Deep one-class classification
|
论文名:Deep one class classification |
|
|
作者:Lukas Ruff * 1 Robert A. Vandermeulen * 2 Nico Gornitz ¨ 3 |
|
|
发表刊物:ICML |
|
|
发表时间:2018 |
|
|
相关概念: OCSVM SVDD |
|
|
提出方法: Deep SVDD |
|
|
Abstract |
|
|
Those approaches which do exist involve networks trained to perform a task other than anomaly detection, namely generative models or compression, which are in turn adapted for use in anomaly detection; they are not trained on an anomaly detection based objective. 确实存在一些方法,使用训练的网络来执行异常检测之外的任务,被称为生成模型或压缩,反过来也可以被用在异常检测中,他们没有在基于异常检测的目标上进行训练。 |
|
|
Introduction |
|
|
需要能在很大的数据集、很高维的数据中检测异常 传统的异常检测方法: One-Class SVM单分类SVM (OCSVM):最优超平面,坐标原点被假定为唯一的异常样本 SVDD:原始数据--高维表示--Min超球体积--求得c和R。 Kernel Density Estimation 核密度估计(KDE) 缺点: 1、浅层特征工程。由于糟糕的计算可扩展性和维度诅咒,导致在高维数据场景中经常失败。为了有效,这种浅层方法通常需要大量的特征工程。 2、由于和矩阵的构造和操作导致a poor computational scaling,除非使用近似技术,否则规模至少为样本数的平方。 3、核方法需要存储支持向量,需要大量内存。 深度学习的方法: 用深度学习做异常检测的难点在于找到合适的无监督学习深度对象是很困难的 现在的一些方法结果不错,但是他们都没有通过优化基于异常检测目标函数的优化来进行训练,并且大多是有依赖于基于重建误差的启发式算法 mix: --------------------- 本文提出了一种新的深度异常检测的方法,灵感来源于基于核的单分类问题以及最小体积估计。 1、我们的方法Deep SVDD,训练一个神经网络,然后最小化包含网络中数据特征的超球体积,提取数据分布变化的共同因素。fully deep //unsupervised other deep AD: 依赖重建误差,无论是在用于学习表示的混合方法中,还是直接用于学习和检测中。 2、Deep autoencoder:会有低维的中间表示,最小化重建误差。网络可以从正常的样本中提取出共同因子并进行重建,二异常样本这些共同的因素所以不能被准确的重建。可以在Mix和fully deep中使用。mix:将学习到的 嵌入向量运用到传统的AD 中。fully deep:直接用重建误差作为异常分数。 denoising autoencoder、variational autoencoder、sparse autoencoder、deep convolutional autoencoder(DCAEs)(应用于图像视频数据的AD应用中)自动编码器不直接以AD为目标,应用与此的主要困难是压缩的度,也就是降维的度。 3、AnoGAN:test data--生成样本--潜在空间表示。重建误差、异常分数。与自动编码器类似,困难在于如何正则化(规范化)生成器以实现紧凑性。 |
|
|
method |
|
|
Soft-bound Deep SVDD,一种深度一分类的方法 联合学习参数W和最小化在输出空间包含数据的超球的体积 目标函数:
第一项最小化超球体积。 第二项是对那些位于超球外的惩罚项,超参v控制超球体积和超过边界的一个权衡。如果v大,就允许一定的超出,如果v很小,超出一点就施以很大的惩罚。 第三项是网络参数W上的权重衰减正则化。 One-Class Deep SVDD 目标函数:
第一项,使用二次损失来惩罚每个网络表示到超球中心的距离。 第二项,网络权重衰减正则项,λ是超参。 One-Class Deep SVDD也可以视为找到最小体积的超球。 但与软边界deep SVDD不同,deep SVDD通过直接惩罚半径和落在球体外的数据表示而收缩球体,One-Class Deep SVDD通过最小化所有数据表示到中心的平均距离来收缩球体。 同样,为了将数据(平均)尽可能映射到接近中心c,神经网络必须提取变异的共同因子。 对所有数据点上的平均距离进行惩罚而不是允许某些点落在超球外,这与大多数训练数据来自一个类的假设是一致的。
异常分数可以用上式来计算,异常样本结果为正,正常样本结果为负。 |
|
|
优化 Deep SVDD |
|
| 命题1 权重是全0的话,网络产生一个常数函数映射到超球中心,导致超球崩溃,因为超球半径为0。
命题2 网络中的隐藏层有偏移项bias term,也是学习到一个常数函数映射,导致超球崩溃。
命题3 具有有界激活函数的网络单元,会在后续层中模拟偏移项,这又导致超球崩溃。 因此,在Deep SVDD中应首选无界激活函数(或仅被0 bound的函数),例如ReLU,以避免由于“学习”偏移项导致的超球崩溃。 |
|
| results | |
|
SVDD和OCSVM的比较版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
OCSVM(one class support vector machine)即单类支持向量机,最先提出的文献为:Estimating the support of a high-dimensional distribution. 该模型 将数据样本通过核函数映射到高维特征空间,使其具有更良好的聚集性,在特征空间中求解一个最优超平面实现目标数据与坐标原点的最大分离,如图1: 坐标原点被假设为唯一的一个异常样本,最优超平面与坐标原点最大距离为 SVDD((Support Vector Data Description)即支持向量数据描述,最先提出的文献为:Support Vector Data Description,,其基本思想是通过在映射到高维的特征空间中找出一个包围目标样本点的超球体,并通过最小化该超球体所包围的体积让目标样本点尽 能地被包围在超球体中,而非目标样本点尽可能地排除在超球体中,从而达到两类之间划分的目的。该方法目标是求出能够包含正常数据样本的最小超球体的中心a和半径R。 两种单分类方法的区别与联系: 通过以上的分析 ,建立了 2种模型之间存在的联系 ,可见不同之处在于对 参考:基于支持向量的单类分类方法综述 吴定海,张培林,任国全,陈非 |

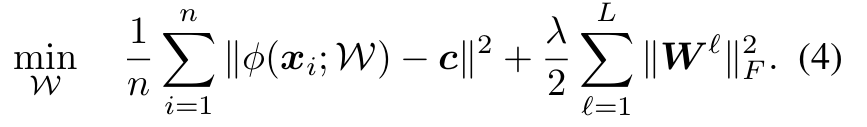

 , 并允许少部分样本在坐标原点与分界面之间,与分类超平面的距离为
, 并允许少部分样本在坐标原点与分界面之间,与分类超平面的距离为 。
。
 的标准化约束和误差函数,当对数据进行标准化处理后 ,2种模型能够取得一样的效果 。同时SVDD的论文指出当采用高斯核函数时,2种模型对数据的描述效果相当。
的标准化约束和误差函数,当对数据进行标准化处理后 ,2种模型能够取得一样的效果 。同时SVDD的论文指出当采用高斯核函数时,2种模型对数据的描述效果相当。