介绍HBase
从功能上讲:HBase主要是解决分布式文件系统HDFS不能随机读写而设计的,HBase是架设在HDFS之上的,所以HBase可以存储海量的数据,HBase又可以支持随机读写,所以HBase是一个支持海量数据随机读写的分布式存储系统。
从架构上讲:HBase中由zookeeper集群、一个HMaster以及若干个HRegionServer组成,zookeeper主要是负责存储HBase集群中的元数据信息(包括但不限于HMaster的位置、HRegionServer的信息、Table等元数据信息),HMaster负责管理HRegionServer,HRegionServer负责管理HRegion,HBase中的table就是由HRegion组成的
从数据模型上讲:HBase中的数据是以表的形式组织起来的,每张表都有自己属于的namespace(你可以把namespace看作Mysql中的数据库),表默认的话是创建在default这个namespace中。HBase中的表其实是一个类似于三层Map结构的模型,一个Table中包含很多的rowKey,每一个rowkey就是对应着一行(row)数据;每一行数据包含了若干个列(column),每一个列由一个column family(列蔟)和column qualifier(列名)组成,当然column qualifier可以为空;每一个列包含了若干个版本的数据值,这个版本默认是数据插入时的服务器时间戳,版本数默认是1个,当然版本以及版本的数量是可以设置的。
HBase的数据模型?
HBase中的数据是以表的形式组织起来的,每张表都有自己属于的namespace(你可以把namespace看作Mysql中的数据库),表默认的话是创建在default这个namespace中。HBase中的表其实是一个类似于三层Map结构的模型,如下图:
一个Table中包含很多的rowKey,每一个rowkey就是对应着一行(row)数据;每一行数据包含了若干个列(column),每一个列由一个column family(列蔟)和column qualifier(列名)组成,当然column qualifier可以为空;每一个列包含了若干个版本的数据值,这个版本默认是数据插入时的服务器时间戳,版本数默认是1个,当然版本以及版本的数量是可以设置的。
HBase数据模型:
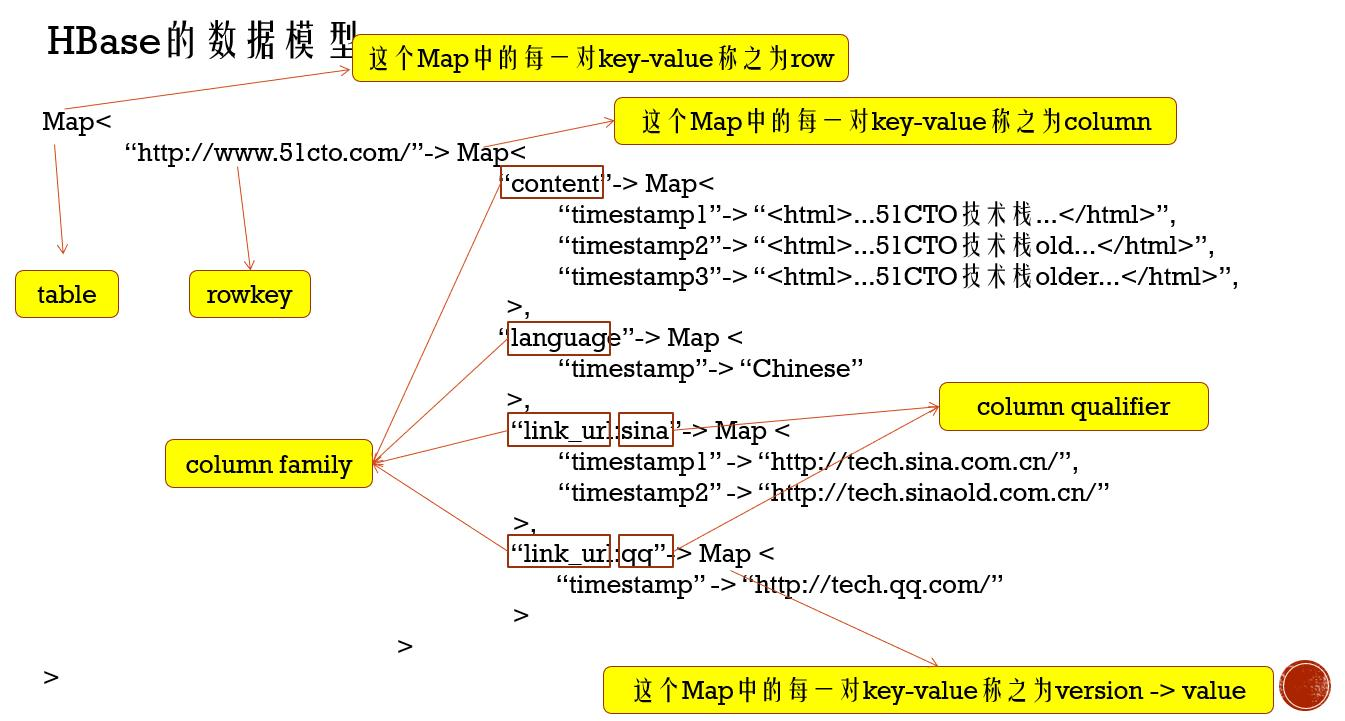
(1) 一个Table中包含很多的rowKey,每一个rowkey就是对应着一行(row)数据;每一行数据包含了若干个列(column),每一个列由一个column family(列蔟)和column qualifier(列名)组成,column family不能为空,column qualifier可以为空、
(2) 三层map:第一层map中的每一对Key-value 称之为row
第二层Map中的每一对key-value称之为column
第三层map中的每一对key-value称之为version——> value (版本,以时间戳)
namespace
更改设置version(1-6)
相比传统数据库,列式存储空值不占用空间,存储的更加合理
使用hbase shell创建一张表test,然后对这张表进行增删改查:
先创建一个新的namespace:
create_namespace ‘new_ns’
在new_ns中创建表:
create ‘new_ns:test’,‘f’, ‘e’ //test表中有2个column family
增加数据:
put ‘new_ns:test’, ‘rowkey-1’, ‘f:a’, ‘value1’
put ‘new_ns:test’, ‘rowkey-1’, ‘e’, ‘value2’
查询一行或者一列的数据:
get ‘new_ns:test’, ‘rowkey-1’
get ‘new_ns:test’, ‘rowkey-1’, {COLUMN => ‘f:a’}
更新一列的值:
put ‘new_ns:test’, ‘rowkey-1’, ‘f:a’, ‘value3’
删除一列或者一行的数据:
delete ‘new_ns:test’, ‘rowkey-1’, ‘f:a’
deleteall ‘new_ns:test’, ‘rowkey-1’
查看表中有多少行数据:
count ‘new_ns:test’
清空表的数据:
truncate ‘new_ns:test’
查看表结构:
desc‘new_ns:test’
修改表的结构:
disable ‘new_ns:test’
alter ‘new_ns:test’,{NAME=‘f’,TTL=‘15552000’}
enable ‘new_ns:test’
删除表:
disable ‘new_ns:test’ ----在删除之前需要disable
drop ‘new_ns:test’
描述下HBase的架构?
Hbase数据模型—— VERSION & TTL (Time To Live)
create 'new_ns:test',{NAME => 'f'},{NAME => 'e', VERSIONS => 3},{NAME => 'x'} 搜索是显示最近3列,默认get最近一列
get 'new_ns:test',{COLUMN => 'e',VERSION => 10} 依然显示最近三列
create 'new_ns:test',{NAME => 'f'},{NAME => 'e', VERSIONS => 1},{NAME => 'x', TTL => 5} 搜索时显示最近5秒钟内的所有数据,时间已过,column family对应的值全部清楚
alter new_ns:test',{NAME => 'x', TTL => 15} 更改属性(涉及更改底层数据,更新较慢)
HBase也是遵守主从架构的技术,由一个主HMaster和若干个从HRegionServer组成。HBase中的一张表的数据由若干个HRegion组成,也就是说每一个HRegion负责管理一张表中的一段数据,HRegion都是分布式的存在于HRegionServer中(也就是说一个HRegionServer是管理多个HRegion的进程),所以说HRegion是HBase表中数据分布式存储的单位。那么一个HRegion中又是由若干个column family的数据组成(HRegion对应的表有几个column family,那么HRegion中就管理几个column family的数据);在HRegion中每个column family数据由一个store管理,每个store包含了一个memory store和若干个HFile组成,HFile的数据最终都会落地到HDFS文件中,所以说HBase依赖HDFS,存在HBase中的数据最终都会落地到HDFS中。
在HBase中还有一部分元数据信息,比如HMaster的状态信息、HRegionServer的状态信息以及HRegion的状态信息等,这些信息都是存储在zookeeper集群中,zookeeper集群在HBase中处于一个分布式协调服务的角色,客户端要连接HBase集群的话,也是直接连接zookeeper集群即可,客户端可以在zookeeper中找到需要和HBase的哪一个进程通讯。给出如下的架构图:

单个值是怎样存储在HBase的表中的?
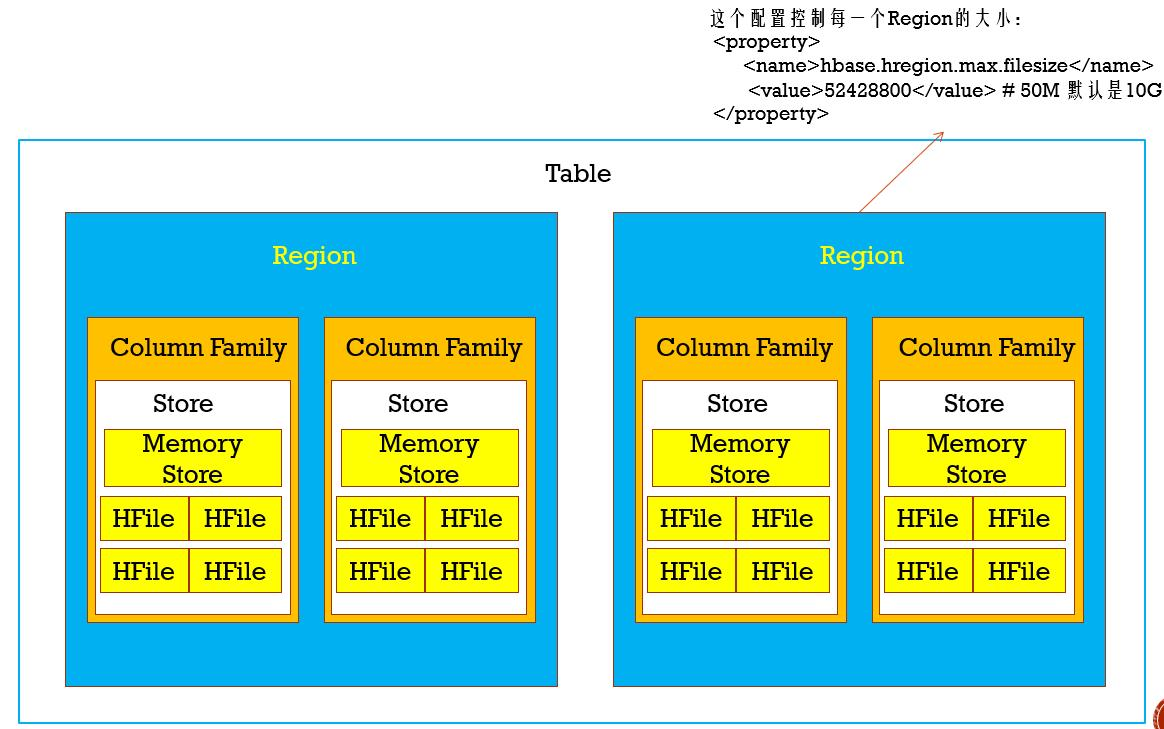
组织结构: 一个table对应多个Region,一个region对应多个Column Family,一张表有多少个Column Family,一个Region则对应多少个Column Family,Column Family里面有一个Store,一个Store里面含有一个MemoryStore和多个HFile。
Table-> Region的关系:
一个Table有多个Region,每一个Region达到指定的数据量后(默认是10G),进行Region切分。Hbase最基本的存储单元是Region,分布式的存储在所有HRegionServer上
每一个Region负责管理和存储一个Table中的某段数据。
每一个table的RowKey是按照字符串的自然顺序升序排列的 可以使数据均匀分布
Region-> Column Family的关系:
一个region对应多个Column Family,一张表有多少个Column Family,一个Region则对应多少个Column Family,Column Family数据存储的基本单元
一个Region负责管理和存储Table中所有的Column Family数据
一个Region负责管理和存储一个或者多个Column Family的数据
3、Column Family -> Store的关系:
一个Column Family对应着一个Store
一个Store中含有一个MemoryStore和若干个HFile 数据先存储在MemoryStore,达到一定的容量后在存储在HFile中
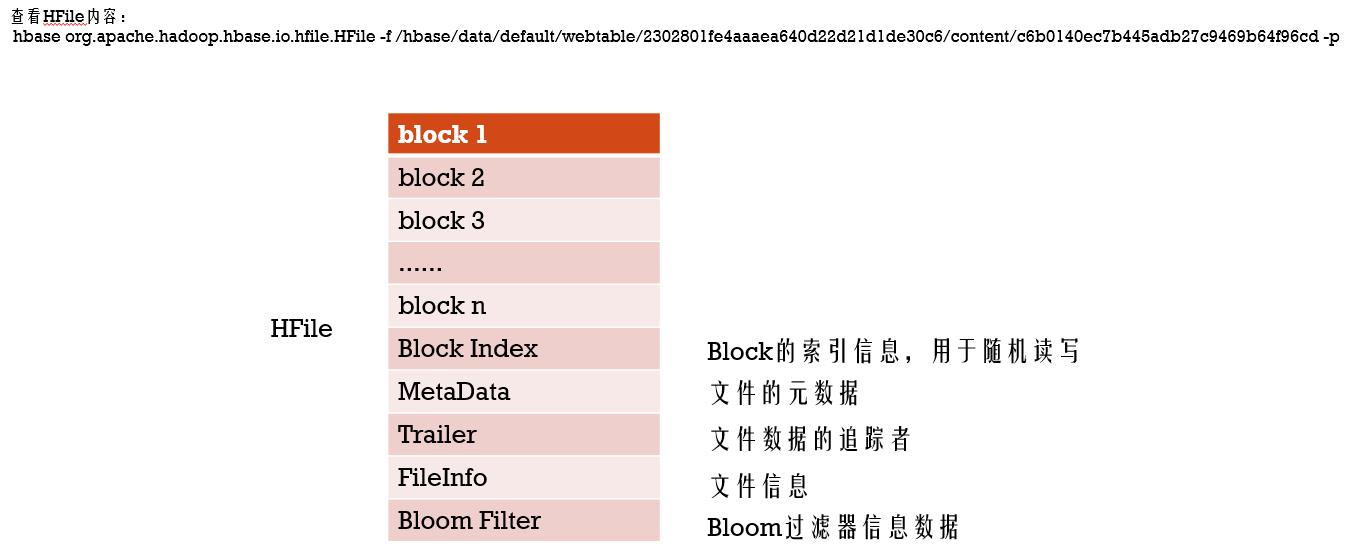
4、HFile -> Block的关系:
一个HFile含有若干个不同类型的Dtata Block 及其他元数据信息 即 Meta data
Block的大小通常为8K到1MB,默认的大小是64KB
Block的类型有:Data Blocks、Index Blocks、Bloom filter Blocks以及Trailer block
5、Block -> KeyValue的关系:
一个Block包含一个magic数字和若干个KeyValue的数据
若干个 key value合计达到64kb组成一个block
put数据根据Rowkey 的排序放在相应的block中去,一个put操作值是存储在table下面的对应的某一个Region下面的对应的CF下面的Hfile下面的block中的KeyValue,每一个block在HFile中都是有索引信息的。请求获取数据可通过索引信息拿到值所在的block信息,只需要扫描64kb的block就可拿到相应的值,进而达到高校的数据效果,进而支持高效的随机读写。


HFile
答: HBase依赖HDFS,存在HBase中的数据最终都会落地到HDFS中,HBase中的数据在HDFS中就是以HFile这种格式的文件组织起来的。一个HFile包含了若干个不同类型的Block,每一个Block的大小通常为8K到1M(默认是64K);Block的类型有Data Blocks、Index Blocks、Bloom filter Blocks以及Trailer block,一个Data Block包含一个magic数字和若干个KeyValue的数据。Index Blocks是记录每一个Data Block的数据位置(就是索引信息)用于随机读写
查看HFile内容:hbase org.apache.hadoop.hbase.io.hfile.HFile -f hfile_name
Block Encoder与Block Compressors
Prefix RowKey的存储按升序排列,处理相对容易,只存储不容部位,达到空间省略
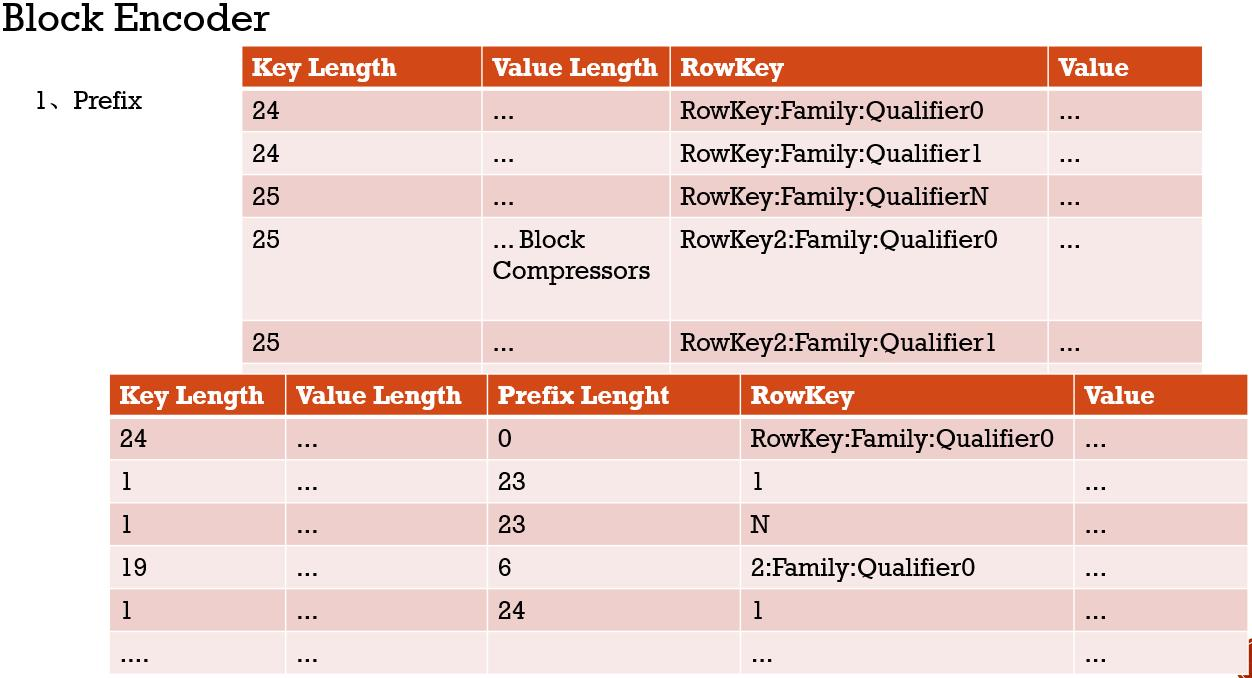
diff 相同的数据不在存储,进而达到空间节省
timestamp存储时间差
diff
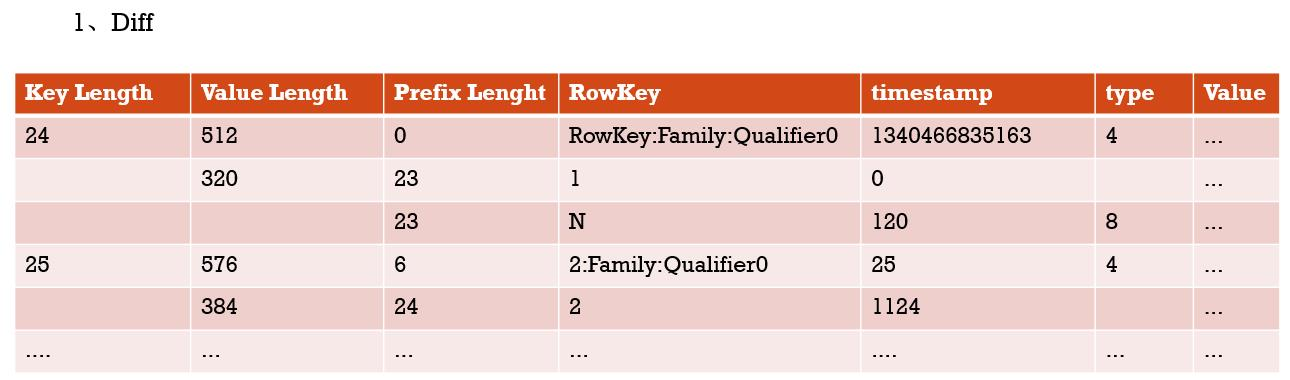
2、Fast Diff
如果你的rowkey很长,并且有很多的Column的话,则推荐使用Fast Diff,实现比Diff更快
Block Compressors
(1、none
(2、Snappy
(3、LZO
(4、LZ4
(5、GZ
默认 不压缩
1、如果rowkey很长的话或者这个column family含有很多的column的话,则使用Block Encoder
推荐使用Fast Diff
2、如果value很大的话,则需要使用Block Compressors
3、对于访问不频繁的数据(code data),使用GZ压缩器,因为GZ需要更多的cpu资源,但是有很好的压缩率
4、对于访问频繁的数据(hot data),使用Snappy或者LZO压缩器,因为Snappy或者LZO不需要更多的cpu资源,但是压缩率没有GZ高
5、大部分的场景下默认使用Snappy或者LZO就好,因为他们提供了更好的性能Snappy比LZO表现还稍微好点
create 'test_encoder_compress', {NAME => 'c', COMPRESSION => 'SNAPPY', DATA_BLOCK_ENCODING => 'FAST_DIFF'}, {NAME => 'l'}
create 'test_encoder_compress', {NAME => 'c', COMPRESSION => 'GZ', DATA_BLOCK_ENCODING => 'FAST_DIFF'}, {NAME => 'l'}
Bloom Filter
create 'webtable',{NAME => 'c', COMPRESSION => 'GZ', DATA_BLOCK_ENCODING => 'FAST_DIFF'}, {NAME => 'l', BLOOMFILTER => 'ROW'}
Bloom Filter取值: NONE, ROW(默认), ROWCOL
ROW:
根据KeyValue中的row来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v)
sf2包含kv3(r3 cf:q1 v)、kv4(r4 cf:q1 v)
如果设置了CF属性中的bloomfilter为ROW,那么get(r1)时就会过滤sf2,get(r3)就会过滤sf1
ROWCOL:
根据KeyValue中的row+qualifier来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v)
sf2包含kv3(r1 cf:q2 v)、kv4(r2 cf:q2 v)
如果设置了CF属性中的bloomfilter为ROW,无论get(r1,q1)还是get(r1,q2),都会读取sf1+sf2;而如果设置了CF属性中的bloomfilter为ROWCOL,那么get(r1,q1)就会过滤sf2,get(r1,q2)就会过滤sf1
HBase的读写缓存机制
写缓存机制: Client====>hbase:meta===>RS===>HRegion===>WAL(稳定性和高可用性)===>Store===>MemoryStore===>HFile
所有的数据先写入到Memory Store中,如果Memory Store所占的内存符合下面的规则的话,则会将数据flush到磁盘中:
(1)、当一个Region中所有MemoryStore内存之和大于hbase.hregion.memstore.flush.size(默认大小是:134217728字节(128M))的时候,这个MemoryStore所在的Region中的所有MemoryStore都会写到磁盘
(Hbase中的删除并不是真正的删除,仅仅只是打上标记delecolum,在查询时会过滤掉其标记数据,在数据压实是会真正的删除数据)
(2)、当一个HRegionServer中所有的MemoryStore加在一起的大小大于hbase.regionserver.global.memstore.upperLimit默认大小是堆内存的40%,那么这个HRegionServer中的所有的Region中的内存数据都会flush到磁盘中,当所有的内存使用达到
问题: 防止内存不稳定,提高可靠性
引用WAL机制 (Write Ahead Log 预写日志)
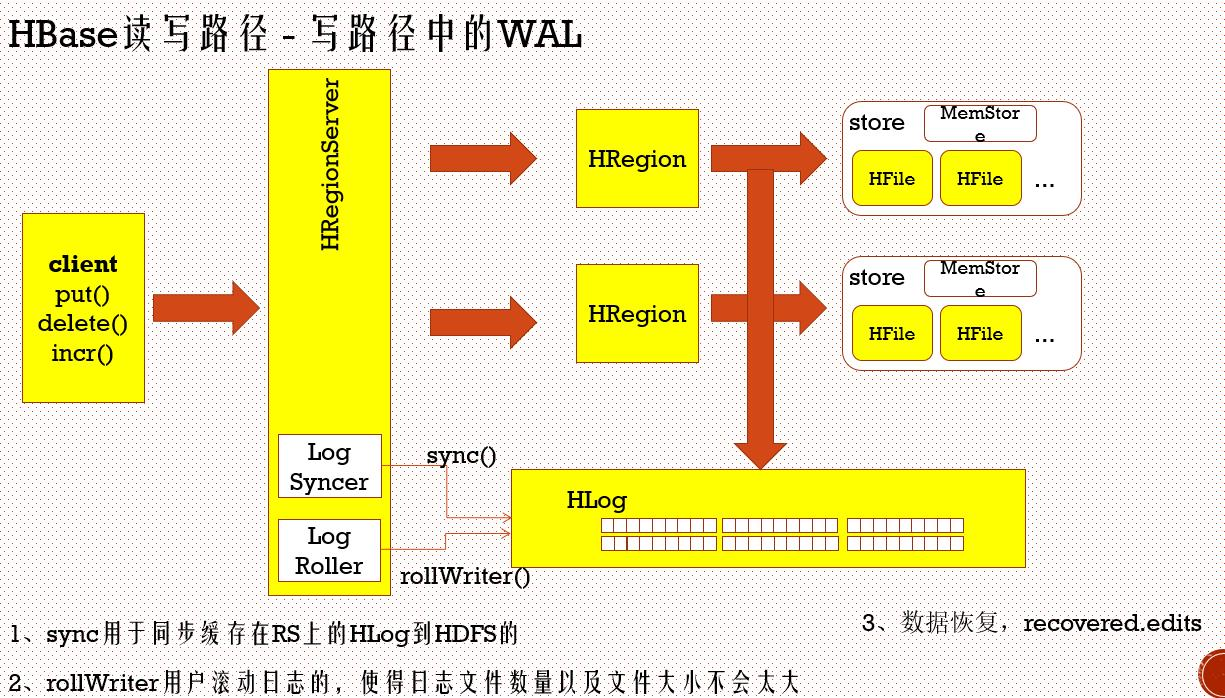
数据先写道HDFS中的HLog中去,写完后,在把数据put到MemoryStore中去
LogStner :用于同步缓存在RegionServer上的HLog到HDFS
rollWriter (1)用于滚动日志,使得日志文件数量以及文件大小不会太大,(2)MemoryStore中的文件已经持久化到HFile中去,清理掉HLog中的数据
数据恢复: recovered.edits 在HDFS中每个region中都有一个 recovered.edits 自动回复
(HLog默认开启状态,但消耗性能)
读缓存机制:
Client(获取对应RS所在的机器)===>hbase:meta===>RS===>HRegion===>Store===>MemoryStore(查看是否有相应数据)===>BlockCache(所有的Region共用一个BlockCache)===>HFile(读到的数据快放在BlockCache中)
三种缓存过期策略:(内存容量一定的情况下,内存满了,清理数据算法)
1、FIFO -> 按照“先进先出”的原理来淘汰数据
2、LRU(Least recently used, 最近最少使用) -> 根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”
3、LFU(Least frequently used, 最近不常使用) -> 根据数据的历史访问频率来淘汰数据,
其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”
LruBlockCache中的三种Block priority:
1、Single access priority : 当一个Block第一次从HDFS中加载到内存中就是这个级别
2、Multi access priority : 当一个Block再次被访问的时候就会变成这个级别
3、In-memory access priority : 当一个cf被设置为In Memory的时候,则不管这个cf的block被访问了多少次都不会从内存中淘汰,比如hbase:meta表中的cf,数据量小,经常访问
HColumnDescriptor.setInMemory(true);
hbase(main):003:0> create 't', {NAME => 'f', IN_MEMORY => 'true'}
读缓存策略包含两种,一种是LruBlockCache,一种是BucketCache,其中默认是使用LruBlockCache
除了缓存需要读取的block之外,还需要缓存如下的数据:
1、hbase:meta
2、HFile Indexes
3、Keys
4、Bloom Filters
LruBlockCache是使用LRU的算法实现的缓存策略
如果要使用BucketCache的话,需要配置开启,BucketCache一般和LruBlockCache配合使用,配合使用的方式有两种:
(1)、LruBlockCache用于缓存Index和Bloom这种META block数据,而BucketCache用于缓存真的数据
(2)、BucketCache作为LruBlockCache的二级缓存使用hbase.regionserver.global.memstore.lowerLimit的时候就不会flush了

HBase中的compaction机制的
随着时间的推移,Store中小的HFile越来越多,使得性能下降,这个时候就需要Compaction了。Compaction就是将小的HFile合并压缩成一个大的HFile文件。Compaction分为Minor compactions和Major compactions。
Minor compactions(局部压缩):进行局部的压缩,选择一个Store中的小量的HFile进行合并成一个大的HFile文件
Major compactions(全局压缩):合并一个表的所有Store中的HFiles,使得一个Store只有一个HFile。
1、Major Compaction还会真的删除需要删除的数据
2、Major Compaction还会真的删除多余版本的数据
3、默认是每7天会自动执行一次Major Compaction,将hbase.hregion.majorcompaction(默认是604800000 milliseconds,即7天)设置为0的话,则表示禁止自动压缩
执行Major Compaction的时候会使得HBase整个集群都非常慢,因为Major Compaction需要大量的资源
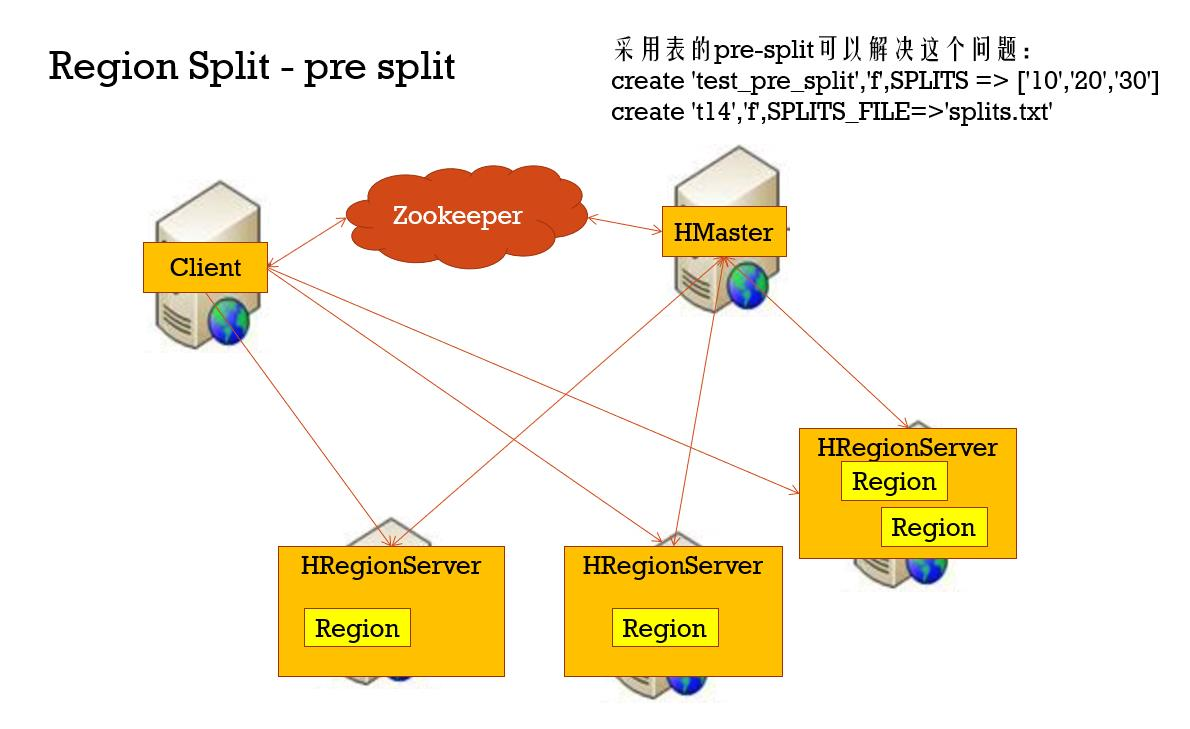
防止热点写,在创建表的时候预切分成4个region(3个切分点),进而解决热点问题,根据rowkey的类型设计




太多的region
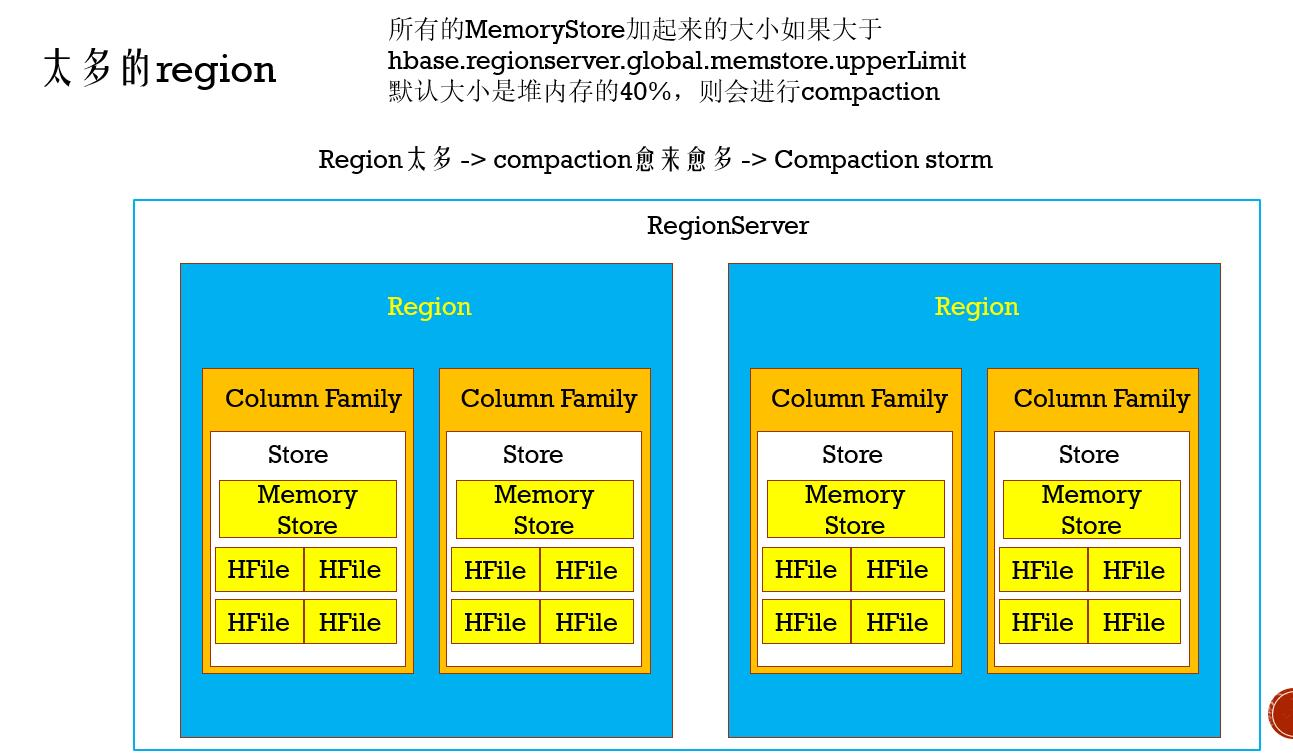
1、snapshots time out
2、compaction storms
3、客户端的操作会超时(比如flush)
4、bulk load会超时(可能会抛出RegionTooBusyException)
造成太多region的原因
1、为每一个Region的file size配置过小
2、不合理的对region进行了切分或者预切分
merge_region 'ENCODED_REGIONNAME','ENCODED_REGIONNAME' merge_region 'ENCODED_REGIONNAME','ENCODED_REGIONNAME',true
Balancing
保持Region可以均匀的分布在每一个RegionServer上
HMaster每隔:
hbase.balancer.period(默认是300000ms即5分钟)
会进行一次Balance
Snapshot
在hbase-site.xml中配置如下参数,然后开启snapshot功能
<property>
<name>hbase.snapshot.enabled</name>
<value>true</value>
</property>