“我们正在从IT时代走向DT时代(数据时代)。IT和DT之间,不仅仅是技术的变革,更是思想意识的变革,IT主要是为自我服务,用来更好地自我控制和管理,DT则是激活生产力,让别人活得比你好”
——阿里巴巴董事局主席马云
Lambda架构是由Storm的作者南森马兹(Nathan Marz)提出的一个实时大数据处理框架。Marz在Twitter工作期间开发了著名的实时大数据处理框架Storm,Lambda架构是其根据多年进行分布式大数据系统的经验总结提炼而成。Lambda架构的目标是设计出一个能满足实时大数据系统关键特性的架构,包括有:高容错、低延时和可扩展等。Lambda架构整合离线计算和实时计算,融合不可变性(Immunability),读写分离和复杂性隔离等一系列架构原则,可集成Hadoop生态各类大数据组件。
传统系统的问题
数据量从M的级别到G的级别到现在T的级、P的级别。数据量的变化数据管理系统(DBMS)和数仓系统(DW)也在悄然的变化着。 传统应用的数据系统架构设计时,应用直接访问数据库系统。当用户访问量增加时,数据库无法支撑日益增长的用户请求的负载时,从而导致数据库服务器无法及时响应用户请求,出现超时的错误。出现这种情况以后,在系统架构上就采用下图的架构,在数据库和应用中间过一层缓冲隔离,缓解数据库的读写压力。

然而,当用户访问量持续增加时,就需要考虑读写分离技术(Master-Slave)架构则如下图,分库分表技术。现在,架构变得越来越复杂了,增加队列、分区、复制等处理逻辑。应用程序需要了解数据库的schema,才能访问到正确的数据。

商业现实已经发生了变化,所以现在更快做出的决定更有价值。除此之外,技术也在不断发展。Kafka,Storm,Trident,Samza,Spark,Flink,Parquet,Avro,Cloud providers等都是工程师和企业广泛采用的流行语。因此,现代基于Hadoop的M/R管道(使用Kafka,Avro和数据仓库等现代二进制格式,即Amazon Redshift,用于临时查询)可能采用以下方式:

这看起来相当不错,但它仍然是一种传统的批处理方式,具有所有已知的缺点,主要原因是客户端的数据在批处理花费大量时间完成之前的数据处理时,新的数据已经进入而导致数据过时。
Lambda架构简介
对低成本规模化的需求促使人们开始使用分布式文件系统,例如 HDFS和基于批量数据的计算系统(MapReduce 作业)。但是这种系统很难做到低延迟。用 Storm 开发的实时流处理技术可以帮助解决延迟性的问题,但并不完美。其中的一个原因是,Storm 不支持 exactly-once 语义,因此不能保证状态数据的正确性,另外它也不支持基于事件时间的处理。有以上需求的用户不得不在自己的应用程序代码中加入这些功能。后来出现了一种混合分析的方法,它将上述两个方案结合起来,既保证低延迟,又保障正确性。这个方法被称作 Lambda 架构,它通过批量 MapReduce作业提供了虽有些延迟但是结果准确的计算,同时通过Storm将最新数据的计算结果初步展示出来。
exactly-once说明:流处理引擎通常允许用户指定可靠性模式或处理语义,以指示它将为整个应用程序中的数据处理提供哪些保证。这些保证是有意义的,因为你始终会遇到由于网络,机器等可能导致数据丢失的故障。流处理引擎通常为应用程序提供了三种数据处理语义: 最多一次(At-most-once) 至少一次(At-least-once) 精确一次(Exactly-once)
Lambda架构的目标是设计出一个能满足实时大数据系统关键特性的架构,包括有:高容错、低延时和可扩展等。Lambda架构整合离线计算和实时计算,融合不可变性(Immunability),读写分离和复杂性隔离等一系列架构原则,可集成大数据生态各类大数据组件。
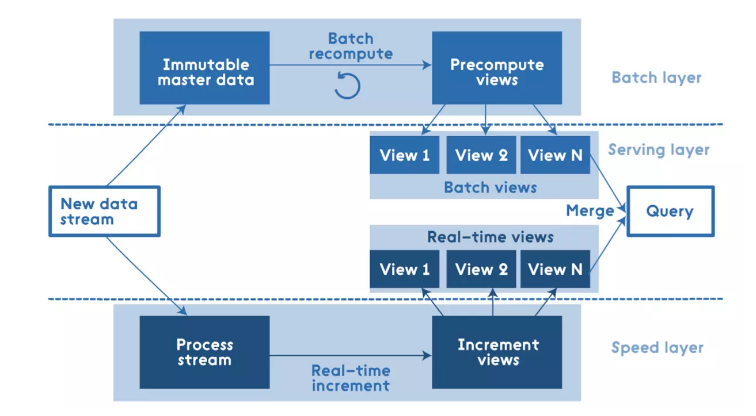
Lambda架构关键特性
Marz认为大数据系统应具有以下的关键特性:
- Robust and fault-tolerant(容错性和鲁棒性):对大规模分布式系统来说,机器是不可靠的,可能会当机,但是系统需要是健壮、行为正确的,即使是遇到机器错误。除了机器错误,人更可能会犯错误。在软件开发中难免会有一些Bug,系统必须对有Bug的程序写入的错误数据有足够的适应能力,所以比机器容错性更加重要的容错性是人为操作容错性。对于大规模的分布式系统来说,人和机器的错误每天都可能会发生,如何应对人和机器的错误,让系统能够从错误中快速恢复尤其重要。
- Low latency reads and updates(低延时):很多应用对于读和写操作的延时要求非常高,要求对更新和查询的响应是低延时的。
- Scalable(横向扩容):当数据量/负载增大时,可扩展性的系统通过增加更多的机器资源来维持性能。也就是常说的系统需要线性可扩展,通常采用scale out(通过增加机器的个数)而不是scale up(通过增强机器的性能)
- General(通用性):系统需要能够适应广泛的应用,包括金融领域、社交网络、电子商务数据分析等。
- Extensible(可扩展):需要增加新功能、新特性时,可扩展的系统能以最小的开发代价来增加新功能。
- Allows ad hoc queries(方便查询):数据中蕴含有价值,需要能够方便、快速的查询出所需要的数据。
- Minimal maintenance(易于维护):系统要想做到易于维护,其关键是控制其复杂性,越是复杂的系统越容易出错、越难维护。
- Debuggable(易调试):当出问题时,系统需要有足够的信息来调试错误,找到问题的根源。其关键是能够追根溯源到每个数据生成点。
数据系统的本质
为了设计出能满足前述的大数据关键特性的系统,我们需要对数据系统有本质性的理解。我们可将数据系统简化为数据 + 查询,从而从数据和查询两方面来认识大数据系统的本质
- 数据系统 = 数据 + 查询
数据的特性: when & what
--- 数据是一个不可分割的单位,数据有两个关键的性质:When和What。
- When 是指数据是与时间相关的,数据一定是在某个时间点产生的。比如Log日志就隐含着按照时间先后顺序产生的数据,Log前面的日志数据一定先于Log后面的日志数据产生;消息系统中消息的接受者一定是在消息的发送者发送消息后接收到的消息。相比于数据库,数据库中表的记录就丢失了时间先后顺序的信息,中间某条记录可能是在最后一条记录产生后发生更新的。对于分布式系统,数据的时间特性尤其重要。分布式系统中数据可能产生于不同的系统中,时间决定了数据发生的全局先后顺序。比如对一个值做算术运算,先+2,后3,与先3,后+2,得到的结果完全不同。数据的时间性质决定了数据的全局发生先后,也就决定了数据的结果。
- What 是指数据的本身。由于数据跟某个时间点相关,所以数据的本身是不可变的(immutable),过往的数据已经成为事实(Fact),你不可能回到过去的某个时间点去改变数据事实。这也就意味着对数据的操作其实只有两种:读取已存在的数据和添加更多的新数据。采用数据库的记法,CRUD就变成了CR,Update和Delete本质上其实是新产生的数据信息,用C来记录。
-
创建(Create)、更新(Update)、读取(Retrieve)和删除(Delete)
数据的存储:Store Everything Rawly and Immutably
--- 根据上述对数据本质特性的分析,Lamba架构中对数据的存储采用的方式是:数据不可变,存储所有数据。 通过采用不可变方式存储所有的数据,可以有如下好处:
- 简单: 采用不可变的数据模型,存储数据时只需要简单的往主数据集后追加数据即可。相比于采用可变的数据模型,为了Update操作,数据通常需要被索引,从而能快速找到要更新的数据去做更新操作。
- 应对人为和机器的错误: 前述中提到人和机器每天都可能会出错,如何应对人和机器的错误,让系统能够从错误中快速恢复极其重要。不可变性(Immutability)和重新计算(Recomputation)则是应对人为和机器错误的常用方法。采用可变数据模型,引发错误的数据有可能被覆盖而丢失。相比于采用不可变的数据模型,因为所有的数据都在,引发错误的数据也在。修复的方法就可以简单的是遍历数据集上存储的所有的数据,丢弃错误的数据,重新计算得到Views。重新计算的关键点在于利用数据的时间特性决定的全局次序,依次顺序重新执行,必然能得到正确的结果。
--- 当前业界有很多采用不可变数据模型来存储所有数据的例子。比如分布式数据库 Datomic,基于不可变数据模型来存储数据,从而简化了设计。分布式消息中间件 Kafka,基于Log日志,以追加append-only的方式来存储消息。
查询的本质
--- 查询是个什么概念?Marz给查询如下一个简单的定义:
- Query = Function(All Data)
该等式的含义是:查询是应用于数据集上的函数。该定义看似简单,却几乎囊括了数据库和数据系统的所有领域:RDBMS、索引、OLAP、OLTP、MapReduce、EFL、分布式文件系统、NoSQL等都可以用这个等式来表示。
让我们进一步深入看一下函数的特性,从而挖掘函数自身的特点来执行查询。 有一类称为Monoid特性的函数应用非常广泛。Monoid的概念来源于范畴学(Category Theory),其一个重要特性是满足结合律。如整数的加法就满足Monoid特性:
- (a+b)+c=a+(b+c)
说明:
Semigroup(半群):集合S和其上的二元运算·:S×S→S。若·满足结合律,即:∀x,y,z∈S,有(x·y)·z=x·(y·z),则称有序对(S,·)为半群,运算·称为该半群的乘法。实际使用中,在上下文明确的情况下,可以简略叙述为“半群S”。例:
1、 对于自然数1、2、3、4、5、...而言,加法运算+可将两个自然数相加,得到的结果仍然是一个自然数,并且加法是满足结合律的:(2 + 3) + 4 = 2 + (3 + 4) = 9。如此一来我们就可以认为自然数和加法运算组成了一个半群。类似的还有自然数与乘法运算等。
Monoid(单位半群):Monoid本身也是一个Semigroup,额外的地方是它多了单位元,所以被称作为单位半群。举例:
1、在上面介绍Semigroup的时候提到,自然数跟加法运算组成了一个半群。显而易见的是,自然数0跟其他任意自然数相加,结果都是等于原来的数:0 + x = x。所以我们可以把0作为单位元,加入到由自然数和加法运算组成的半群中,从而得到了一个单位半群。
2、可以看到,Monoid协议继承自Semigroup,并且用empty静态属性来代表单位元。
不满足Monoid特性的函数很多时候可以转化成多个满足Monoid特性的函数的运算。如多个数的平均值Avg函数,多个平均值没法直接通过结合来得到最终的平均值,但是可以拆成分母除以分子,分母和分子都是整数的加法,从而满足Monoid特性。
Monoid的结合律特性在分布式计算中极其重要,满足Monoid特性意味着我们可以将计算分解到多台机器并行运算,然后再结合各自的部分运算结果得到最终结果。同时也意味着部分运算结果可以储存下来被别的运算共享利用(如果该运算也包含相同的部分子运算),从而减少重复运算的工作量。
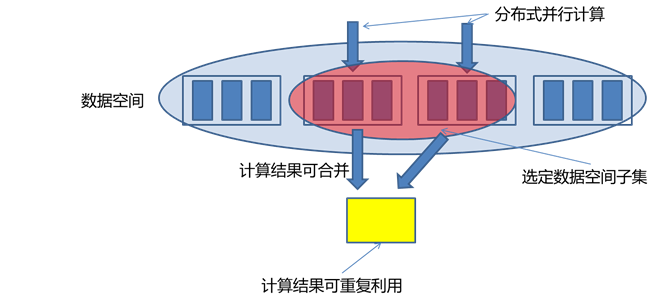
Lambda的三层架构
有了上面对数据系统本质的探讨,下面我们来讨论大数据系统的关键问题:如何实时地在任意大数据集上进行查询?大数据再加上实时计算,问题的难度比较大。
最简单的方法是,根据前述的查询等式Query = Function(All Data),在全体数据集上在线运行查询函数得到结果。但如果数据量比较大,该方法的计算代价太大了,所以不现实。
Lambda架构通过分解的三层架构来解决该问题:Batch Layer,Speed Layer和Serving Layer。

Batch Layer
--- 理想状态下,任何数据访问都可以从表达式 Query= function(all data) 开始,但是,若数据达到相当大的一个级别(例如PB),且还需要支持实时查询时,就需要耗费非常庞大的资源。一个解决方式是预运算查询函数(precomputed query function)。书中将这种预运算查询函数称之为Batch View(A),这样当需要执行查询时,可以从 Batch View 中读取结果。这样一个预先运算好的 View 是可以建立索引的,因而可以支持随机读取(B)。于是系统就变成:
- (A)batch view = function(all data)
- (B)query = function(batch view)
在Lambda架构中,实现(A)batch view = function(all data) 的部分称之为 Batch Layer。Batch Layer的功能主要有两点:
- 存储 master dataset, 这是一个不变的持续增长的数据集
- 在 master dataset 上预先计算查询函数,构建查询所对应的 View
存储数据集
--- 根据前述对数据 When&What 特性的讨论,Batch Layer 采用不可变模型存储所有的数据。因为数据量比较大,可以采用 HDFS 之类的大数据储存方案。如果需要按照数据产生的时间先后顺序存放数据,可以考虑如InfluxDB之类的时间序列数据库(TSDB)存储方案。
构建查询View
--- 上面说到根据等式 Query = Function(All Data),在全体数据集上在线运行查询函数得到结果的代价太大。但如果我们预先在数据集上计算并保存查询函数的结果,查询的时候就可以直接返回结果(或通过简单的加工运算就可得到结果)而无需重新进行完整费时的计算了。这儿可以把 Batch Layer看成是一个数据预处理的过程。我们把针对查询预先计算并保存的结果称为View,View是Lambda架构的一个核心概念,它是针对查询的优化,通过View即可以快速得到查询结果。

--- 显然,batch view是一个批处理过程,如采用Hadoop或spark支持的map-reduce方式。采用这种方式计算得到的每个view都支持再次计算,且每次计算的结果都相同。该工作看似简单,实质非常强大。任何人为或机器发生的错误,都可以通过修正错误后重新计算来恢复得到正确结果。
对View的理解
--- View是一个和业务关联性比较大的概念,View的创建需要从业务自身的需求出发。一个通用的数据库查询系统,查询对应的函数千变万化,不可能穷举。但是如果从业务自身的需求出发,可以发现业务所需要的查询常常是有限的。Batch Layer需要做的一件重要的工作就是根据业务的需求,考察可能需要的各种查询,根据查询定义其在数据集上对应的Views。
如下图 agent id=50023 的人,在10:00:06分的时候,状态是calling,在10:00:10的时候状态为waiting。在传统的数据库设计中,直接后面的纪录覆盖前面的纪录,而在Immutable数据模型中,不会对原有数据进行更改,而是采用插入修改纪录的形式更改历史纪录。
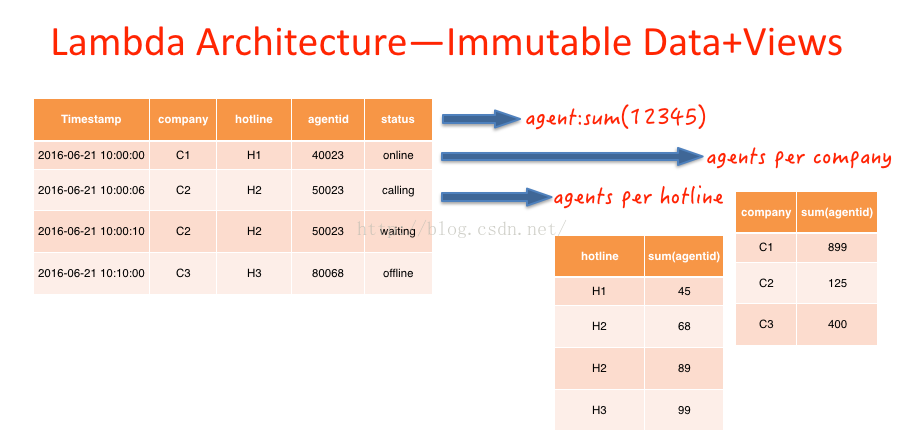
上文所提及的View是上图中预先计算得到的相关视图,例如:2016-06-21当天所有上线的agent数,每条热线、公司下上线的Agent数。根据业务需要,预先计算出结果。此过程相当于传统数仓建模的应用层,应用层也是根据业务场景,预先加工出的view。
Speed Layer
Batch Layer可以很好的处理离线数据,但有很多场景数据不断实时生成,并且需要实时查询处理。Speed Layer正是用来处理增量的实时数据。Speed Layer和Batch Layer比较类似,对数据进行计算并生成Realtime View,其主要区别在于:
- Speed Layer 处理的数据是最近的增量数据流,Batch Layer处理的全体数据集
- Speed Layer 为了效率,接收到新数据时不断更新Realtime View,而Batch Layer根据全体离线数据集直接得到Batch View。
- Speed Layer 是一种增量计算,而非重新计算(recomputation)
- Speed Layer 因为采用增量计算,所以延迟小,而Batch Layer是全数据集的计算,耗时比较长
综上所诉,Speed Layer是 Batch Layer在实时性上的一个补充。Speed Layer可总结为:
- (C)realtime view=function(realtime view,new data)
注意,realtime view 是基于新数据和已有的realtime view。
Lambda架构将数据处理分解为Batch Layer和Speed Layer有如下优点:
- 容错性:Speed Layer中处理的数据也不断写入Batch Layer,当Batch Layer中重新计算的数据集包含Speed Layer处理的数据集后,当前的Realtime View就可以丢弃,这也就意味着Speed Layer处理中引入的错误,在Batch Layer重新计算时都可以得到修正。这点也可以看成是CAP理论中的最终一致性(Eventual Consistency)的体现。
- 复杂性隔离:Batch Layer处理的是离线数据,可以很好的掌控。Speed Layer采用增量算法处理实时数据,复杂性比Batch Layer要高很多。通过分开Batch Layer和Speed Layer,把复杂性隔离到Speed Layer,可以很好的提高整个系统的鲁棒性和可靠性。

如前所述,任何传入查询都必须通过合并来自批量视图和实时视图的结果来得到答案,因此这些视图需要满足Monoid的结合律特性。需要注意的一点是,实时视图是以前的实时视图和新数据增量的函数,因此可以使用增量算法。批处理视图是所有数据的函数,因此应该在那里使用重算算法。
Serving Layer
Lambda架构的Serving Layer用于响应用户的查询请求,合并Batch View和Realtime View中的结果数据集到最终的数据集。
这儿涉及到数据如何合并的问题。前面我们讨论了查询函数的Monoid性质,如果查询函数满足Monoid性质,即满足结合律,只需要简单的合并Batch View和Realtime View中的结果数据集即可。否则的话,可以把查询函数转换成多个满足Monoid性质的查询函数的运算,单独对每个满足Monoid性质的查询函数进行Batch View和Realtime View中的结果数据集合并,然后再计算得到最终的结果数据集。另外也可以根据业务自身的特性,运用业务自身的规则来对Batch View和Realtime View中的结果数据集合并。

综上所诉,Serving Layer采用如下等式表示:
- (D)query=function(batch view, realtime view)
Lambda架构组件选型
上面分别讨论了Lambda架构的三层:Batch Layer,Speed Layer和Serving Layer。总结下来,Lambda架构就是如下的三个等式:
- batch view = function(all data)
- realtime view = function(realtime view, new data)
- query = function(batch view, realtime view)
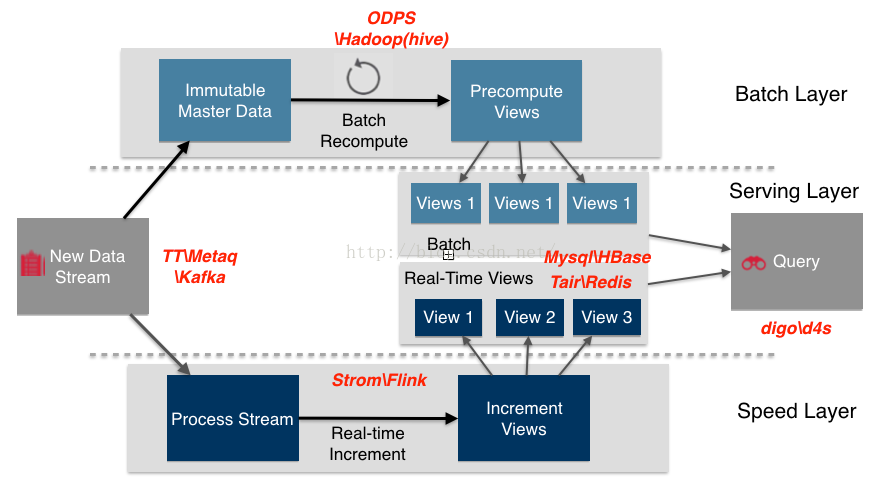
下图给出了Lambda架构的一个完整视图和流程。
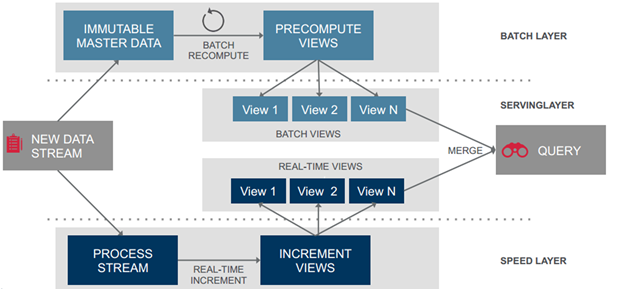
数据流进入系统后,同时发往Batch Layer和Speed Layer处理。其中:
- Batch Layer 以不可变模型离线存储所有数据集,通过在全体数据集上不断重新计算构建查询所对应的 Batch Views。
- Speed Layer 处理增量的实时数据流,不断更新查询所对应的 Realtime Views。
- Serving Layer 响应用户的查询请求,合并Batch View和Realtime View中的结果数据集到最终的数据集。
组件选型
--- 下图给出了Lambda架构中各组件在大数据生态系统中和阿里集团的常用组件。
- 数据流存储选用不可变日志的分布式系统 Kafka、TT、Metaq;
- BatchLayer 数据集的存储选用 Hadoop 的 HDFS 或者阿里云的ODPS;
- BatchVie w的加工采用MapReduce;
- BatchView 数据的存储采用Mysql(查询少量的最近结果数据)、Hbase(查询大量的历史结果数据)。
- SpeedLayer采用增量数据处理Storm、Flink;
- RealtimeVie w增量结果数据集采用内存数据库Redis。
另一个实现版本:

示例三:

根据batch layer的特点,具备存储(HDFS)和计算(MapReduce)的Hadoop显然是第一人选,而batch view 可以是hadoop本身的hdfs 或者基于hdfs的所构建的类似hive那样的仓库,speed layer因为时效性的影响,采用实时流式处理系统,例如strom或者spark streaming, 而speed view 可以存在HBase 或者其他类似的Nosql数据库。server layer 提供用户查询的方法,采用facebook 开源的Impala,统一入口查询。这是比较老的文章,主要用来理解Lambda架构原理,随着大数据新的框架和组件的出现,可替代的组件多得去了,如下一小节根据实际场景来做组件选型就好。
选型原则
Lambda架构是个通用框架,各个层选型时不要局限时上面给出的组件,特别是对于View的选型。从我对Lambda架构的实践来看,因为View是个和业务关联性非常大的概念,View选择组件时关键是要根据业务的需求,来选择最适合查询的组件。不同的View组件的选择要深入挖掘数据和计算自身的特点,从而选择出最适合数据和计算自身特点的组件,同时不同的View可以选择不同的组件。
总结
在过去Lambda数据架构成为每一个公司大数据平台必备的架构,它解决了一个公司大数据批量离线处理和实时数据处理的需求。一个典型的Lambda架构如下:

数据从底层的数据源开始,经过各种各样的格式进入大数据平台,在大数据平台中经过 Kafka、Flume 等数据组件进行收集,然后分成两条线进行计算。一条线是进入流式计算平台(例如 Storm、Flink或者Spark Streaming),去计算实时的一些指标;另一条线进入批量数据处理离线计算平台(例如Mapreduce、Hive,Spark SQL),去计算T+1的相关业务指标,这些指标需要隔日才能看见。
Lambda架构经历多年的发展,其优点是稳定,对于实时计算部分的计算成本可控,批量处理可以用晚上的时间来整体批量计算,这样把实时计算和离线计算高峰分开,这种架构支撑了数据行业的早期发展,但是它也有一些致命缺点,并在大数据3.0时代越来越不适应数据分析业务的需求。缺点如下:
- 实时与批量计算结果不一致引起的数据口径问题:因为批量和实时计算走的是两个计算框架和计算程序,算出的结果往往不同,经常看到一个数字当天看是一个数据,第二天看昨天的数据反而发生了变化。
- 批量计算在计算窗口内无法完成:在IOT时代,数据量级越来越大,经常发现夜间只有4、5个小时的时间窗口,已经无法完成白天20多个小时累计的数据,保证早上上班前准时出数据已成为每个大数据团队头疼的问题。
- 开发和维护的复杂性问题:Lambda 架构需要在两个不同的 API(application programming interface,应用程序编程接口)中对同样的业务逻辑进行两次编程:一次为批量计算的ETL系统,一次为流式计算的Streaming系统。针对同一个业务问题产生了两个代码库,各有不同的漏洞。这种系统实际上非常难维护
- 服务器存储大:数据仓库的典型设计,会产生大量的中间结果表,造成数据急速膨胀,加大服务器存储压力。
也就是由于Lambda架构的以上局限性,Kappa应运而生,它比Lambda架构更加灵活和精简。
原文参考: