在开始之前,我们先来明确一下什么是数据驱动,在百度百科中数据驱动的解释是:数据驱动测试,即黑盒测试(Black-box Testing),又称为功能测试,是把测试对象看作一个黑盒子。利用黑盒测试法进行动态测试时,需要测试软件产品的功能,不需测试软件产品的内部结构和处理过程。数据驱动测试注重于测试软件的功能性需求,也即数据驱动测试使软件工程师派生出执行程序所有功能需求的输入条件。

这说的是什么?为什么我完全不懂!!!咱们来分析一下。
利用黑盒测试法进行动态测试时,需要测试软件产品的功能,不需测试软件产品的内部结构和处理过程 – 重点在测试功能,不需要考虑内部处理过程
也即数据驱动测试使软件工程师派生出执行程序所有功能需求的输入条件 – 重点在测试时候的输入条件
在实际的自动化测试中,数据驱动是通过数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变,简单的来说,就是将测试数据与实际的测试代码区分开。
Python中大部分人最先接触的测试框架就是unittest,可是unittest本身并不支持数据驱动,需要借助ddt来实现。接着我们就用unittest+ddt来给大家看一下数据驱动。
ddt是 “Data-Driven Tests”的缩写。官方资料是:http://ddt.readthedocs.io/en/latest/。
下面是每个组件的简单介绍:
ddt.ddt:
装饰类,用于unittest.TestCase子类的类装饰器。
ddt.data:
添加到unittest.TestCase测试用例上的方法装饰器。
ddt.file_data(value):
添加到unittest.TestCase测试用例上的方法装饰器。
value应该是文件目录的路径。文件应该包含JSON编码的数据,可以是列表,也可以是dict。
如果文件中是列表,每个列表的值会作为测试用例参数,同时作为测试用例方法名后缀显示。
如果文件中是字典,字典的key会作为测试用例方法的后缀显示,字典的值会作为测试用例参数。
ddt.unpack:
传递的是复杂的数据结构时使用。比如使用元组或者列表,添加unpack之后,ddt会自动把元组或者列表对应到多个参数上。
我们来用实例感受一下每个组件,先用data来传入比较简单的值,来做数据驱动。
简单数据注入:
import ddt
import unittest
@ddt.ddt
class TestCase(unittest.TestCase):
def setUp(self):
print("Before every test case!")
@ddt.data(1,2,3,4,5,6)
def test_case_01(self,value):
print("value is: "+ str(value))
if __name__ == "__main__":
unittest.main()
运行中发现,有6组数据,一共执行了6次

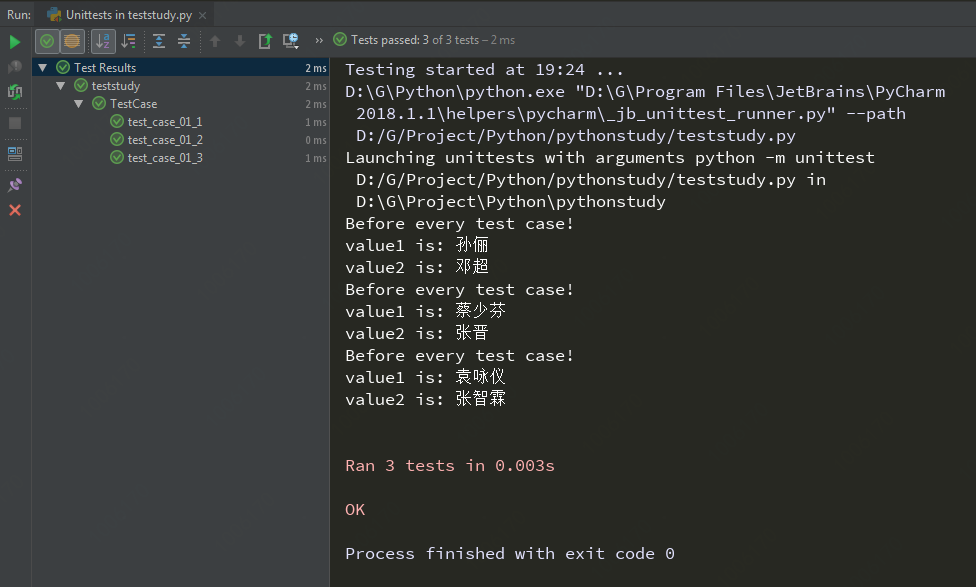
复杂数据注入:
如果尝试着用一些比较复杂的数据,比如元组/列表/字典,我们就需要调用unpack来实现,下面是一些例子
import ddt
import unittest
@ddt.ddt
class TestCase(unittest.TestCase):
def setUp(self):
print("Before every test case!")
@ddt.unpack
@ddt.data({'value1': '孙俪', 'value2': '邓超'},
{'value1': '蔡少芬', 'value2': '张晋'},
{'value1': '袁咏仪', 'value2': '张智霖'})
def test_case_01(self,value1,value2):
print("value1 is: " + value1)
print("value2 is: " + value2)
@ddt.unpack
@ddt.data((1,2),(3,4),(5,6))
def test_case_02(self, value1, value2):
print("value1 is: " + str(value1))
print("value2 is: " + str(value2))
@ddt.unpack
@ddt.data([1,9],[2,8],[3,7])
def test_case_03(self, value1, value2):
sum = value1 + value2
self.assertEqual(sum, 10)
if __name__ == "__main__":
unittest.main()

import ddt
import unittest
data = ({'value1': '孙俪', 'value2': '邓超'},
{'value1': '蔡少芬', 'value2': '张晋'},
{'value1': '袁咏仪', 'value2': '张智霖'})
@ddt.ddt
class TestCase(unittest.TestCase):
def setUp(self):
print("Before every test case!")
@ddt.data(*data)
def test_case_01(self,data):
print("value1 is: " + data['value1'])
print("value2 is: " + data['value2'])
if __name__ == "__main__":
unittest.main()
文件数据注入:
有时候,将测试数据直接写到Python文件里不利于我们对数据的管理,这时候,我们就可以借助文件来做数据的注入。
创建一个yml文件:
- 1
- 2
- 3
- 4
创建一个json文件:
{
"positive_integer_range": {
"start": 0,
"end": 2,
"value": 1
},
"negative_integer_range": {
"start": -2,
"end": 0,
"value": -1
},
"positive_real_range": {
"start": 0.0,
"end": 1.0,
"value": 0.5
},
"negative_real_range": {
"start": -1.0,
"end": 0.0,
"value": -0.5
}
}
然后将yml与json文件注入测试用例中
import ddt
import unittest
@ddt.ddt
class TestCase(unittest.TestCase):
def setUp(self):
print("Before every test case!")
@ddt.file_data('testdata_dic.json')
def test_case_01(self,start,end,value):
print("start is: " + str(start))
print("end is: " + str(end))
print("value is: " + str(value))
@ddt.file_data('testdata_list.yml')
def test_case_02(self, value):
print("value is: " + str(value))
if __name__ == "__main__":
unittest.main()
运行之后结果为:
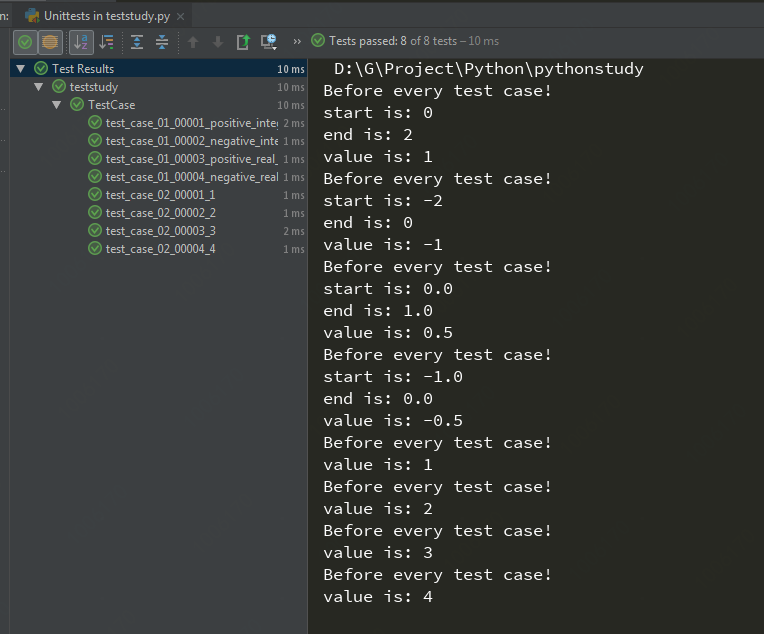
这样,就为我们数据驱动的用法提供了多样性。
最后,希望本文能帮助到大家。
作 者:Testfan Chris
出 处:微信公众号:自动化软件测试平台
版权说明:欢迎转载,但必须注明出处,并在文章页面明显位置给出文章链接