布隆过滤器相关知识点,网上好多大神解释的还是比较详细的,本文根据网上各种资料进行大致总结,详细资料可参考一下两篇文章
https://www.jianshu.com/p/2104d11ee0a2
https://cloud.tencent.com/developer/article/1136056
-
Bloom Filter
概念
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询。可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
HashMap的缺点
讲述布隆过滤器的原理之前,我们先思考一下,通常你判断某个元素是否存在用的是什么?应该蛮多人回答 HashMap 吧,确实可以将值映射到 HashMap 的 Key,然后可以在 O(1) 的时间复杂度内返回结果,效率奇高。但是 HashMap 的实现也有缺点,例如存储容量占比高,考虑到负载因子的存在,通常空间是不能被用满的,而一旦你的值很多例如上亿的时候,那 HashMap 占据的内存大小就变得很可观了。
还比如说你的数据集存储在远程服务器上,本地服务接受输入,而数据集非常大不可能一次性读进内存构建 HashMap 的时候,也会存在问题。
布隆过滤器的数据结构:
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样:
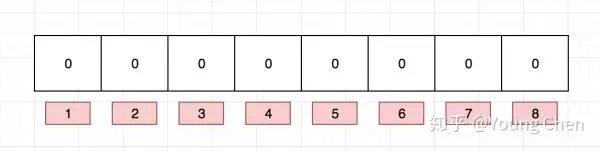

再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:
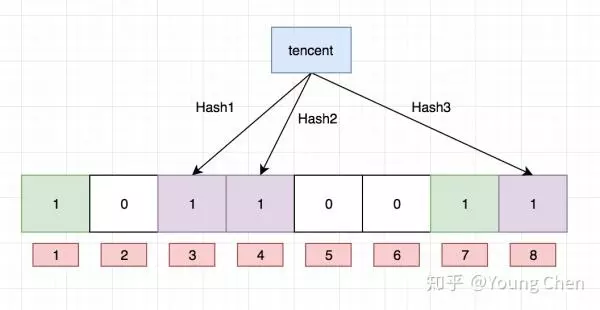
值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
这是为什么呢?答案跟简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
布隆过滤器的选择及哈希函数个数的选择
很显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。

k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率。
最佳实践
常见的适用常见有,利用布隆过滤器减少磁盘 IO 或者网络请求,因为一旦一个值必定不存在的话,我们可以不用进行后续昂贵的查询请求。
另外,既然你使用布隆过滤器来加速查找和判断是否存在,那么性能很低的哈希函数不是个好选择,推荐 MurmurHash、Fnv 这些。
大value拆分
Redis 因其支持 setbit 和 getbit 操作,且纯内存性能高等特点,因此天然就可以作为布隆过滤器来使用。但是布隆过滤器的不当使用极易产生大 Value,增加 Redis 阻塞风险,因此生成环境中建议对体积庞大的布隆过滤器进行拆分。
拆分的形式方法多种多样,但是本质是不要将 Hash(Key) 之后的请求分散在多个节点的多个小 bitmap 上,而是应该拆分成多个小 bitmap 之后,对一个 Key 的所有哈希函数都落在这一个小 bitmap 上。
-
Counting Bloom Filter
标准的 Bloom Filter 是一种比较简单的数据结构,只支持插入和查找两种操作。在所要表达的集合是静态集合的时候,标准 Bloom Filter 可以很好地工作,但是如果要表达的集合经常变动,标准Bloom Filter的弊端就显现出来了,因为它不支持删除操作。这就引出来了本文要谈的 Counting Bloom Filter,后文简写为 CBF。
原理
布隆过滤器不能删除元素
比如要删除集合中的成员 dantezhao,那么就会先用 k 个哈希函数对其计算,因为 dantezhao 已经是集合成员,那么在位数组的对应位置一定是 1,我们如要要删除这个成员 dantezhao,就需要把计算出来的所有位置上的 1 置为 0,即将 5 和 16 两位置为 0 即可。

问题来了!现在,先假设 yyj 本身是属于集合的元素,如果需要查询 yyj 是否在集合中,通过哈希函数计算后,我们会去判断第 16 和 第 26 位是否为 1, 这时候就得到了第 16 位为 0 的结果,即 yyj 不属于集合。 显然这里是误判的。
Counting Bloom Filter 的出现,解决了上述问题,它将标准 Bloom Filter 位数组的每一位扩展为一个小的计数器(Counter),在插入元素时给对应的 k (k 为哈希函数个数)个 Counter 的值分别加 1,删除元素时给对应的 k 个 Counter 的值分别减 1。Counting Bloom Filter 通过多占用几倍的存储空间的代价, 给 Bloom Filter 增加了删除操作。基本原理是不是很简单?看下图就能明白它和 Bloom Filter 的区别在哪。

CBF 和 BF 的一个主要的不同就是 CBF 用一个 Counter 取代了 BF 中的一位,那么 Counter 到底取多大比较合适呢?这里就要考虑到空间利用率的问题了,从使用的角度来看,当然是越大越好,因为 Counter 越大就能表示越多的信息。但是越大的 Counter 就意味着更多的资源占用,而且在很多时候会造成极大的空间浪费。
因此,我们在选择 Counter 的时候,可以看 Counter 取值的范围多小就可以满足需求。
CBF 虽说解决了 BF 的不能删除元素的问题,但是自身仍有不少的缺陷有待完善,比如 Counter 的引入就会带来很大的资源浪费,CBF 的 FP 还有很大可以降低的空间, 因此在实际的使用场景中会有很多 CBF 的升级版。
比如 SBF(Spectral Bloom Filter)在 CBF 的基础上提出了元素出现频率查询的概念,将CBF的应用扩展到了 multi-set 的领域;dlCBF(d-Left Counting Bloom Filter)利用 d-left hashing 的方法存储 fingerprint,解决哈希表的负载平衡问题;ACBF(Accurate Counting Bloom Filter)通过 offset indexing 的方式将 Counter 数组划分成多个层级,来降低误判率。
PS:CBF的count大小的计算,详细可参考开头的文章。
这次内容主要为复制粘贴,详细原理以后再研究。