一、Python的对象存储有2种方式:
1)小整数池:-5到256的数字都存在这里,当我们定义一个对象时,不会重新分配内存地址,而是指向到小整数池的一个位置;
栗子:
a=25
b=25
c=288
d=288
其中:a 和 b 的内存地址是一个;c 和 d 指向2个内存地址;
2)intern机制(大整数池):用来存放一些字符串(数字、字母、下划线的组合),如果包含特殊字符,则不在大整数池中;
栗子:
str1='abc_001'
str2='abc_001'
str3='abc+001'
str4='abc+001'
其中:str1 和 str2 的内存地址是一个;str3 和 str4 指向2个内存地址(包含特殊字符+);
二、浅拷贝和深拷贝
举个栗子:
import copy
name=['lili','lucy']
list1=['lilei',name] # list1=['lilei','lili','lucy']
list2=list1 # 指向list1 list2=['lilei','lili','lucy']
list3=list1.copy() # 浅拷贝 list3=['lilei',name]
list4=copy.deepcopy(list1) # 深拷贝 list4=['lilei',X] X=['lili','lucy']
其中:list2是指向list1,和list1的内存地址一样。list3 和 list4是对list1的拷贝,内存地址不同。
对name列表进行改变,name.append('pete'),然后查看几个列表的值:
list1=['lilei','lili','lucy','pete']
list2=['lilei','lili','lucy','pete']
list3=['lilei','lili','lucy','pete'] #浅拷贝是拷贝的列表名称,所以在对应列表发生变化后,此处会变化
list4=['lilei','lili','lucy'] #由于深拷贝把里面的列表值也拷贝过来了,所以在对应列表发生变化后,此处不会变化
三、内存回收机制
Python的垃圾回收,采取的是引用计数为主,标记-清除+分代回收为辅的回收策略。
1)引用计数机制:
对于每一个对象的使用标记次数。
如a=1000,此时1000被引用1次,当把a重新赋值时,1000的引用次数变成了0,此时就可以进行回收了。
如果a=1000,b=a,那边1000就被引用了2次。
对于小整数池和大整数池的值,再不被对象引用时,不存在回收的说法。
如果2个对象存在相互引用的情况,如:a=[1,2] b=[2,3] a.append(b[1]) b.append(a[0]) ,在这种情况下如果还采用引用计数的方式进行回收就会陷入死循环,导致内存泄漏。
2)标记-清除机制:
标记清除算法是一种基于追踪回收技术实现的垃圾回收算法。
它分为2个阶段:第一阶段是标记阶段,GC会吧所有活动的对象打上标记,第二阶段就是把那些没有被标记的对象进行回收。
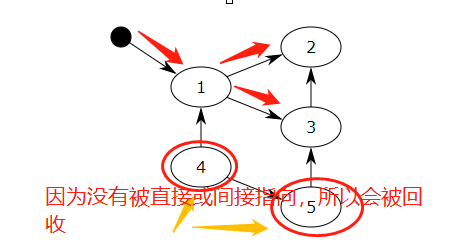
对象之间通过引用(指针)进行连接,构成一个有向图。从根对象出发,沿着有向边进行遍历对象,可达的对象标记为活动对象,不可达的对象就是要被清除的非活动对象。根对象就是全局变量、调用栈等。
如图中,根对象指向1,1再指向 2 和 3 ,3又重复指向了2 。 4 和 5 没有被指向,所以会被回收。
标记清除算法作为Python的辅助垃圾收集技术,主要处理的是一些容器对象,比如list、dict、tuple等,
因为对于字符串、数值对象是不可能造成循环引用问题。
Python使用一个双向链表将这些容器对象组织起来。
不过,这种简单粗暴的标记清除算法也有明显的缺点:清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
3)分代回收机制
分代回收策略着眼于提升垃圾的回收效率。
在任何的编程中,对于变量在内存中的创建/销毁,总有频繁和不那么频繁。比如任何程序中总有全局变量和部分变量,而在垃圾回收前,需要先进行一次垃圾检测,即检测这个对象是不是垃圾,该不该被回收。
当对象很多的时候,垃圾检测将耗费比垃圾回收更多的时间。对于这种多对象的程序,我们可以把一些频率相同的对象称为“同一代”对象,垃圾检测的时候可以对频率高的多检测基础,反之可以少检测几次。这样就提高了垃圾回收的效率。
Python中设有一代回收列表、二代回收列表和三代回收列表。
当一代回收列表中的值超过700个时,就会将引用计数次数为0的值进行回收,如此回收10次后,就会把第一代列表中的数据存入第二代回收列表中,如此再到第三代回收列表中。
对于循环银行的情况,一般的垃圾回收方式肯定是无效的了,这个时候就需要显示地调用一些操作来保证垃圾的回收 和内存不泄露。这就要用到Python内建的垃圾回收gc模块了。
