NIPS 2018 | 程序翻译新突破:UC伯克利提出树到树的程序翻译神经网络
选自arXiv,作者:Xinyun Chen、Chang Liu、Dawn Song,机器之心编译,参与:Geek AI、张倩。
程序翻译是将一种语言的遗留代码迁移到用另一种语言构建的生态系统的重要工具。本文作者首次使用深度神经网络来解决程序翻译问题。他们观察到程序翻译是一个模块化的过程并据此设计了一个树到树的神经网络,将源树转换为目标树。与其他神经翻译模型相比,该方法始终比对比基线好 15 个百分点以上。此外,该方法的性能在实际项目的翻译上比目前最先进的程序翻译方法高 20 个百分点。
程序是构建计算机应用、IT 产业和数码世界的主要工具。为了方便程序员为不同的应用开发程序,人们发明了各种编程语言。与此同时,当程序员想要将用不同语言编写的程序组合在一起时,这些编程语言的差异就为这项工作带来了困难。因此,实现不同编程语言之间的程序翻译是十分必要的。
如今,为了在不同的编程语言之间翻译程序,程序员通常会自己亲自研究两种语言语法之间的对应关系,然后开发一个基于规则的翻译器。然而,这个过程可能效率低下,而且十分容易出错。在本文的工作中,我们首次尝试检验是否可以利用深度神经网络来自动构建一个程序翻译器。
凭直觉看,程序翻译问题在其形式上类似于自然语言翻译问题。先前的一些工作提出将基于短语的统计机器翻译(SMT)用于代码迁移 [26,20,27]。最近,基于序列到序列(Seq2Seq)的模型等神经网络方法在机器翻译方面取得了当前最佳性能 [5,10,14,15,36]。在本文中,作者研究了使用神经机器翻译方法来处理程序翻译问题。然而,使基于序列到序列的模型失效的一个巨大挑战是:与自然语言不同,编程语言有严格的语法,它不能容忍拼写错误和语法错误。已经证明,当编程语言序列变得太长时 [21],基于 RNN 的序列生成器很难生成句法正确的程序。
在本文的工作中,我们注意到,RNN 很难生成句法正确程序的主要原因是它将两个子任务——学习语法及对齐序列与语法——纠缠在了一起。当这两个任务可以被分别处理时,模型的性能通常会提高。例如,Dong 等人使用了一个基于树的解码器来分离两个任务 [12]。特别是 [12] 中的解码器利用树结构信息:(1)使用 LSTM 解码器在解析树的相同深度生成节点;(2)展开一个非叶子节点并在解析树中生成它的子元素。这种方法已被证明可以在一些语义解析任务上取得目前最好的结果。
受到这个观测结果的启发,我们假设可以利用源解析树和目标解析树的结构信息来实现这种分离。受这种直觉的启发,我们提出树到树的神经网络,将树编码器和树解码器结合在一起。特别地,我们注意到在程序翻译问题中,源程序和目标程序都有各自的解析树。此外,跨语言的编译器通常遵循一个模块化过程,将源树中的各个子组件转换为相应的目标组件,然后使用它们组合成最终的目标树。因此,我们设计了一种树到树神经网络的工作流程来配合这个过程:当解码器展开一个非叶子节点时,它会使用注意力机制在源树中定位对应的子树,并利用子树的信息来引导非叶子节点展开。特别需要注意的是,树编码器在这种情况下有很大的作用,因为它可以将子树的所有信息聚合到它的根的嵌入中,这样嵌入就可以用来指导目标树的非叶子节点扩展。
我们根据上述直觉来设计树到树的转换模型。一些现有的工作 [34,22] 提出了基于树的自动编码器体系架构。但是,在这些模型中,解码器只能访问表示源树的单个隐藏向量,因此它们在翻译任务中不够高效。在我们对模型的评价过程中,我们证明了在没有注意力机制的情况下,翻译性能在大多数情况下为 0%,而使用注意机制可以将性能提升到 90% 以上。论文「Towards neural machine translation with latent tree attention」提出了一种用于自然语言翻译的基于树的注意力编码器-译码器架构,但其模型的性能甚至比注意力序列到序列的对比基线模型更差。一个主要原因是,它们的注意力机制独立地计算每个节点的注意力权值,这并不能很好地捕获解析树的层次结构。在本文的工作中,作者设计了一个父亲节点注意力反馈机制,该机制建立了不同节点之间的注意力映射依赖关系,作者证明了这种注意力机制进一步提高了树到树模型的性能,特别是当解析树变大时(即获得了 20%−30% 的性能提升)。据我们所知,这是目前针对翻译任务提出的树到树神经网络架构的首次成功展示。
为了检验我们的假设,我们开发了两个新的程序翻译任务,并使用现有的 Java 到 c# 的程序翻译工作 [26,27] 进行对比基准测试。首先,我们在提出的两个任务上,对我们的方法和一些神经网络方法进行了对比。实验结果表明,我们的树到树模型在程序翻译任务上优于其他最先进的神经网络,在单词翻译的准确率上提升了 5%,在程序翻译的准确率上提升了 15%。此外,我们将我们的方法与以前在 Java 到 c# 对比基准上的程序翻译方法进行了比较,结果显示,我们的树到树模型在程序翻译的准确率上比以前的技术领先 20%。这些结果表明,我们的树到树模型在解决程序翻译问题上是很有发展前景的。同时,我们认为我们提出的树到树神经网络也可以适用于其他树到树的任务,这将是我们未来的工作。
论文:Tree-to-tree Neural Networks for Program Translation

论文链接:https://arxiv.org/pdf/1802.03691.pdf
摘要:程序翻译是将一种语言的遗留代码迁移到用另一种语言构建的生态系统的重要工具。在本文的工作中,我们首次使用深度神经网络来解决程序翻译问题。我们观察到程序翻译是一个模块化的过程,在这个过程中,源树的子树在每一步都被转换成相应的目标子树。为了利用这种直觉,我们设计了一个树到树的神经网络,将源树转换为目标树。同时,我们为树到树模型开发了一种注意力机制,当解码器在目标树中展开一个非叶子节点时,注意力机制会在源树中定位相应的子树来引导解码器展开。我们将树到树模型的程序翻译能力和一些目前最先进的方法进行比较,从而对其进行评价。与其他神经翻译模型相比,我们的方法始终比对比基线好 15 个百分点以上。此外,我们方法的性能在实际项目的翻译上比以前最先进的程序翻译方法提高了 20 个百分点。
2 程序翻译问题的形式化定义
定义 1(程序翻译)
给定两种编程语言 L_s 和 L_t,每种编程语言都有一组实例(p_k,T_k),其中 T_k 是这种语言对应的解析树。我们假设存在标准的翻译结果 π,它能将 L_s 中的实例完美地映射到 L_t 的实例上。给定一个实例对(i_s,i_t)的数据集,我们有 i_s ∈ L_s, i_t ∈ L_t 且 π(i_s) = i_t,本文研究的问题就是如何学习到一个函数 F 能够将每个 i_s ∈ L_s 映射到 i_t = π(i_s) 上。
3 树到树的神经网络
3.1 将程序翻译看做一个树到树的翻译问题
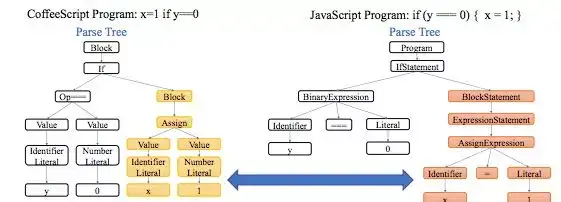 图 1:将一个 CoffeeScript 程序翻译成一个 JavaScript 程序。CoffeeScript 程序的子组件及其在 JavaScript 中相对应的翻译结果被高亮显示了出来。
图 1:将一个 CoffeeScript 程序翻译成一个 JavaScript 程序。CoffeeScript 程序的子组件及其在 JavaScript 中相对应的翻译结果被高亮显示了出来。
图 1 展示了一个从 CoffeeScript 到 JavaScript 的翻译示例。我们注意到程序翻译问题的一个有趣特性是,翻译过程可以是模块化的。图中高亮显示了源树中对应于 x=1 的子组件及其在目标树中对应于 x=1 的翻译结果;这种对应关系独立于程序的其他部分。当程序变得更长,这样的情况可能重复发生多次时,序列到序列模型可能很难仅基于没有结构信息的 token 序列来捕获对应关系。因此,当将目标树中的非叶子节点扩展为子树时,这样的对应关系使得在源树中定位引用的子树成为一种自然的解决方案。
3.2 树到树的神经网络
在上述动机的启发下,我们设计了树到树的神经网络,它遵循了一个编码器-解码器框架,将源树编码为嵌入,并将嵌入解码为目标树。为了利用模块化翻译过程的直觉,解码器在展开非叶子节点时采用了注意力机制来定位相应的源子树。我们在图 2 中展示了树到树模型的工作流。

图 2:树到树模型的工作流:箭头表示计算流。蓝色实箭头表示指向左子节点/从左子节点流入的流,橙色虚线箭头表示右子节点的流。从源树根到目标树根的黑色点箭头代表 LSTM 状态被复制。绿色框表示扩展节点,灰色框表示队列中待扩展的节点。与扩展节点对应的源树的子树用黄色高亮显示。右下角列出了预测扩展节点值的公式。
4 模型评价
在本章中,作者在程序翻译任务上评价了本文提出的树到到树神经网络和其它一些对比基准方法。
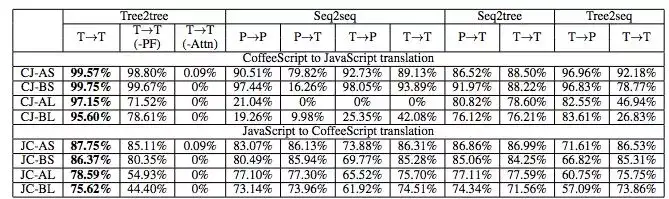 表 1:在 CoffeeScript 和 JavaScript 之间进行翻译的程序准确率。token 准确率见附录 C
表 1:在 CoffeeScript 和 JavaScript 之间进行翻译的程序准确率。token 准确率见附录 C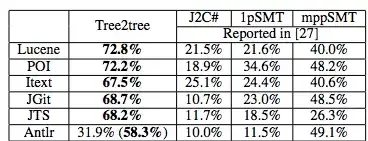
NeurIPS 2018相关论文链接:
NeurIPS 2018提前看:生物学与学习算法
NeurIPS 2018,最佳论文也许就藏在这30篇oral论文中
NeurIPS 2018 | 腾讯AI Lab&北大提出基于随机路径积分的差分估计子非凸优化
NeurIPS 2018亮点选读:深度推理学习中的图网络与关系表征
NeurIPS 2018提前看:可视化神经网络泛化能力
Google AI提出物体识别新方法:端到端发现同类物体最优3D关键点——NeurIPS 2018提前看
MIT等提出NS-VQA:结合深度学习与符号推理的视觉问答
画个草图生成2K高清视频,这份效果惊艳研究值得你跑一跑
下一个GAN?OpenAI提出可逆生成模型Glow
CMU、NYU与FAIR共同提出GLoMo:迁移学习新范式
Quoc Le提出卷积网络专属正则化方法DropBlock
Edward2.2,一种可以用TPU大规模训练的概率编程
南大周志华等人提出无组织恶意攻击检测算法UMA
MIT新研究参透批归一化原理
程序翻译新突破:UC伯克利提出树到树的程序翻译神经网络
将RNN内存占用缩小90%:多伦多大学提出可逆循环神经网络
哪种特征分析法适合你的任务?Ian Goodfellow提出显著性映射的可用性测试
行人重识别告别辅助姿势信息,商汤、中科大提出姿势无关的特征提取GAN
作为多目标优化的多任务学习:寻找帕累托最优解
Dropout可能要换了,Hinton等研究者提出神似剪枝的Targeted Dropout
利用Capsule重构过程,Hinton等人实现对抗样本的自动检测