搞android逆向,肯定听说过OLLVM是啥(不知道的肯定就是没搞过android逆向的)!想要破解OLLVM,首先要了解OLLVM的原理。要了解OLLVM的原理,就要先了解LLVM的原理!
1、LLVM原理介绍
大家平日里在编译器里写代码,写完后点击编译或运行按钮,都发生了什么了? 可执行的PE或ELF文件都是怎么生成的了?大概的流程如下:

源代码经过fronted前端这个环节,做词法分析、语法分析、语义分析、生成中间代码(简单讲就是检查语法是不是正确的,并生成中间代码;这里的中间码很重要,后续的OLLVM就是在中间码上做文章,这里先打个伏笔);然后进入Optimizer优化环节,比如有些声明但没被使用的变量或函数要不要去掉?很多简单函数之间的调用要不要直接内联合并成一个函数,以便运行时减少堆栈开销? 最后就是bankend后端环节,核心是生成和CPU匹配的机器码!
咋一看这个流程没毛病,完美实现了编译的全流程!然后仔细一想,缺陷也很明显:我用上述流程让C/C++生成x86的代码是OK的,但是我现在想生成arm的代码,后端backend怎么办了?是不是要重新换个生成arm机器码的backend了? 同理:我用Fortran写代码,frontend这里是不是要重新换成Fortran的? 这种编译流程最大的问题:Frontend、Optimizer、backend之间是紧耦合的,互相拆不开!这个问题有点类似计算机网络: 刚开始通信节点的数量少,节点之间互相直连。但是随着计算机的增加,通信需求越来越多,如果每两个节点都要互相连接,最终需要的连接边数就是n*(n-1)/2,这么大的数量显然是不现实的,所以诞生了交换机去中转通信的数据!这里是不是也能借鉴一下交换机的思路了?由此诞生了LLVM架构,如下:
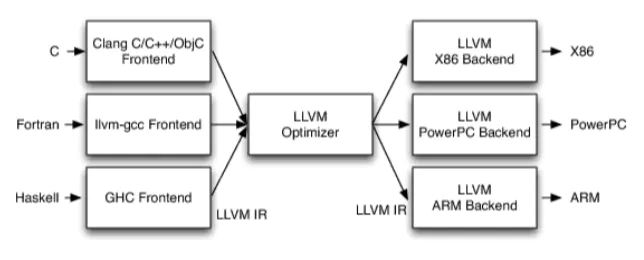
这次把前端、优化、后端解耦分开了!前端每种语言都有对应的Frontend,后端每种cpu都有对应的backend,只有中间优化是统一的!以后每增加一种编程语言,新增一个前端就行了,优化和后端不用改;同理:每增加一种cpu,后端增加一个就行了,前端和优化也不用改,整个架构的扩展性大大提升!LLVM架构详细说明如下:
- 不同的前端后端使用统一的中间代码LLVM Intermediate Representation (LLVM IR)
- 如果需要支持一种新的编程语言,那么只需要实现一个新的前端
- 如果需要支持一种新的硬件设备,那么只需要实现一个新的后端
- 优化阶段是一个通用的阶段,它针对的是统一的LLVM IR,不论是支持新的编程语言,还是支持新的硬件设备,都不需要对优化阶段做修改(前后端都遵从统一的IR标准)
- 相比之下,GCC的前端和后端没分得太开,前端后端耦合在了一起。所以GCC为了支持一门新的语言,或者为了支持一个新的目标平台,就 变得特别困难
- LLVM现在被作为实现各种静态和运行时编译语言的通用基础结构(GCC家族、Java、.NET、Python、Ruby、Scheme、Haskell、D等)
2、OLLVM原理介绍
从名字上看,OLLVM比LLVM多了一个O,这个O就是obfuscator的简写!从字面看,OLLVM就是在LLVM的基础上增加了obfuscator(混淆)!那么这个混淆都是怎么加上的了?
回过头看看上面的LLVM架构,唯一不变的是不是只有中间的Optimizer呀?新增编程语言要新增frotend,新增CPU架构要新增backend,只有中间的optimizer屹立不倒!所以obfuscator最合适的就是在中间optimizer这个环节了!至于OLLVM怎么实操,感兴趣的小伙伴建议google一下,这类文章太多了,这里不再赘述!简单理解:OLLVM有一个框架,这个框架提供了很多API(注意:正式生产环境下OLLVM的API很多,功能也比较复杂,这里只是简单举个例子说明其中之一的功能),调用这些API可以对IR中间代码做各种操作,比如下面这段代码:
ConstantDataSequential *CDS =dyn_cast<ConstantDataSequential>(GV->getInitializer()); if (CDS) { std::string str = CDS->getRawDataValues().str(); errs() << "str:" << str << " "; uint8_t xor_key = llvm::cryptoutils->get_uint8_t(); for (int i = 0; i < str.size(); ++i) { str[i] = str[i] ^ xor_key; }
逐行扫描IR代码(如下)的字符串(这种IR中间代码类似于java的smali代码):
@.str = private unnamed_addr constant [14 x i8] c"test_hello1�D�A�0", align 1 @.str.1 = private unnamed_addr constant [22 x i8] c"hello clang!�D�A�0", align 1 @.str.2 = private unnamed_addr constant [21 x i8] c"hello pendy clang!�D�A�0", align 1 @.str.3 = private unnamed_addr constant [14 x i8] c"test_hello2�D�A�0", align 1
然后通过异或逐个加密这些字符串,达到混淆的目的!文章末尾参考2有OLLVM在github的官网连接,里面介绍了4种混淆的方式;
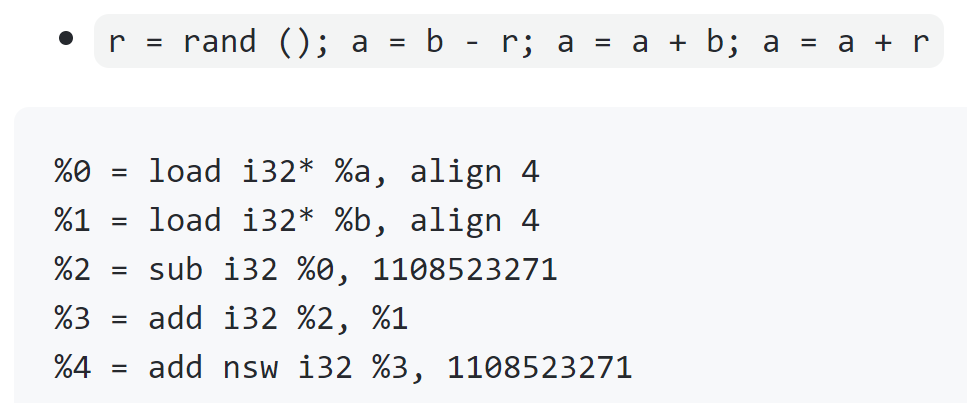
(1)Instructions Substitution:简单理解就是加减法、逻辑运算混淆(https://github.com/obfuscator-llvm/obfuscator/wiki/Instructions-Substitution):比如加法写成如下形式:
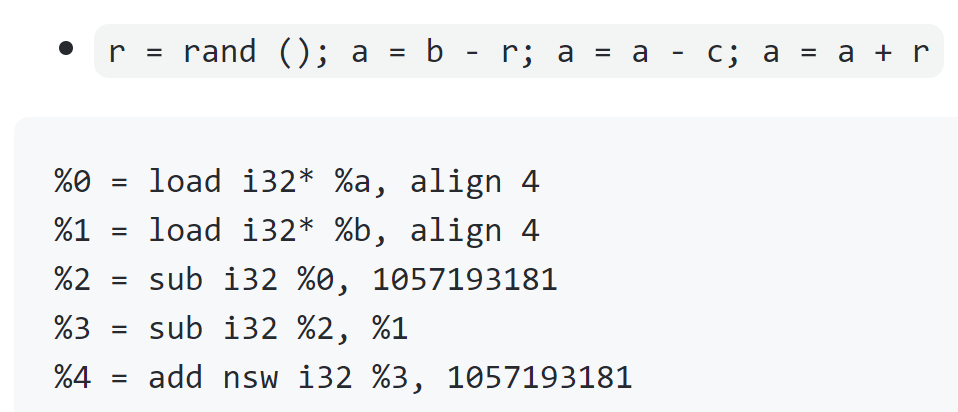
减法写成如下形式:
其他的逻辑运算写成如下形式(这里的思路有点类似VMP的万用门,简单的逻辑运算用复杂的表达式替代):

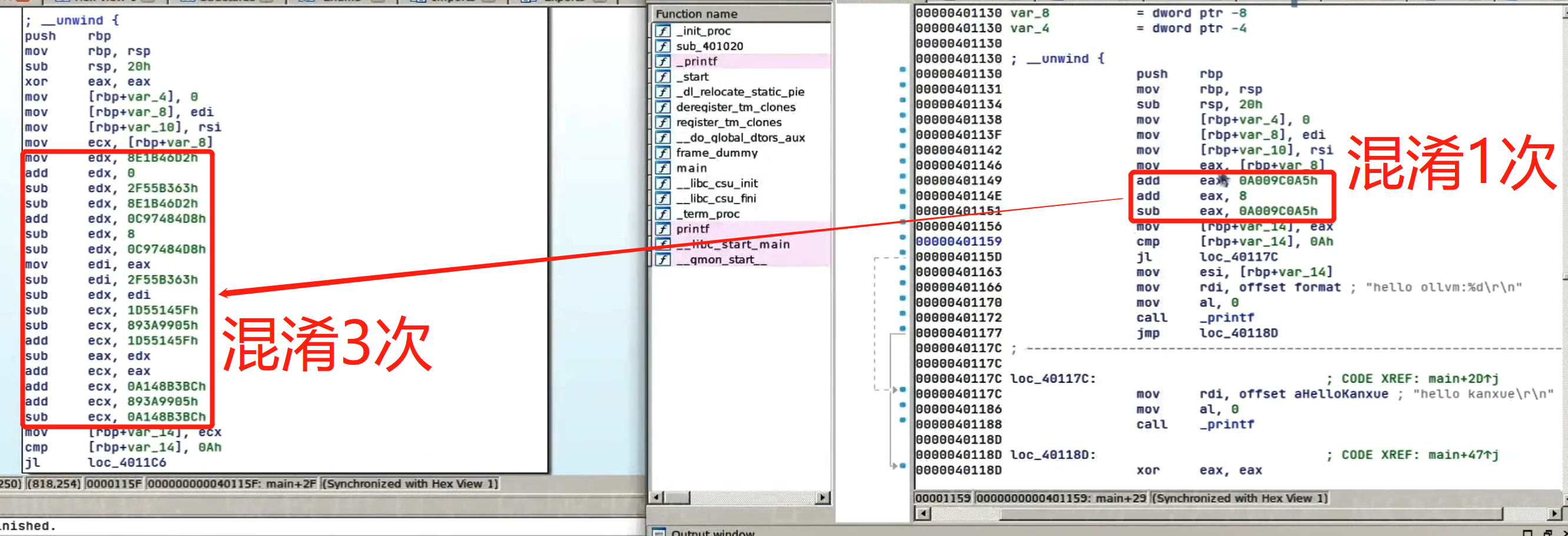
总的来说:Instructions Substitution就是把简单的四则和逻辑运算复杂化!以加法为例,其中一种的混淆结果如下:
(2) Bogus Control Flow 虚假控制流(https://github.com/obfuscator-llvm/obfuscator/wiki/Bogus-Control-Flow)
一段简单如下的代码:
#include <stdlib.h> int main(int argc, char** argv) { int a = atoi(argv[1]); if(a == 0) return 1; else return 10; return 0; }
使用了BCF后的效果:看看多了多少分支!前面这个if条件就是BCF最明显的特征!

官网提供的IR效果如下:
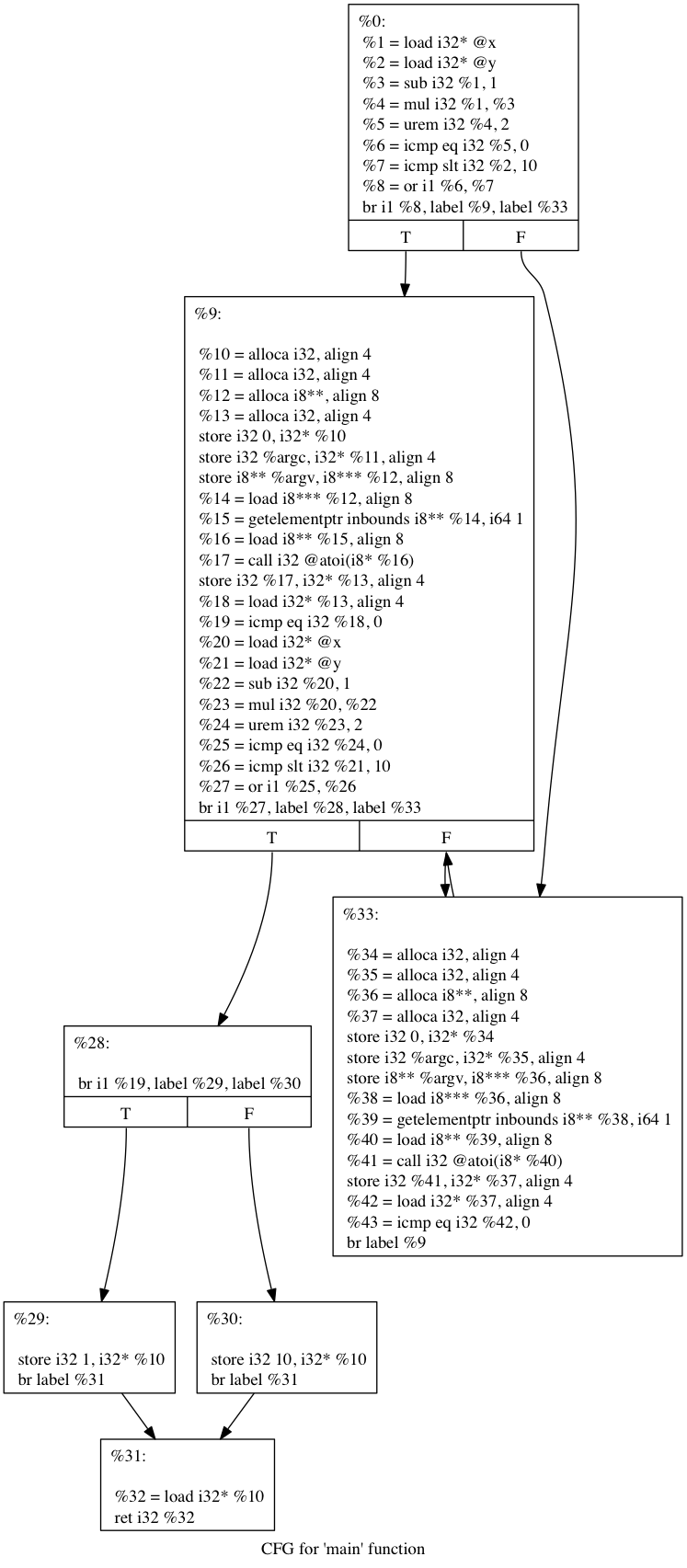
(3)Control Flow Flattening(https://github.com/obfuscator-llvm/obfuscator/wiki/Control-Flow-Flattening)
最常见的混淆就是这种了,原理就是在不改变源代码的功能前提下,将C或C++代码中的if、while、for、do等控制语句转换成switch分支语句。这样做的好处是可以模糊switch中case代码块之间的关系,从而增加分析难度。具体做法是首先将要实现平坦化的方法分成多个基本块(就是case代码块)和一个入口块,为每个基本快编号,并让这些基本块都有共同的前驱模块和后继模块。前驱模块主要是进行基本块的分发,分发通过改变switch变量来实现。后继模块也可用于更新switch变量的值,并跳转到switch开始处,流程如下:
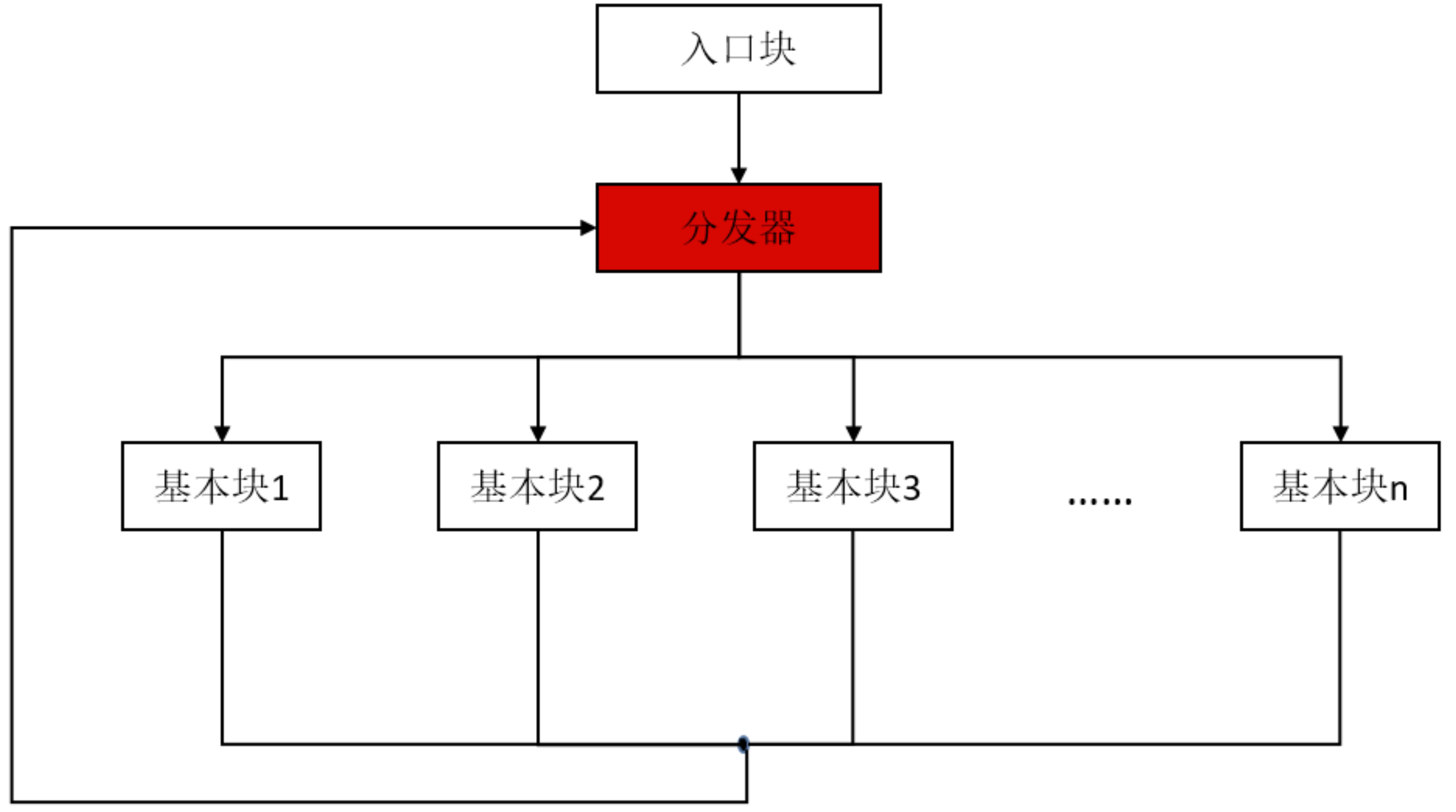
实际效果如下:
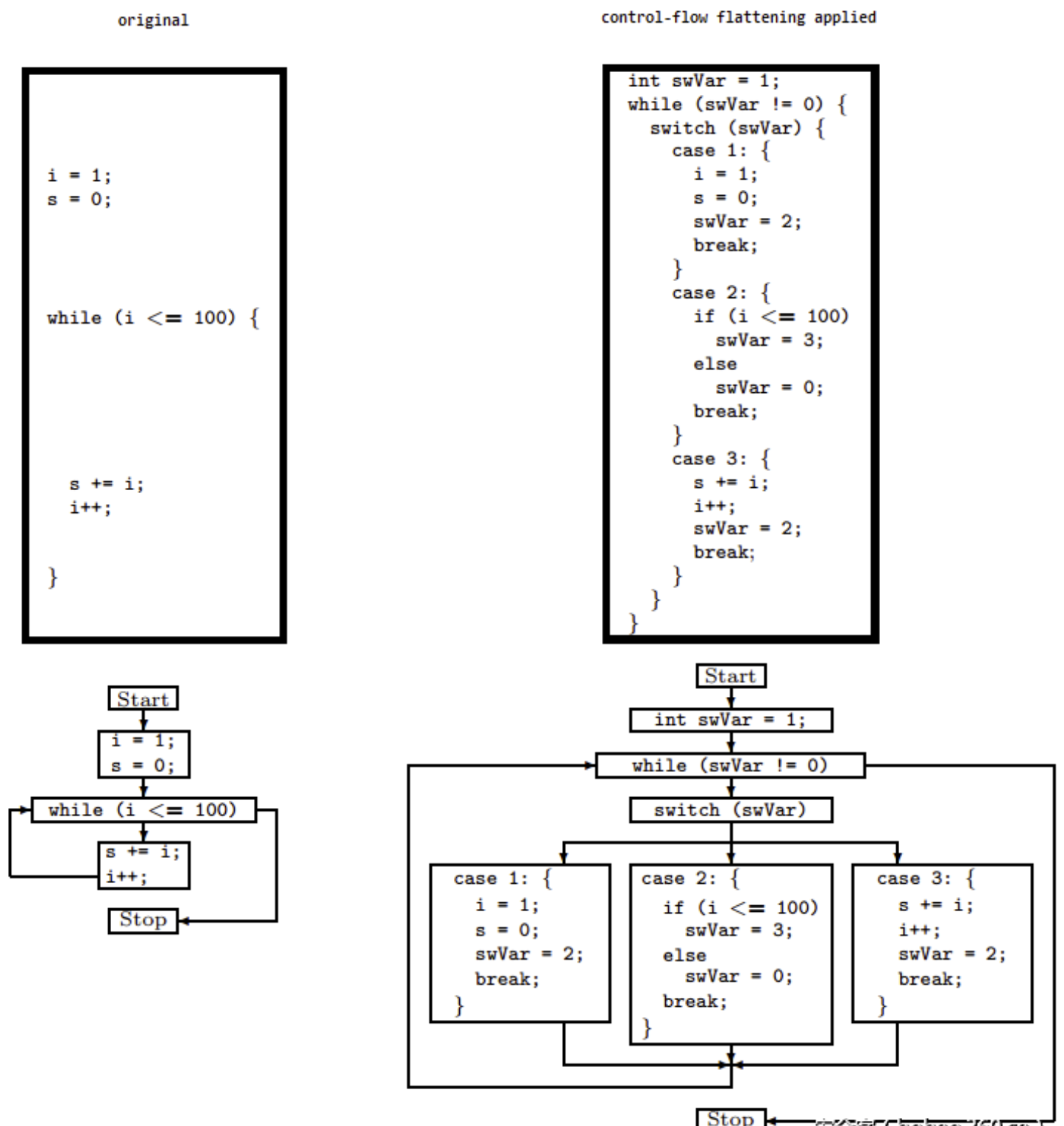
把上面那个简单的案例用虚假控制流和控制流平坦化一起使用,效果如下:

上述这个算好的,真实CFF混淆后的so用IDA打开,效果如下:这种分支被增加地已经没法静态分析了!
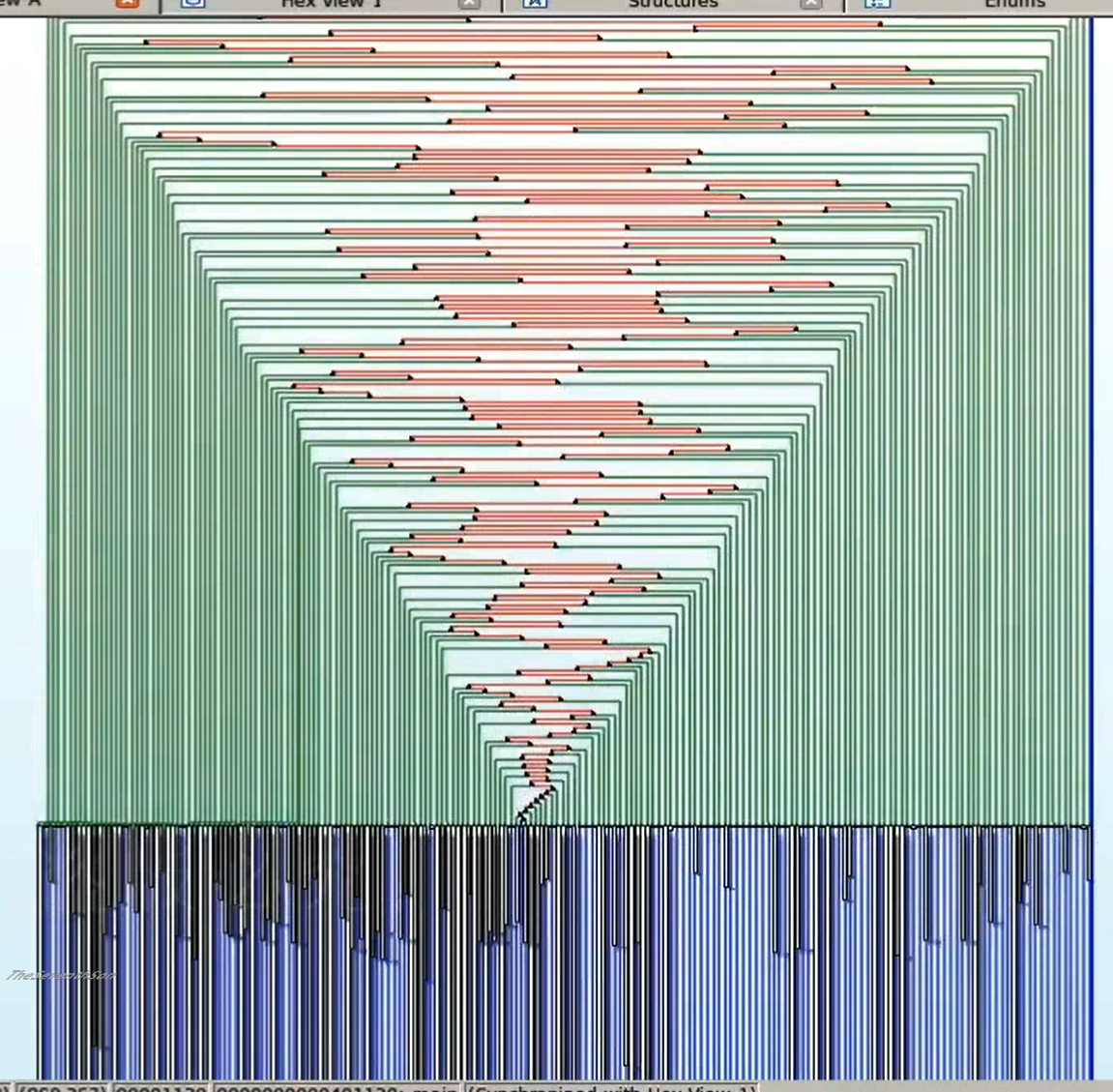
(4)字符串加密:就是第2节开头举得那个例子!调用OLLVM提供的API,找到所有的字符串,然后根据业务需求挨个加密!
3、上面介绍了常见的OLLVM混淆方法,该怎么去破解了?
(1)先拿最简单的字符串加密/混淆举例:常见的字符串加密方式是异或,然后在init_array里面解密;有耐心的同学可以尝试在init_array去分析代码,看看能不能找到key后解密字符串;这里其实还有更简单的办法:直接用frida hook字符串的地址后打印出来即可,脚本如下:findBaseAddress的参数传入so的名称,得到so在内存的基址;add函数传入字符串在so内部的偏移,得到字符串的绝对地址;然后直接用log函数把地址的数据打印出来即可:
function hook_native() { var base_hello_jni = Module.findBaseAddress("libhello-jni.so"); if (base_hello_jni) { //ollvm默认的字符串混淆,静态的时候没法看见字符串 //执行起来之后,先调用.init_array里面的函数来解密字符串 //解密完之后,内存中的字符串就是明文状态了。 var addr_37070 = base_hello_jni.add(0x37070); console.log("addr_37070:", ptr(addr_37070).readCString()); } }
或者这样写,然后通过frida -U传入字符串首地址的偏移:
function print_string(addr) { var base_hello_jni = Module.findBaseAddress("libhello-jni.so"); var addr_str = base_hello_jni.add(addr); console.log("addr:", addr, " ", ptr(addr_str).readCString()); }
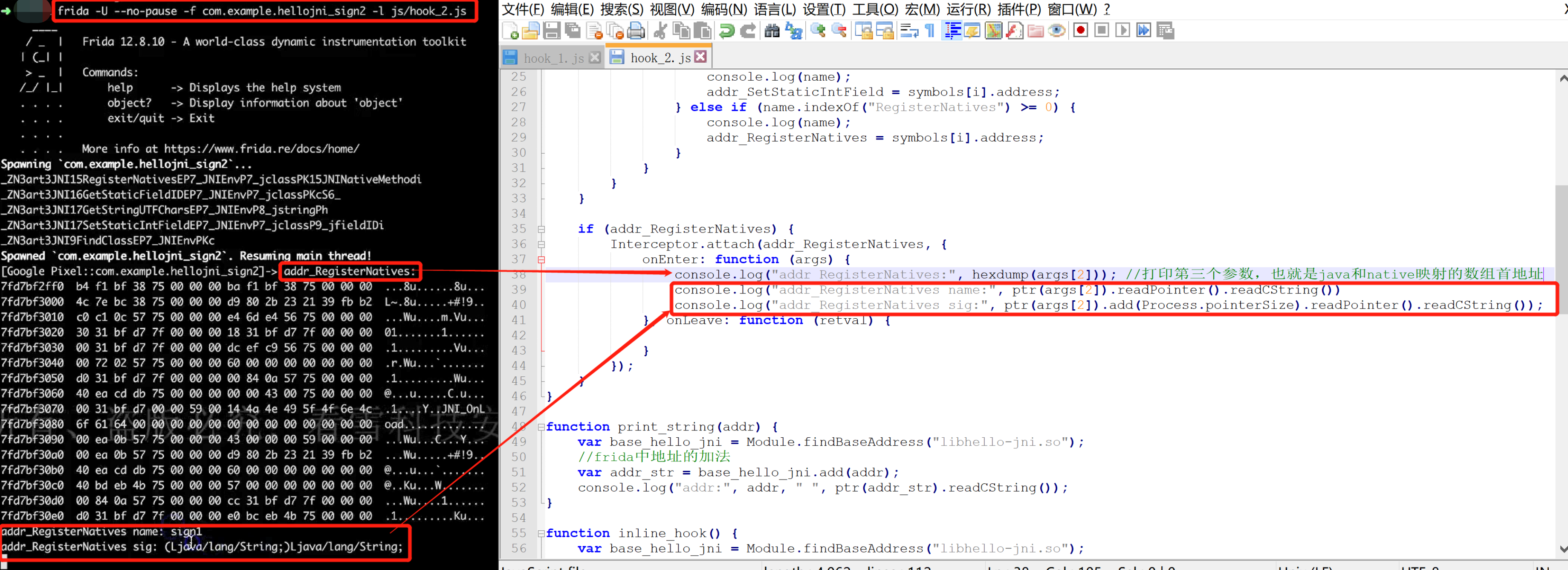
还有另一类字符串打印:registerNative的第三个参数,也就是动态注册时java层函数和native层函数映射关系的JNINativeMethod,简单的打印函数如下:
Interceptor.attach(addr_RegisterNatives, { onEnter: function (args) { console.log("addr_RegisterNatives:", hexdump(args[2])); //打印第三个参数,也就是java和native映射的数组首地址 console.log("addr_RegisterNatives name:", ptr(args[2]).readPointer().readCString())//java层函数名称 console.log("addr_RegisterNatives sig:", ptr(args[2]).add(Process.pointerSize).readPointer().readCString());//函数参数 console.log("addr_RegisterNatives sig:", ptr(args[2]).add(Process.pointerSize+Process.pointerSize));//native函数入口地址 }, onLeave: function (retval) { } });
registerNative更完整的打印函数可以参考:https://github.com/lasting-yang/frida_hook_libart 或 https://www.52pojie.cn/thread-1182860-1-1.html
(2)控制流平坦化(虚假控制流原理类似:这两种方式都是对控制流做文章的,都是改变了原控制流,只是改变的方式不同,两者没本质区别):平日见的最多的就是这种混淆方式了!这种方式说白了就是把if、while、for、do等控制语句改造成switch、case,让case之间看不出明显的逻辑关系;每个case执行完后更改“信号量”,以此决定下一次循环走那个case;这种混淆方式平白无故增加了很多无用的case分支,但是绝对不敢乱改原来的函数调用关系!所以即使被用这种方式混淆,但原来的函数调用还是真实的!基于这点,可以根据经验筛选出一些重点函数来hook,看看这些函数的参数都是啥,都返回了什么,以此来猜测这些函数的功能!常见的so层js hook代码(java层建议直接用objection,非常方便)如下:
- 被动hook某个函数(这里用的是Java.use,而主动调用用的是Java.choose),打印参数和返回值
function hook_sign2() { Java.perform(function () { var HelloJni = Java.use("com.example.hellojni.HelloJni"); HelloJni.sign2.implementation = function (str, str2) { var result = this.sign2(str, str2); console.log("HelloJni.sign2:", str, str2, result); return result; }; }); }
如果函数是静态注册的,也能这样写代码,就不用去IDA手动查函数偏移了:
var sign2 = Module.findExportByName("libhello-jni.so", "Java_com_example_hellojni_HelloJni_sign2"); console.log(sign2); Interceptor.attach(sign2, { onEnter: function (args) { //jstring console.log("sign2 str1:", ptr(Java.vm.tryGetEnv().getStringUtfChars(args[2])).readCString()); console.log("sign2 str2:", ptr(Java.vm.tryGetEnv().getStringUtfChars(args[3])).readCString()); }, onLeave: function (retval) { console.log("sign2 retval:", ptr(Java.vm.tryGetEnv().getStringUtfChars(retval)).readCString()); } });
有些函数是通过参数保存返回值的,比如sub_1AB4C(v1,v2,&v3)这种,把V3的地址传入函数,并且V3在后续的代码也被使用了,所以这里有可能是V3保存了函数的处理结果,下面这种方式可以打印保存结果(注意:这里还能直接取寄存器的值,调试更方便了):
var sub_1AB4C = base_hello_jni.add(0x1AB4C); Interceptor.attach(sub_1AB4C, { onEnter: function (args) { this.arg2 = args[2];
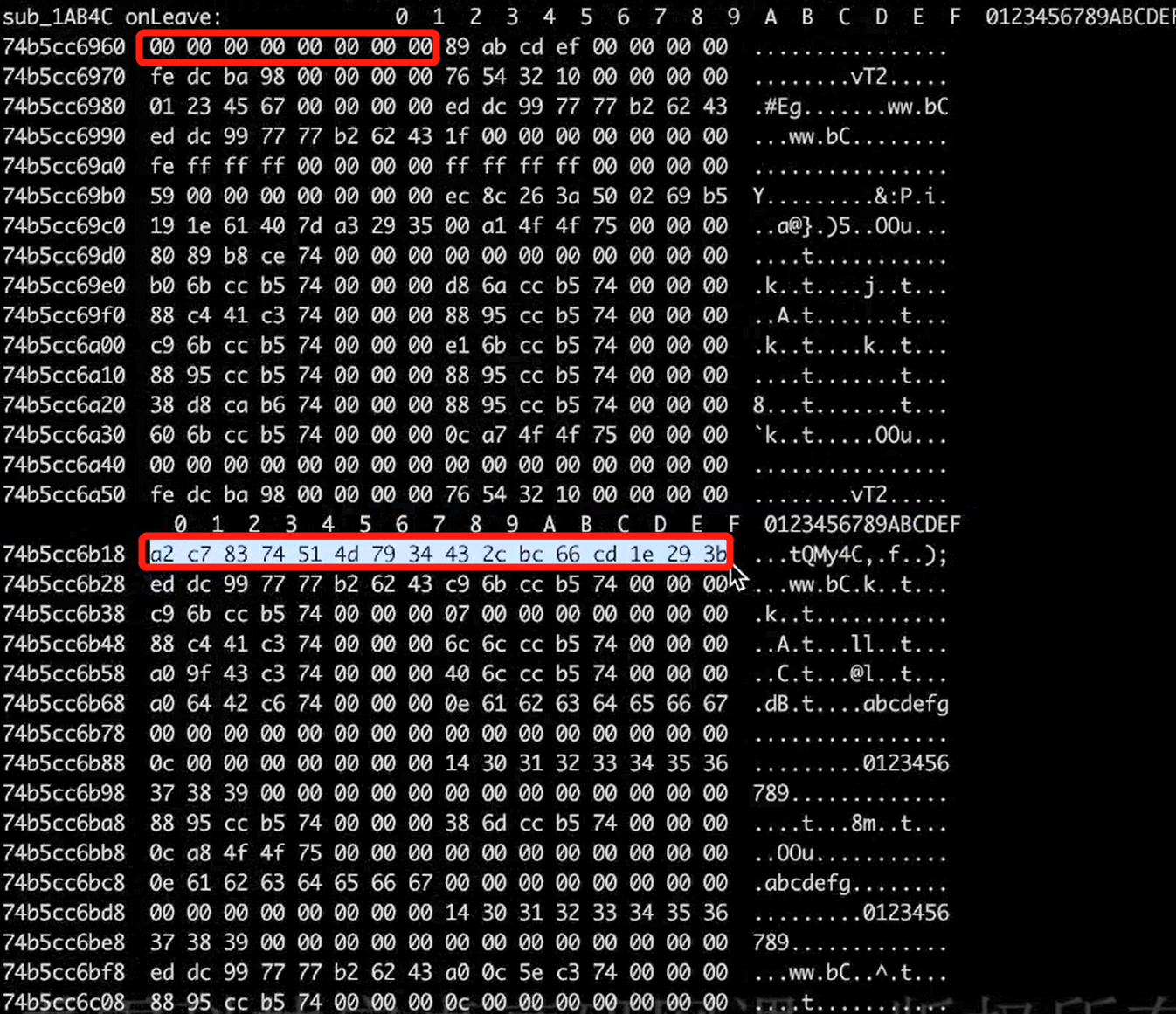
this.arg8 = this.context.x8;//注意这里还可以读取寄存器 console.log("sub_1AB4C onEnter:", hexdump(args[0]), args[1], " ", hexdump(args[2])); }, onLeave: function (retval) { console.log("sub_1AB4C onLeave:", hexdump(retval), " ", hexdump(this.arg2));//args[2]传参时取了地址,在后面也会用到,所以这个参数有可能保存了返回值,这里打印出来看看
console.log("sub_1AB4C onLeave:", hexdump(this.arg8))
}
});
效果如下:retval啥都没有,但是args2的值就有,说明函数处理的结果确实保存在了参数里,而不是返回值:
- 另一些小技巧:以16进制打印指针,看看指针指向的内容到底是啥,更利于后续分析
console.log("sub_12D70 onLeave arg2:", hexdump(ptr(this.arg2).add(Process.pointerSize).readPointer()));
打印出来就这种效果:
- 主动调用某个函数(这里用的是Java.choose,被动调用用的是Java.use):这个功能很好,可以主动调用某些so层函数,避免了直接操作app才能执行这些函数的尴尬;调用方式也简单,先进入frida -U,然后在命令行输入call_sign2即可;
function call_sign2() { Java.perform(function () { Java.choose("com.example.hellojni.HelloJni", { onMatch: function (ins) { var result = ins.sign2("0123456789", "abcdefghakdjshgkjadsfhgkjadshfg"); console.log(result); }, onComplete: function () { } }); }); }
效果还不错:

以上hook函数的方式,我个人觉得和通过IDA调试so代码在功能上没本质区别,但还是更推荐这种hook方式,原因:
- js代码热更新:更改js代码后不需要重启app,立即生效,非常方便
- IDA调试需要逐行跟踪汇编指令,遇到各种混淆容易陷入局部“迷茫”(不知道现在走到哪了,不知道现在在干嘛)!而这种hook函数的方式可以站在更高的方法层级观察某个位置函数的功能(打印参数和返回值),更累利于“站在上帝视角”理解函数整体的功能!
(3)trace:frida、IDA、unicorn/unidbg的trace,逐行跟踪指令的执行,那些存粹用来混淆静态分析的指令自然就被过滤掉了!后续会专门分享这些工具的用法!
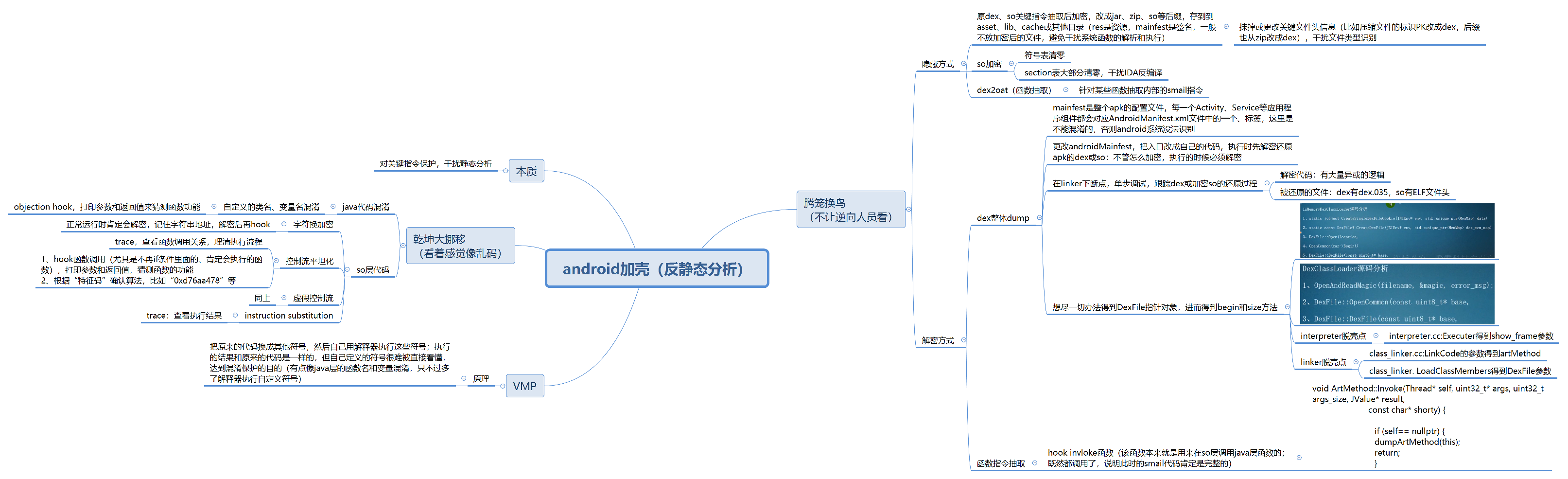
(4)android加壳方式总结:
参考:
1、https://xz.aliyun.com/t/7257 初探LLVM
2、https://github.com/obfuscator-llvm/obfuscator/wiki/features OLLVM4种features
3、https://www.anquanke.com/post/id/85843 Android代码混淆技术总结