Linux中常用的监控性能的命令有:
$ sar: 能查看CPU的平均信息,还能查看指定CPU的信息。与mpstat相比,sar能查看CPU历史信息
$ mpstat: 能查看所有CPU的平均信息,还能查看指定CPU的信息。 与sar相比,mpstat对CPU能实时状态进行监控
$ vmstat:监控服务器整体的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)
$ iostat: 主要用于监控系统设备的io负载情况
一、sar
sar(System ActivityReporter系统活动情况报告)是目前Linux上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等,sar命令由sysstat安装包安装。
sar命令使用参数详情可以使用sar --help来查看
常用参数
-o :将监控的的信息以二进制方式保存到文件中
-f :从指定的文件读取报告
-P:报告每个CPU的状态
-b:显示I/O和传递速率的统计信息
-R::显示内存状态
-w::显示交换分区的状态
-q: 查看平均负载
-d: 磁盘使用统计信息
sar //无参数界面情况
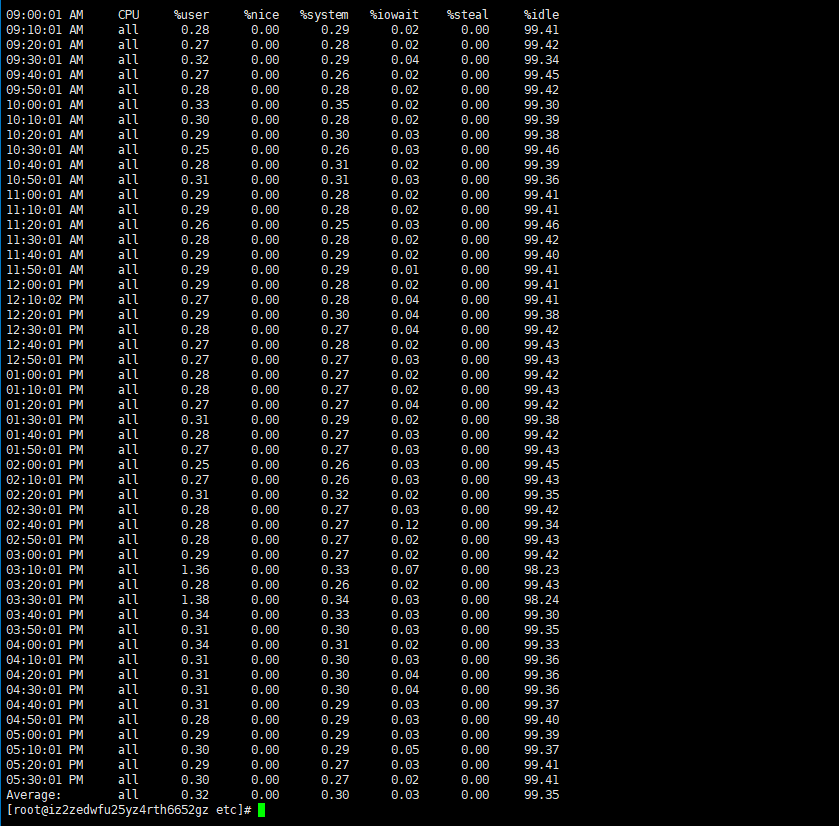
字段的含义
%user 在internal时间段里,用户态的CPU时间(%),不包含nice值为负进程 (usr/total)*100
%nice 在internal时间段里,nice值为负进程的CPU时间(%) (nice/total)*100
%system 在internal时间段里,内核时间(%) (system/total)*100
%iowait 在internal时间段里,硬盘IO等待时间(%) (iowait/total)*100
%steal
%idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%) (idle/total)*100
sar -o cpulog 1 4 //每1秒采样一次CPU信息,连续4次,并将采样的信息以二进制形式存入当前目录下的文件cpulog中,若删除4,下面命令将会是一直连续1秒采样一次
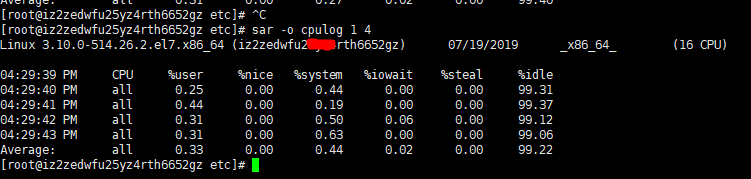
sar -f cpulog //使用上面命令保存的文件使用cat、head等命令查看文件全是乱码,需要使用sar -f {filename}才能查看
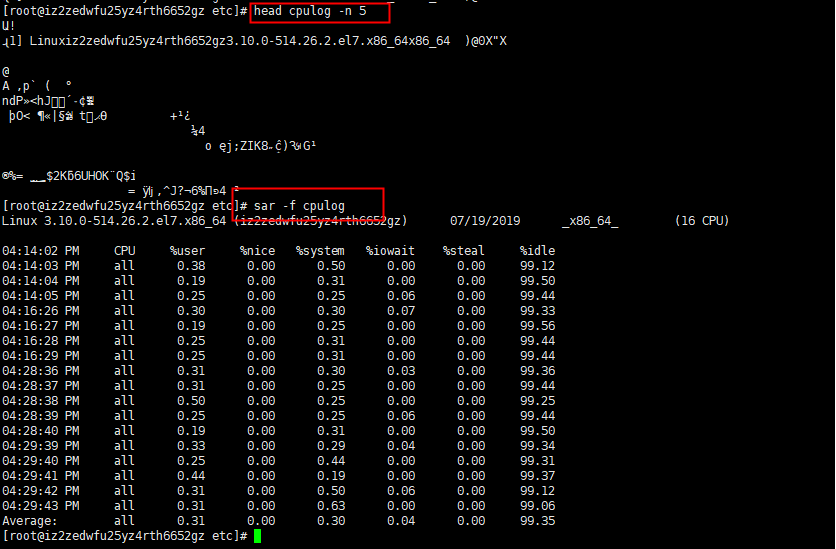
查看所有CPU信息 0 表示CPU核号,若为ALL返回所有核号的信息 1 表示刷新频率 2 表示刷新次数 # sar -P 0 1 2

sar -q 查看队列的长度(等待运行的进程数)和负载的状态

sar -r查看内存使用情况

sar -w查看系统swap分区的统计信息

sar -b查看I/O传递速率的信息

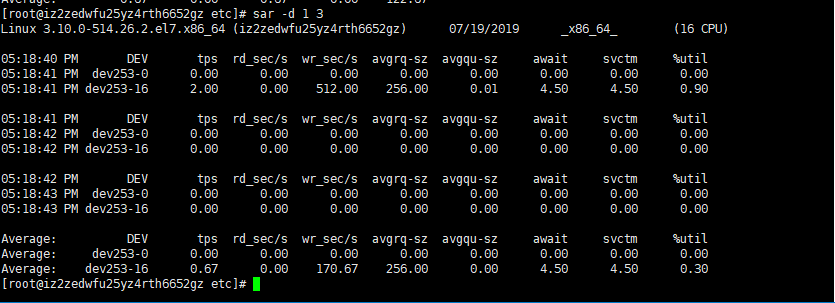
sar -d磁盘使用统计信息
二、mpstat
mpstat是Multiprocessor Statistics的缩写,是实时监控工具,报告cpu的一些统计信息,这些信息都存在/proc/stat文件中,在多CPU系统里,其不但能查看所有的CPU的平均状况的信息,而且能够有查看特定的cpu信息,mpstat最大的特点是:可以查看多核心的cpu中每个计算核心的统计数据
# mpstat 1 5 //连续5次,每次间隔1秒采样CPU信息
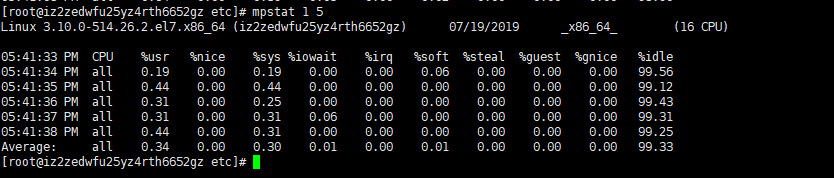
字段的含义
%user 在internal时间段里,用户态的CPU时间(%),不包含nice值为负进程 (usr/total)*100
%nice 在internal时间段里,nice值为负进程的CPU时间(%) (nice/total)*100
%sys 在internal时间段里,内核时间(%) (system/total)*100
%iowait 在internal时间段里,硬盘IO等待时间(%) (iowait/total)*100
%irq 在internal时间段里,硬中断时间(%) (irq/total)*100
%soft 在internal时间段里,软中断时间(%) (softirq/total)*100
%idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%) (idle/total)*100
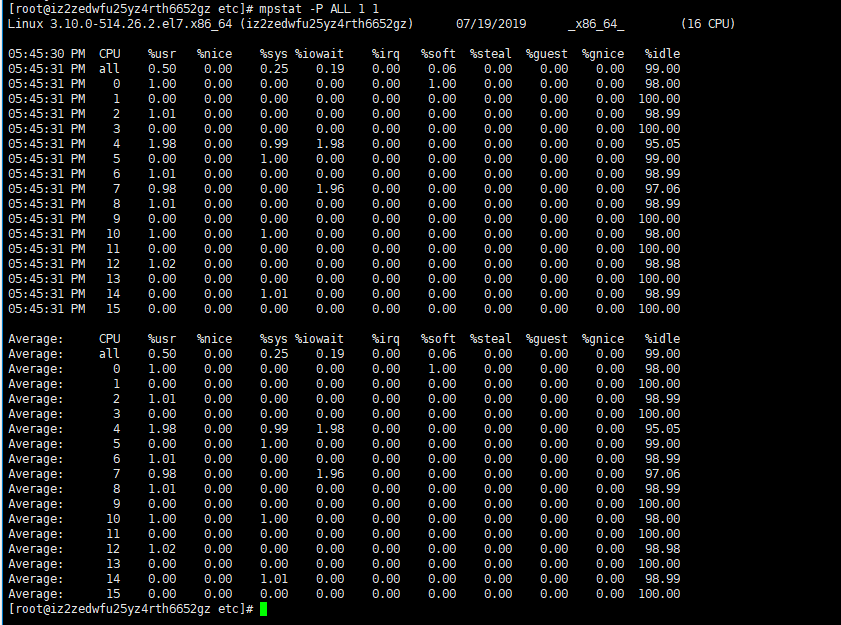
查看所有CPU单个信息 # mpstat -P ALL 1 1
三、vmstat
vmstat可以展现指定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。
# vmstat 1 4 //连续4次,每次间隔1秒采样信息

1、Procs(进程)
r:表示运行队列(就是说多少个进程真的分配到CPU)。
- 如果长期大于超过了CPU数目,有多数的进程等待CPU,需要增加cpu;
- 大于系统中可用CPU个数的4倍的话,统面临着CPU短缺、或CPU速率过低;
- r 和 b 不能高于5倍,如果r 经常大于4倍,且id 经常少于40,则表示CPU 负荷很重。
b:列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。
2.Memory(内存)
swpd:虚拟内存已使用的大小(k表示)。
- 如果大于0,表示你的机器物理内存不足了。
- 如果swpd的值不为0,或者比较大,比如超过了100m,只要si、so的值长期为0,系统性能还是正常
free:空闲的物理内存的大小
buff:对块设备的读写的缓存(系统缓存)
cache:一般作为文件系统的cache
- 如果cache较大,说明用到cache的文件较多,如果此时IO中bi比较小,说明文件系统效率比较好。
3.Swap
si: 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。
so:每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上
- si与so说明:当内存的需求大于RAM的数量,服务器启动了虚拟内存机制,通过虚拟内存,可以将RAM段移到SWAP DISK的特殊磁盘段上,这样会出现虚拟内存的页导出和页导入现象,页导出并不能说明RAM瓶颈,虚拟内存系统经常会对内存段进行页导出,但页导入操作就表明了服务器需要更多的内存了,页导入需要从SWAP DISK上将内存段复制回RAM,导致服务器速度变慢。这里还得配合CPU使用率来看。
- 如果内存的占用率比较高,但是,CPU的占用很低的时候,可以考虑是有很多的应用程序占用了内存没有释放.
- 如果是ORACLE出现这种情况:
1.最简单的,加大RAM。2、改小SGA,使得对RAM需求减少。3、减少RAM的需求(如:减少PGA)
4.IO(现在的Linux版本块的大小为1kb)
bi:块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte
bo:块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
- 这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大应该考虑均衡磁盘负载,可以结合iostat输出来分析。
5.system(系统)
in:表示在某一时间间隔中观测到的每秒设备中断数。
cs:列表示每秒产生的上下文切换次数,VMSTATu547du4ee4如当 cs比磁盘 I/O 和网络信息包速率高得多,都应进行进一步调查。
6.CPU(以百分比表示)
us:显示了用户方式下所花费 CPU时间的百分比。
- us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。
sy:显示了内核进程所花费的cpu时间的百分比。
- 这里us + sy的参考值为80%,如果us+sy大于 80%说明可能存在CPU不足。
id:cpu处在空闲状态的时间百分比
- vmstat中CPU的度量是百分比的。当us+sy的值接近100的时候,表示CPU正在接近满负荷工作。但要注意的是,CPU满负荷工作并不能说明什么,UNIX总是试图要CPU尽可能的繁忙,使得任务的吞吐量最大化。唯一能够确定CPU瓶颈的还是r(运行队列)的值。
- 如果空闲时间(cpu id)持续为0并且系统时间(cpu sy)是用户时间的两倍(cpu us)系统则面临着CPU资源的短缺.
wa:显示了IO等待所占用的CPU时间的百分比。
- 这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
st:来自于一个虚拟机偷取的CPU时间的百分比
四、iostat
iostat主要用于监控系统设备的io负载情况,sostat首次运行时会显示自系统启动开始的各项统计信息,用户可以通过指定统计的次数和时间来获得所需的统计信息
# iostat 1 1 # iostat -m 1 1 //-m以MB统计数据
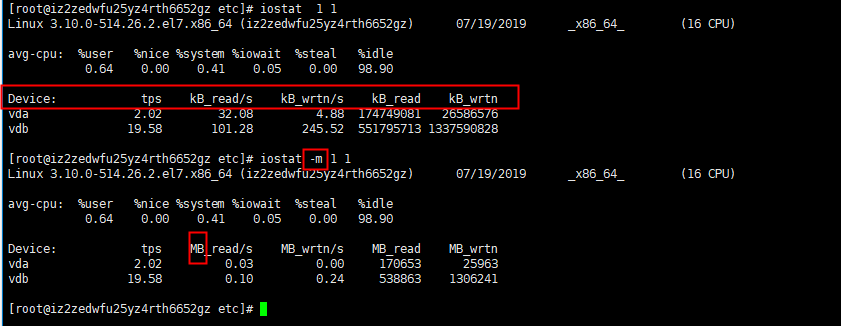
输出信息意义
Device:盘位符
tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。"一次传输"意思是"一次I/O请求"。多个逻辑请求可能会被合并为"一次I/O请求"。"一次传输"请求的大小是未知的。
kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read:读取的总数据量;
kB_wrtn:写入的总数量数据量;这些单位都为Kilobytes。