- 本文总结了 Real-Time Rendering (第四版) 中第二十三章的内容
- 本文链接标明了之前提过的概念或该概念的讲解
这里仅总结在书中自己认为或者不懂的要点并结合实际工作学习所需,若内容讲解不详细还请谅解
尽管现代图形硬件发展迅猛,每家都有自己的独到之处,但其中仍然由于很多共通的设计和架构概念值得图形开发者学习。
本文介绍了图形硬件的基本原理:包括光栅化的基本过程,GPU 如何分配资源和安排任务:包括处理延迟(latency)和占用量(occupancy)。以及 GPU 的基本架构。
其中,“光栅化” 到 “纹理贴图”介绍了 GPU 中的主要功能和架构概念,“GPU 架构”章节开始介绍 GPU 的基本设计架构。
-
光栅化(Rasterization)
根据本书第二章讲解的内容,光栅化是生成像素的阶段,它涉及判断像素点是否在三角形图元内,根据顶点信息插值生成新的像素。
在进行光栅化之前,GPU 会进行裁剪(clipping)和三角形设置(triangle setup)。首先先对不在视口(view port / visible screen)内的顶点或图元进行剔除(culling),因为它们不在视口内没必要渲染它们。对于部分在视口内的图元则需要进行裁剪(clipping),裁剪会生成新的顶点并保证在视口内的部分图元仍可以被渲染,其中 guard-band 算法为效率很高的一种裁剪算法,示例如图 1。三角形设置则是在进行三角形遍历之前计算像素插值的相关参数以提升渲染效率。
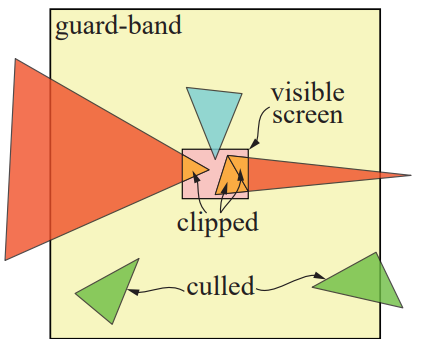
图 1:Gurad Band 裁剪算法:红色三角形被裁减,绿色三角形被剔除
判断一个像素是否在一个三角形中需要判断该像素位置与三角形三边的关系,如今大部分 GPU 光栅器的判断方法是基于 Juan Pineda 于 1998 年发表的论文《A Parallel Algorithm for Polygon Rasterization》[2]。现代光栅化判断点位置是否在三角形内的方法是根据计算三角形每个边的 edge function 来判断像素点(x, y)是否在该三角形内。 当一个点位置(x, y)满足三角形每条边的 edge function e(x, y) >= 0 时,该点在三角形内(注:当 e(x, y) = 0 时,该点在三角形边上)。图解如下 [2]:
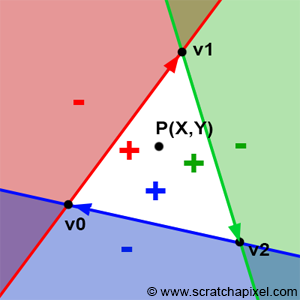
图 2:如图,在三角形内的顶点满足该点位置在三条边(向量)的“右侧”
当光栅器标记完在三角形内的像素后,连同被标记的像素所在同一 quad 而不在三角形内的像素被称为助手像素(helper pixel)。这些像素将在后面的计算中起到帮助作用。举例如下图:
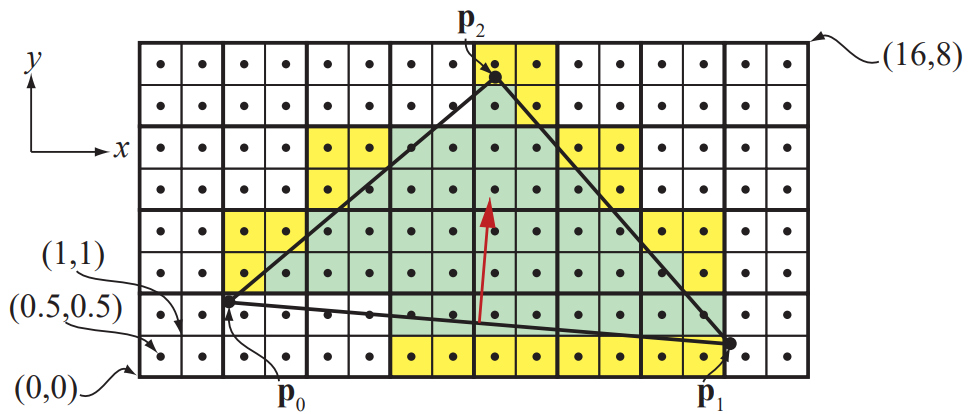
图 3:绿色是被包含在三角形内的像素,黄色是在三角形外的助手像素
光栅器的另一个重要功能是遍历三角形,然而三角形遍历的方式是可变的:有可能是沿整个三角形内的像素走之字形,也有可能是按区域搜索等。但无论哪种方法进行遍历,遍历的顺序都会尽可能倾向于增加像素间的趋同性(coherency)以减小计算成本。其中比较高效率的方式是按照扫描线(scanline)的顺序遍历像素,遍历过后的像素被存在缓冲之中并可以随时被快速调用而不需要重复读取,这一点对于提取贴图,深度测试和颜色缓存效率大大提升。
-
插值(Interpolation)
对于正交投影,GPU 会使用重心坐标(barycentric coordinate)对像素进行线性插值。由于三角形的面积不变,所以每个点的重心坐标是不变的,所以无需考虑像素的深度值进行插值计算。也因为避免了对像素深度的考虑,所以避免了除法(除法是效率较低的计算),因此效率较高。但正交投影的结果在人眼看起来并不自然,因为它并不符合人眼看物体近大远小的规律,举例如下图 [3]:
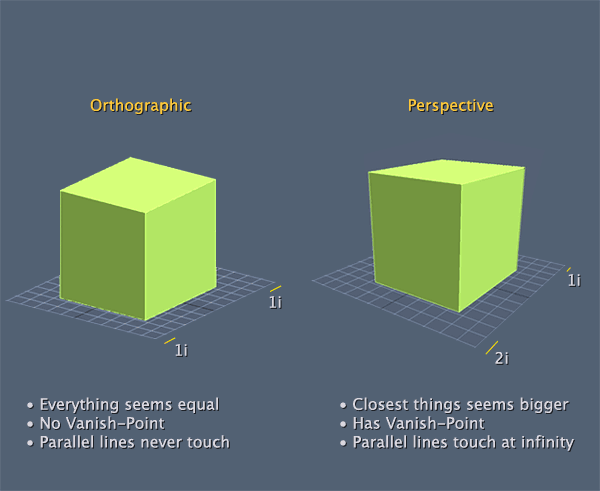
图 4:正交投影(左)与透视投影(右)
对于透视投影,GPU 需要基于像素深度的倒数进行线性插值,这叫做透视校正插值(perspective-correct interpolation)。透视校正插值要求 GPU 计算每一个像素的深度值,然后基于该深度值对像素信息进行插值计算以得到每一个像素的正确信息。
-
保守光栅(CR,Conservative Rasterization)
在DX 11 与 OpenGL 的扩展中有一种新的三角形遍历方式叫做保守光栅。它是基于像素与三角形的重叠程度定义不同层级的像素。如下图例子所示:黄色的像素被视为高估 CR(overestimated CR,OCR)因为像素并没有完全被三角形覆盖,绿色像素则被视为低估 CR(underestimate CR,UCR)因为其被完全覆盖。基于 CR,GPU 可以选择在可以降低渲染效果的情况下选择性的渲染部分像素,比如在物体 LOD 较低时只渲染 UCR 部分。
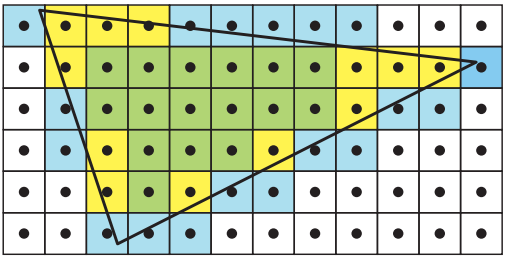
图 5:OCR (黄色)与 UCR(绿色)
-
大规模计算与线程调度(Massive Compute and Schedule)
为了支持大规模的随机读写计算,现代 GPU 设计了支持 SIMD 的多线程运算规划,也叫做 SIMT(single instruction multi threads)处理。为此 GPU 内部设计有多重处理器(multiprocessor,MP),它是由多个 GPU 逻辑计算单元(ALU)组成,每一个 ALU 在 MP 中对不同的数据同步执行相同指令。一个 MP 在这时便是一个 SIMD 引擎,其中每一个 ALU 的执行结果都是相互独立的,所以可以同时运行计算。在 所有 MP 之上,GPU 还会有一个更高层级的线程调度器进行管理,管理各个 MP 的任务。一般来说,GPU 会尽可能复制相同任务给每个 MP 以在芯片上获得较高的计算密度,这同样是为了降低延迟和实现高吞吐量以保证运行效率。
一个 ALU 是 GPU 多重处理器的基本运算单元,与 CPU 的 ALU 能处理更多复杂情况不同,GPU 中 一个 ALU 可以处理单个顶点或者片元计算,其中 ALU 会进行浮点数,整数与三角函数运算,也可以进行存储,移动,数值,也可以进行分流(例如 if)。一个典型的 ALU 结构一般由几个硬件单元组成,其中最重要的是两个计算单元为浮点数单元(floating point unit)和整数单元(int unit),两个单元分别对浮点数和整数进行加和乘运算。下图讲解了一个典型的 ALU 处理一个数据的流程:
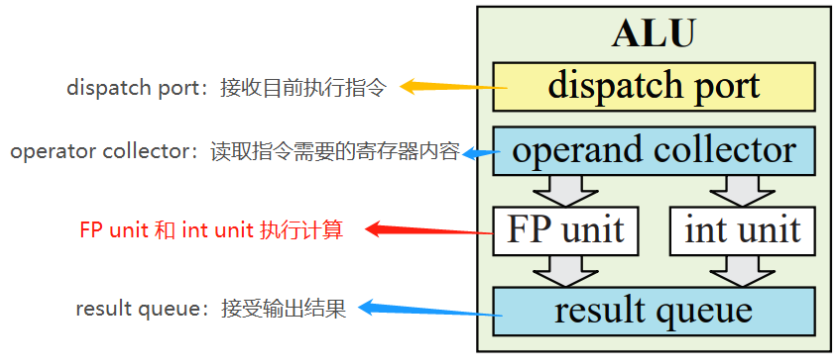
图 6:ALU 单次执行流程
GPU 多重处理器构建于 GPU ALU 之上,其运行方式是让所有在处理器中的 ALU 同时执行对不同数据只想相同操作指令以实现大吞吐量和 wrap 之间切换自如。基于这养的思路,一个 MP 中会有一个线程调度器(scheduler)很多个 ALU 可以同时按照上面(图 6)的逻辑流程运行。除了 ALU,一个 MP 中还包含,一级缓存(L1 cache),本地数据单元(local data storage,LDS),纹理单元(texture unit)和特别单元(special unit)组成。一个 MP 的结构与各单位功能大致如下:
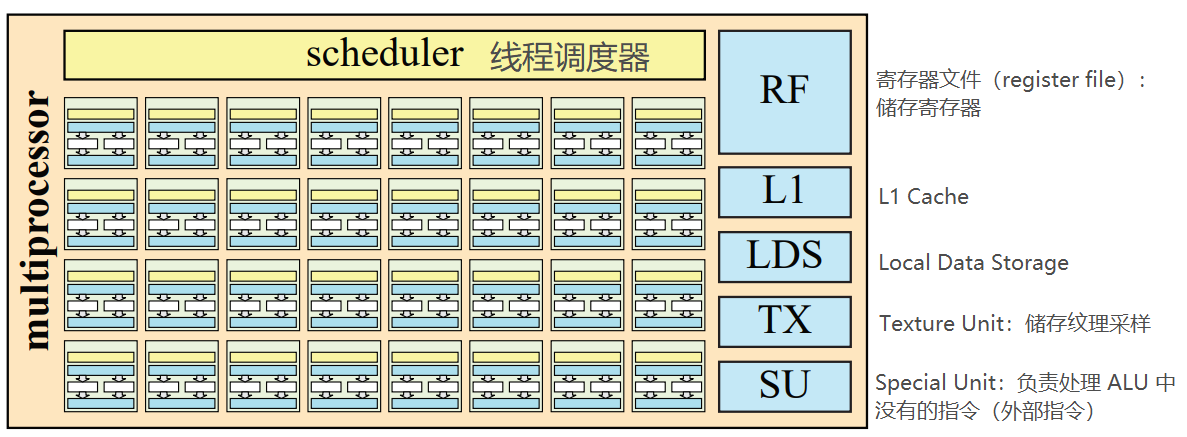
图 7:MP 示例,其中有 8 * 4 = 32 个 ALU
MP 中的线程调度器(scheduler)将不同的 wrap 中的任务分配给不同的 ALU 进行处理,将寄存器中的寄存器数据分配给不同 wrap 中的线程,并保证工作顺序最优化。其中,不同工作的优先级遵循着一定的规则:一般来说,在渲染管线下游的工作比在上游的工作有更高的优先级。举个例子,因为像素着色(简称 PS)阶段在渲染管线较为靠后的位置,所以其优先级是高过顶点着色(简称 VS)阶段的。这样的规则避免了渲染阶段间的等待(stalling),因为后期阶段不太可能需要前期阶段的数据,所以给予他们更高的优先级。所以当有一组 VS 处理和一组 PS 处理同时进入 MP 时,MP 的线程调度器会优先处理 PS 任务。MP 也会将需要等待的任务切换到可以立即执行的任务以减少延迟(在这篇博客内图 2 有举例描述)。
-
延迟与占用率(Latency and Occupancy)
首先,解释开头的两个概念:
-
- 延迟(latency):是指提出需求到收到结果之间的时间。比如一个操作需要某个参数的地址,那么从提取地址这个操作开始到返回这个参数的地址回来的时间既是延迟。
- 占用率(occuoancy):一个 MP 中实际运行的 wrap 与 该 MP 中最大 wrap 可运行量的比。公式为:
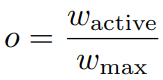 。占用率衡量了计算资源的使用率。
。占用率衡量了计算资源的使用率。
首先,如果延迟没有被有效的隐藏起来,内存读取的损耗将降低 GPU 的执行速度,这种情况也可能发生在 CPU 与 GPU 之间进行数据交换。从架构层面来说,将 CPU 和 GPU 的底层内存共享可以解决之前提到的延迟问题,这种解决方法被用在了 Intel Gen9 图像架构上。同样的方法也可以提高光线追踪的执行效率,因为光线信息是在图像处理器与 CPU 之间进行数据传输。
对于占用率来说,一般情况下,占用率越高代表效率越高,但也有例外:比如 shader 使用了太多的寄存器的情况,或者连续在相同的 wrap 执行不进行内存读写的操作,这同样也会占用寄存器资源从而导致效率低下。所以不论是 shader 程序和 GPU 架构设计都需要考虑占用率和整体效率的平衡。
-
内存架构与总线(Memory Architecture and Buses)
在开始讲解内存架构与总线之前,我们要先了解一些术语和概念,以下概念会在后面用到:
-
- 端口(port):连接两个设备并传输数据。
- 总线(bus):连接多个设备并传输数据。
- 带宽(bandwidth):衡量端口或总线等传输的吞吐量,单位是字节 / 秒(B/s)。
大部分 GPU 都有一个单独的内存空间用来加速图像处理,这部分空间便是显存(video memory)。GPU 通过显存的读取效率是远高于经过总线从系统内存中的读取效率。传统意义上,显存只用来存储纹理信息和渲染目标信息,但也可以储存其他信息,比如人物模型。
使用显存的读写优势,一个游戏中模型变化不大的部分(比如人物,一般来说只有关节会有顶点变化)可以存储在显存中的静态顶点缓冲(static vertex buffer)和其索引缓冲中,这样避免了使用总线与系统内存进行读写交流。但对于模型变化频繁,需要从 CPU 接受变化数据的模型来说,则仍需要通过 GPU 与 CPU 之间的总线进行交流。
对于大部分游戏主机来说,它们使用了统一内存架构(unified memory architecture, UMA)。这种架构使得图形硬件可以直接读写主机上的任何内容。CPU 和图形硬件使用一块内存,总线也一样。但和上文提到的 Intel Gen9 一样,并非所有缓存都被共享,图形硬件也有自己的多级缓存,其中最后一级缓存是第一个被共享的缓存。对于所有的计算机和图形架构来说,拥有多级缓存时很重要的,这样降低了内存读写的平均时间。
-
缓存与压缩(Caching and Compression)
给予 GPU 多重缓存层级的目的是为了减小读写存储的延迟和增加本地读写的能力以增大整体带宽。但对于一些过大的数据,GPU 需要自行压缩或解压文件以保证数据能被快速传输且图像能被正确渲染。为了保证效率,大多数 GPU 都包括了可以压缩,解压的硬件和对应的算法以及系统。大多数的 GPU 硬件都具有这样的系统(比如后面提到的的深度测试硬件),但压缩解压步骤的位置却不一样,大概分为以下两种:
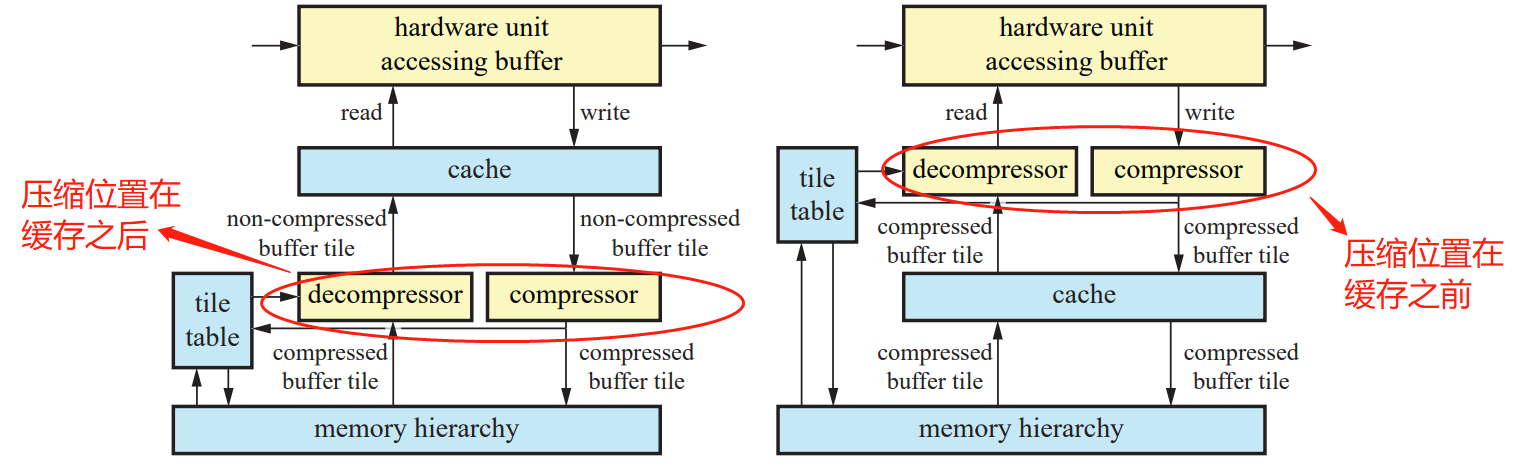
图 8:两种 GPU 压缩解压系统(在缓存前的结构效率更高但结构更复杂)
不论是哪种系统都有 tile table 这个组成部分,因为不论是像素深度,颜色,模板(stencil)在 GPU 里面的读写存储都可以以 tile table 的形式存储(想像一个图片每个像素上下左右的排列,每一个像素可以被视为是一个 tile),所以在这里使用 tile table 帮助压缩存储。GPU 对于每一种类型的信息都有相应的压缩方法,且可以有不同的压缩程度。
在该系统中,tile table 在 GPU 的压缩与解压算法中起了至关重要的作用,它包含了每一个 tile 的附加信息,这些附加信息可以在之后的压缩解压中有帮助。tile table 也可以帮助 GPU 快速清空帧缓存。
-
颜色缓冲(Color Buffering)
GPU 在渲染时针对不同的数据类型会用到多种不同的缓冲,比如颜色, 深度,模板等。其中颜色缓冲包括几种可以储存的颜色模式:高彩色(high color,15-16 bits),真彩色(true color,24 bits)和深彩色(deep color,30-48 bits),每一种储存方式的储存大小由前往后越来越大。其中真彩色的使用率最普遍。其中,显示控制器(video display controller, VDC)直接使用颜色缓冲并绘制到屏幕上。VDC 也叫显示引擎,是 GPU 中的一块硬件区域,直接将颜色缓冲中的内容显示在屏幕上。如今的 VDC 可以根据屏幕属性的不同进行对输出颜色缓冲中的内容进行调节。
GPU 内的渲染缓冲(不仅是颜色缓冲)一般都是双缓冲架构。相比单缓冲来说,双缓冲避免了画面撕裂并实现了更流畅地渲染(具体见本文最后的部分讲解)。在这里讲解一下三重缓冲(triple buffering):三重缓冲可以被视为双缓冲的扩张版,它加入了新的悬挂缓冲(pending buffer)。在每一帧渲染时,悬挂缓冲可以被读写,而不像双缓冲时的后缓冲必须存储一个渲染完毕的图像,这给了开发者更大的灵活性。但也因为帧有三重缓冲,渲染延迟会增加。在悬挂缓冲读写完成后,该缓冲会变为后缓冲(被后缓冲指针指向),然后变成前缓冲将内容显示到屏幕上。三种缓冲的结构如下:

图 9:三种缓冲模式
-
深度裁剪,测试以及缓存(Depth Culling, Testing, and Buffering)
在现代 GPU 中,深度测试被 GPU 的硬件单元执行,也有应运而生的多种裁剪算法,比如 zmax 裁剪,zmin 裁剪,early-z 测试(具体过程略),这些算法都可以直接应用在 GPU 硬件上实现。但若程序提供的 pixel shader 在深度上做了一定操作,以上的深度裁剪和测试也有可能会被停止使用。深度测试的硬件中也有压缩解压系统用于处理深度信息的传输,其结构同上文中的 GPU 缓存压缩结构相似。
-
纹理贴图(Texturing)
对于贴图的一系列操作,包括纹理寻址(texture addressing),纹理滤波(texture filtering)以及纹理压缩(texture mapping)等,都是由 GPU 中的纹理单元(texture unit)进行处理。相比使用软件层面处理纹理,使用 GPU 硬件可以将相同操作提升 40 倍性能。
在 GPU 中也有专门为纹理留下缓存空间,有些 GPU 架构会为纹理留下一级或多级缓存硬件,有些则会让纹理数据与其他硬件共享缓存;一般来说,一个小型的芯片存储器就可以满足缓存纹理的目的。纹理缓存储存最近一次读取的纹理并且可以快速读写。如何存储纹理则取决与 GPU 的内部实现,但同样的,其内部结构也与上文中的 GPU 缓存压缩结构相似。
-
GPU 架构(Architecture)
为了实现图像的快速渲染,实现并行计算是效率最高的方式,这样的方式被运用在现代 GPU 中。基于这个架构,如果想要优化 GPU 效率,可以在流程效率上或者并行性上进行改造。一条渲染流程/管线经过几何单元 -> 光栅单元 -> 像素处理单元这三段硬件处理,一条流程的效率影响取决于其中的硬件和软件(执行代码)的效率。一般来说,增加并行性可以提高 GPU 的处理速度。GPU 的并行运算架构整体如下:
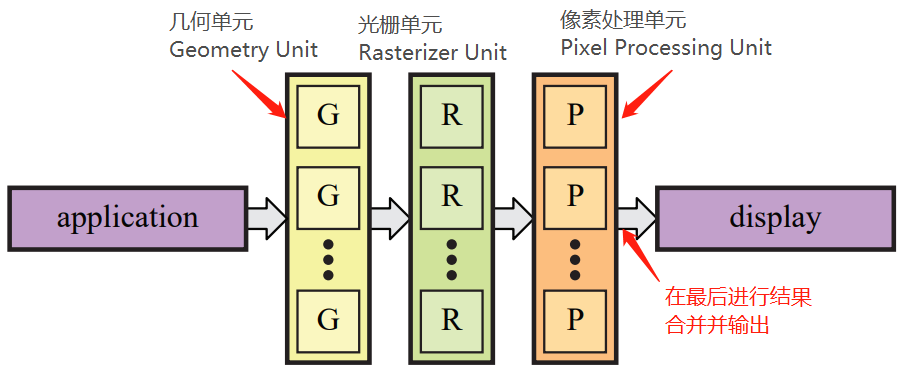
图 10:GPU 基本架构
尽管 GPU 的架构是并行计算,但当数据在 GPU 内处理时还是需要基于 CPU 传递数据的顺序的,所以需要对数据处理进行排序以保证渲染出用户需要的画面效果。主流的渲染排序方式有四种:sort-first,sort-middle,sort-last fragment 和 sort-last image,其中最后两种排序结构相似。它们之间的不同取决于在哪个阶段对输入数据或被处理过的数据进行排序以保证正确的输出结果,大致流程图如下:
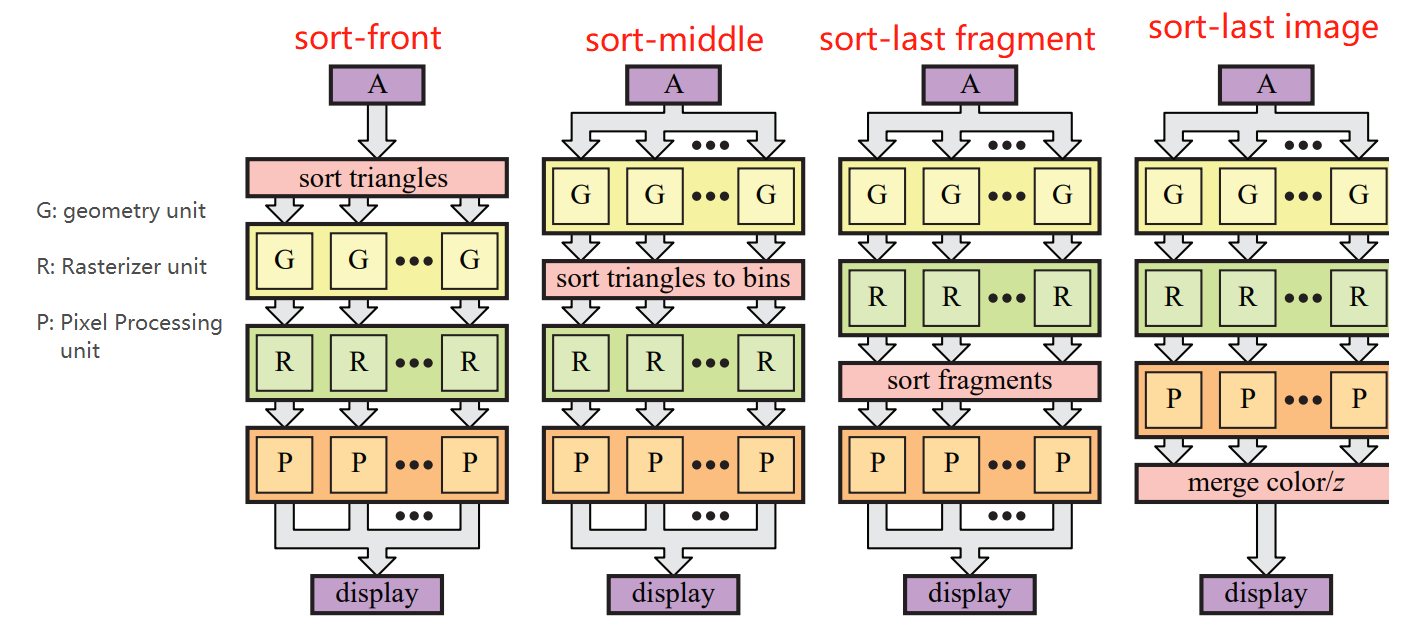
图 11:GPU 数据排序架构
简单介绍一下几种排序方式的不同,每种方式都有优势和劣势。其中 sort-first 和 sort-last 方式多用来实现高性能渲染:
-
- sort-front:这是在 GPU 进入几何处理阶段进行的排序:方法是将屏幕分成多块区域,在某块区域的图元会被分配到负责处理这块区域的管线。
- sort-middle:首先,每个几何处理单元会被分配接近相同数量的几何数据处理,处理完后的几何则是被几何坐标变换后的几何数据。这些几何数据会被排序进 tiles,这些 tiles 是一个个组成整个屏幕且互不重叠的方块。这些 tile 内的数据会被传递给光栅单元和像素处理单元的共用的,tile 大小的缓冲中,光栅单元和像素处理单元可以对这些数据进行极快的读写从而提升了效率。
- sort-last fragment:在光栅化后对片元进行排序,然后将排序完的片元传递到像素处理单元内。这样做的优势是每一个片元在排序后只会被传递到一个像素处理单元内,因为片元之间没有重叠,但也有可能造成处理排序数据量不平均:比如某个光栅器处理很多很大的三角形,有些则处理很少的小三角形,那么传递出来的需要排序的图元也不一样。
- sort-last image:在像素处理单元处理完片元后进行的排序,可以理解为每个相互独立的渲染管线渲染了一个物体。然后在合并阶段,每一个被渲染的结果会被比较深度值,然后进行渲染。值得注意的是,sort-last image 系统不能完全实现所有的图形 API(比如 OpenGL 和 DirectX),因为这些 API 要求图元的渲染顺序与他们的传入顺序相同。另一个问题是对于较大的渲染目标,图像本体和深度值的传输是比较费时的。
在了解了 GPU 的基本架构之后,我们可以学习一些现有的 GPU 架构,比如英伟达的 Pascal 架构(应用于 GeForce GTX1050 - 1080ti 等)以及 AMD 的锐龙 Vega 系列(书中的 Case study 跳过,有兴趣的朋友可以自行谷歌了解一下)。
-
附加:光追架构(Ray Tracing Architectures)
光线追踪(ray tracing)作为一种加强渲染真实感的技术,在渲染硬件算力不强的时代是用来做离线渲染而非实时渲染。随着显示硬件的进步,光追在实时渲染中的运用越来越普遍。一般来说,光追的计算大部份依赖硬件上的实现,并且这在一定程度上简化了硬件上的复杂程度(因为光追相比光栅化渲染是一种相对比较简单粗暴的渲染技术,详细请见这篇文章)。
参考资料:
[1] Real-Time Rendering fourth Edition (大部分内容以及图片来自于此书)
[2] Scratchapixel 2.0 --- Rasterization: a Practical Implementation
[3] LegactOpenGL --- Projections
[4] 洛城 --- 一篇光线追踪的入门