GBM <- myGBM(x=x, mu = mean(eu.r), sigma = sd(
SIM2 <- as.data.frame(matrix(replicate(10000, {eu.PGBM <- pseudoGBM(x = x, n = 240, rets = eu.r)}), ncol = 1000, 10000), SIM1[seq(0, 240, 12), ])), start = c(2016), frequency = 1)
sim2 <- ts(as.matrix(rbind(rep(x, 10000), SIM2[seq(0, 240, 12), ])), start = c(2016), frequency = 1)
当然,我们对EUROSTOXX 50的价格水平不感兴趣,而是在参与率和上限率的约束下评估的回报。好消息是最困难的部分就在我们身后。计算回报和应用约束非常简单。对结果进行调整并不容易。
s1.r <-(sim2))
, s2.r*0.2, 0.15*0.20)
S1<-colSums(s1.r)
S2<-colSumS1,arkred")
rug(jitter(S2), side = 1, col = "darkblue")
ks.test(S1, S2)
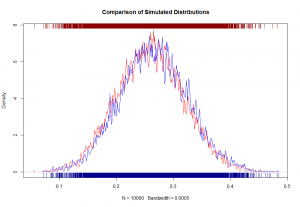
我们可以清楚地看到,PGBM函数(蓝色)模拟的累积回报表现出负偏差,并且范围比标准GBM函数(红色)模拟的回报更宽。请注意,由于安全性没有下行限制,分布在下尾区看起来并不相同。KS测试以极其确定的方式证实两种分布是不同的(然而,小的p值主要是由大样本量引起的)。现在回答这个百万美元的问题(实际上非常字面)。线路上有多少钱?好吧,如果Generali使用正态分布来预测回报并相应地重新投保,他们会......
均值(S1)-mean(S2)
...低估了累计回报率约0.6%。这可能看起来并不多,但如果我们假设安全数量为10亿欧元,那么Generali就达不到600万欧元 - 相当多的钱只是假设错误的分配。
结论和局限
那么我们从中学到了什么呢?用于对任何依赖路径的安全定价模型中的创新进行建模的分布可能会产生重大影响。虽然这个陈述本身就很明显,但分布差异的程度令人惊讶。当然,在Generali和其他机构工作的人可能比我更聪明,他们非常清楚正常分布并不总是最佳选择。但是,大多数人会使用更正式的(但可能只是不准确的)分布,如t分布或Cauchy分布。使用核密度分布是一种闻所未闻的方法。这是有原因的。
首先,不能保证核密度估计比未回避的正态分布更准确地表示未知的基础分布。使用过去的数据预测未来总是让任何数据科学家的口味都不好,但不幸的是我们别无选择。然而,标准GBM固有的正态分布确实过于依赖过去的信息(即历史均值和标准偏差),但在形式化解决方案方面具有巨大的优势,因为其核心作用(双关语仅用于后见之明)概率论。
其次,内核密度估计对使用的带宽非常敏感。如果带宽太大,您将获得平滑的分布,但是,与正态分布没有区别。如果带宽太小,您将获得一个非常强调极值的分布,特别是如果您估计内核密度的数据样本相当小。在上面的例子中,我们使用了密度函数中固有的自动带宽选择器,但几乎没有办法知道最佳带宽是什么。
上述方法还有其他局限性,因为我们做了许多非常不切实际的假设。在Generali的例子中,我们假设Generali没有改变参与率和上限率,这是不太可能的。然而,更一般地说,我们对金融市场做出了一些基本假设。知情(希望)我们假设资本市场是有效的。因此,我们假设回报中没有自相关,这是维纳过程的第二个条件,但这是否代表了基础数据?
acf(eu.r,main =“EUROSTOXX 50返回的自相关”)
