你好呀,我是歪歪。
前几天和一个大佬聊天的时候他说自己最近在做线程池的监控,刚刚把动态调整的功能开发完成。
想起我之前写过这方面的文章,就找出来看了一下:《如何设置线程池参数?美团给出了一个让面试官虎躯一震的回答。》
然后给我指出了一个问题,我仔细思考了一下,好像确实是留了一个坑。
为了更好的描述这个坑,我先给大家回顾一下线程池动态调整的几个关键点。
首先,为什么需要对线程池的参数进行动态调整呢?
因为随着业务的发展,有可能出现一个线程池开始够用,但是渐渐的被塞满的情况。
这样就会导致后续提交过来的任务被拒绝。
没有一劳永逸的配置方案,相关的参数应该是随着系统的浮动而浮动的。
所以,我们可以对线程池进行多维度的监控,比如其中的一个维度就是队列使用度的监控。
当队列使用度超过 80% 的时候就发送预警短信,提醒相应的负责人提高警惕,可以到对应的管理后台页面进行线程池参数的调整,防止出现任务被拒绝的情况。
以后有人问你线程池的各个参数怎么配置的时候,你先把分为 IO 密集型和 CPU 密集型的这个八股文答案背完之后。
加上一个:但是,除了这些方案外,我在实际解决问题的时候用的是另外一套方案”。
然后把上面的话复述一遍。

那么线程池可以修改的参数有哪些呢?
正常来说是可以调整核心线程数和最大线程数的。
线程池也直接提供了其对应的 set 方法:
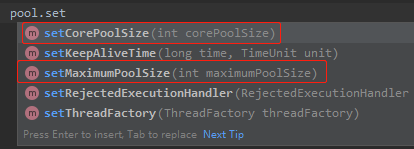
但是其实还有一个关键参数也是需要调整的,那就是队列的长度。
哦,对了,说明一下,本文默认使用的队列是 LinkedBlockingQueue。
其容量是 final 修饰的,也就是说指定之后就不能修改:
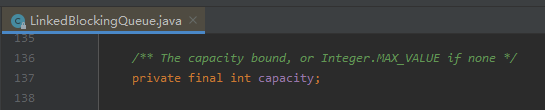
所以队列的长度调整起来稍微要动点脑筋。
至于怎么绕过 final 这个限制,等下就说,先先给大家上个代码。
我一般是不会贴大段的代码的,但是这次为什么贴了呢?
因为我发现我之前的那篇文章就没有贴,之前写的代码也早就不知道去哪里了。
所以,我又苦哈哈的敲了一遍...

import cn.hutool.core.thread.NamedThreadFactory;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadChangeDemo {
public static void main(String[] args) {
dynamicModifyExecutor();
}
private static ThreadPoolExecutor buildThreadPoolExecutor() {
return new ThreadPoolExecutor(2,
5,
60,
TimeUnit.SECONDS,
new ResizeableCapacityLinkedBlockingQueue<>(10),
new NamedThreadFactory("why技术", false));
}
private static void dynamicModifyExecutor() {
ThreadPoolExecutor executor = buildThreadPoolExecutor();
for (int i = 0; i < 15; i++) {
executor.execute(() -> {
threadPoolStatus(executor,"创建任务");
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
threadPoolStatus(executor,"改变之前");
executor.setCorePoolSize(10);
executor.setMaximumPoolSize(10);
ResizeableCapacityLinkedBlockingQueue<Runnable> queue = (ResizeableCapacityLinkedBlockingQueue)executor.getQueue();
queue.setCapacity(100);
threadPoolStatus(executor,"改变之后");
}
/**
* 打印线程池状态
*
* @param executor
* @param name
*/
private static void threadPoolStatus(ThreadPoolExecutor executor, String name) {
BlockingQueue<Runnable> queue = executor.getQueue();
System.out.println(Thread.currentThread().getName() + "-" + name + "-:" +
"核心线程数:" + executor.getCorePoolSize() +
" 活动线程数:" + executor.getActiveCount() +
" 最大线程数:" + executor.getMaximumPoolSize() +
" 线程池活跃度:" +
divide(executor.getActiveCount(), executor.getMaximumPoolSize()) +
" 任务完成数:" + executor.getCompletedTaskCount() +
" 队列大小:" + (queue.size() + queue.remainingCapacity()) +
" 当前排队线程数:" + queue.size() +
" 队列剩余大小:" + queue.remainingCapacity() +
" 队列使用度:" + divide(queue.size(), queue.size() + queue.remainingCapacity()));
}
private static String divide(int num1, int num2) {
return String.format("%1.2f%%", Double.parseDouble(num1 + "") / Double.parseDouble(num2 + "") * 100);
}
}
当你把这个代码粘过去之后,你会发现你没有 NamedThreadFactory 这个类。
没有关系,我用的是 hutool 工具包里面的,你要是没有,可以自定义一个,也可以在构造函数里面不传,这不是重点,问题不大。
问题大的是 ResizeableCapacityLinkedBlockingQueue 这个玩意。
它是怎么来的呢?
在之前的文章里面提到过:
就是把 LinkedBlockingQueue 粘贴一份出来,修改个名字,然后把 Capacity 参数的 final 修饰符去掉,并提供其对应的 get/set 方法。
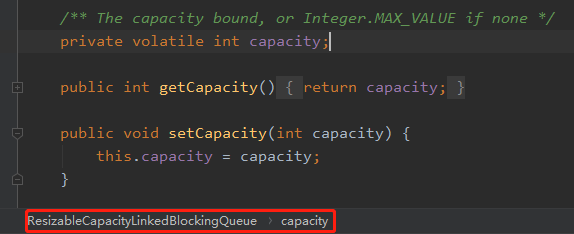
感觉非常的简单,就能实现 capacity 参数的动态变更。
但是,我当时写的时候就感觉是有坑的。
毕竟这么简单的话,为什么官方要把它给设计为 final 呢?

坑在哪里?
关于 LinkedBlockingQueue 的工作原理就不在这里说了,都是属于必背八股文的内容。
主要说一下前面提到的场景中,如果我直接把 final 修饰符去掉,并提供其对应的 get/set 方法,这样的做法坑在哪里。
先说一下,如果没有特殊说明,本文中的源码都是 JDK 8 版本。
我们看一下这个 put 方法:
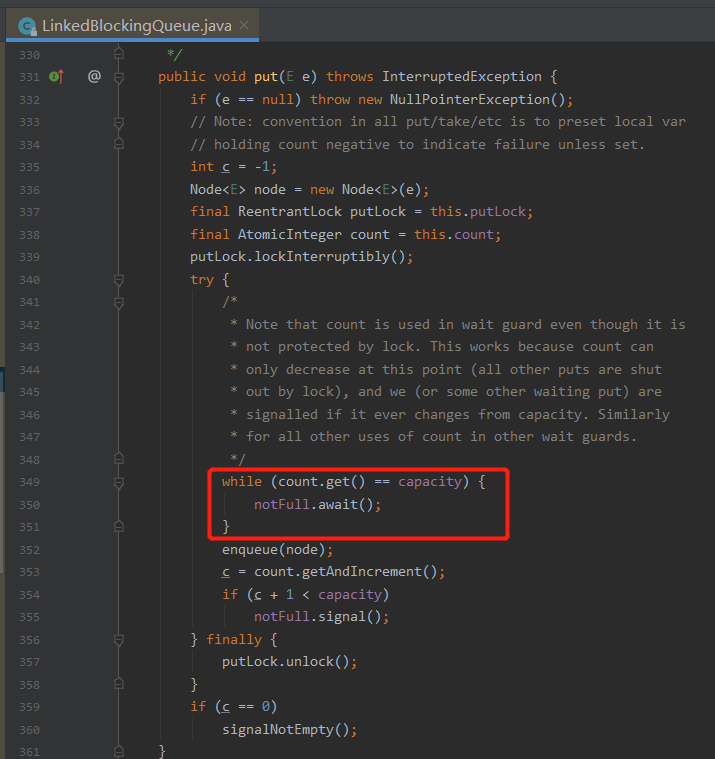
主要看这个被框起来的部分。
while 条件里面的 capacity 我们知道代表的是当前容量。
那么 count.get 是个什么玩意呢?

就是当前队列里面有多少个元素。
count.get == capacity 就是说队列已经满了,然后执行 notFull.await() 把当前的这个 put 操作挂起来。
来个简单的例子验证一下:
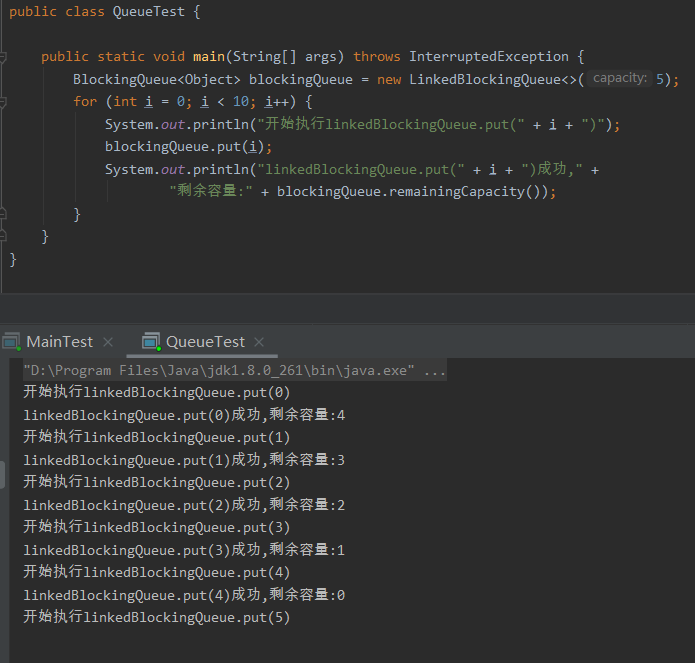
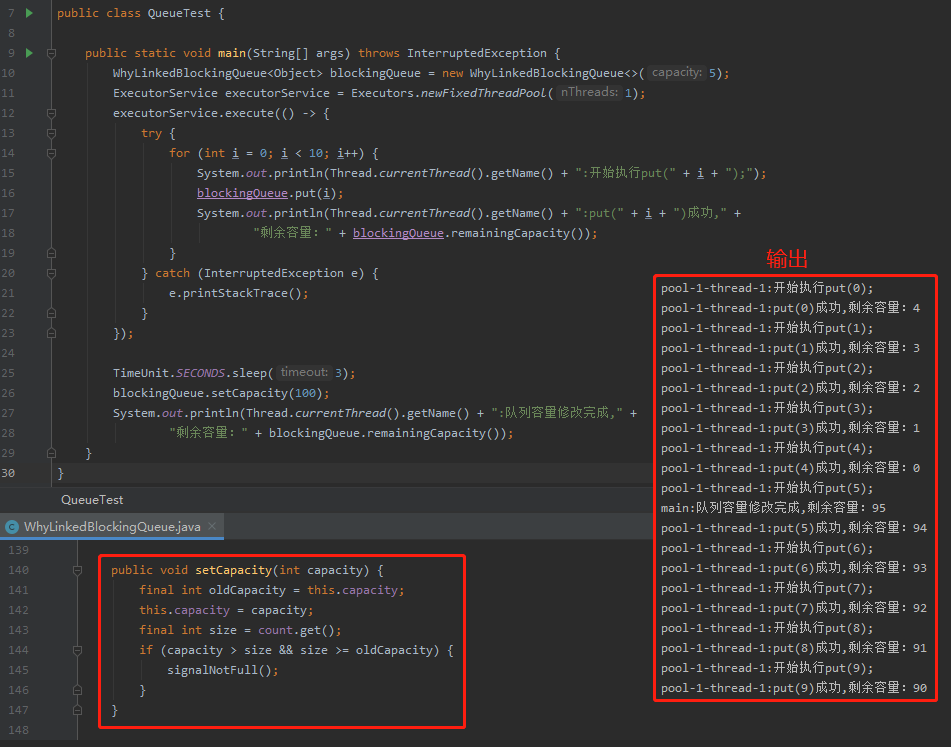
申请一个长度为 5 的队列,然后在循环里面调用 put 方法,当队列满了之后,程序就阻塞住了。
通过 dump 当前线程可以知道主线程确实是阻塞在了我们前面分析的地方:
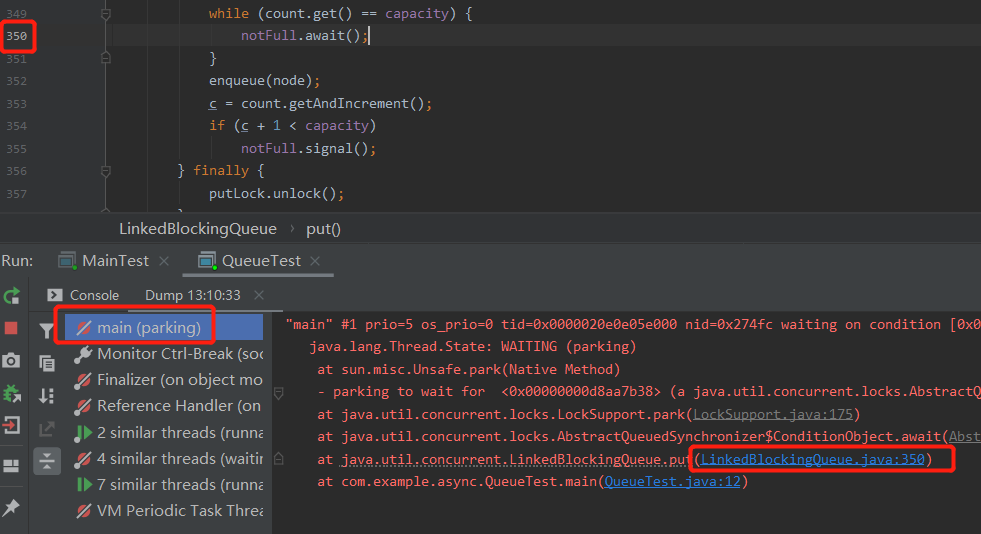
所以,你想想。如果我把队列的 capacity 修改为了另外的值,这地方会感知到吗?
它感知不到啊,它在等着别人唤醒呢。

现在我们把队列换成我修改后的队列验证一下。
下面验证程序的思路就是在一个子线程中执行队列的 put 操作,直到容量满了,被阻塞。
然后主线程把容量修改为 100。
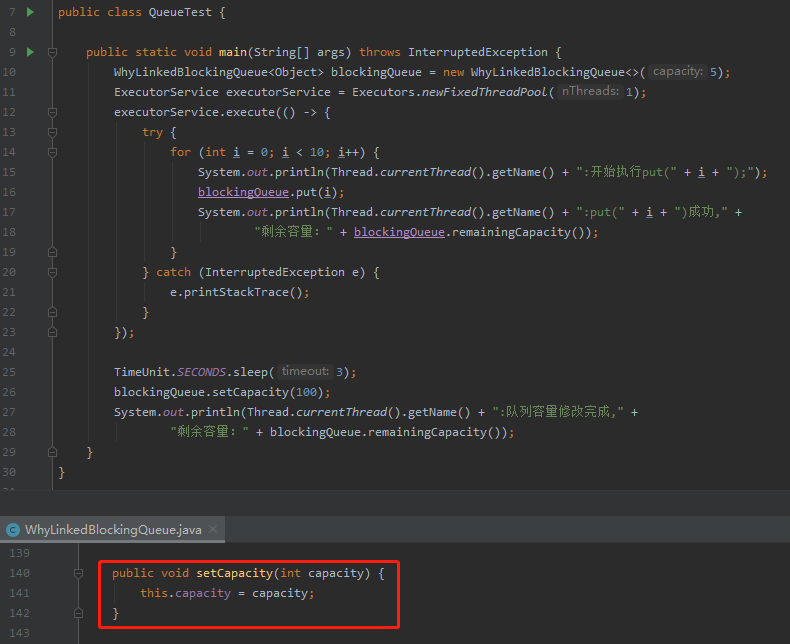
上面的程序其实我想要达到的效果是当容量扩大之后,子线程不应该继续阻塞。
但是经过前面的分析,我们知道这里并不会去唤醒子线程。
所以,输出结果是这样的:
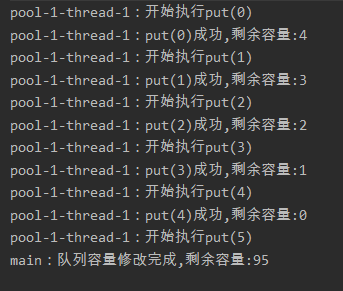
子线程还是阻塞着,所以并没有达到预期。
所以这个时候我们应该怎么办呢?
当然是去主动唤醒一下啦。
也就是修改一下 setCapacity 的逻辑:
public void setCapacity(int capacity) {
final int oldCapacity = this.capacity;
this.capacity = capacity;
final int size = count.get();
if (capacity > size && size >= oldCapacity) {
signalNotFull();
}
}
核心逻辑就是发现如果容量扩大了,那么就调用一下 signalNotFull 方法:

唤醒一下被 park 起来的线程。
如果看到这里你觉得你有点懵,不知道 LinkedBlockingQueue 的这几个玩意是干啥的:
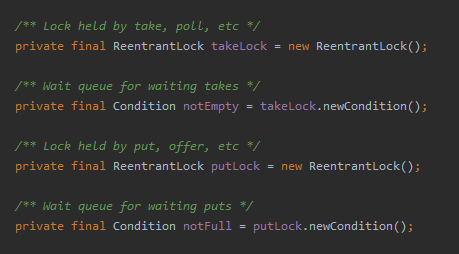
赶紧去花一小时时间补充一下 LinkedBlockingQueue 相关的知识点。这样玩意,面试也经常考的。
好了,我们说回来。
修改完我们自定义的 setCapacity 方法后,再次执行程序,就出现了我们预期的输出:
除了改 setCapacity 方法之外,我在写文章的时候不经意间还触发了另外一个答案:
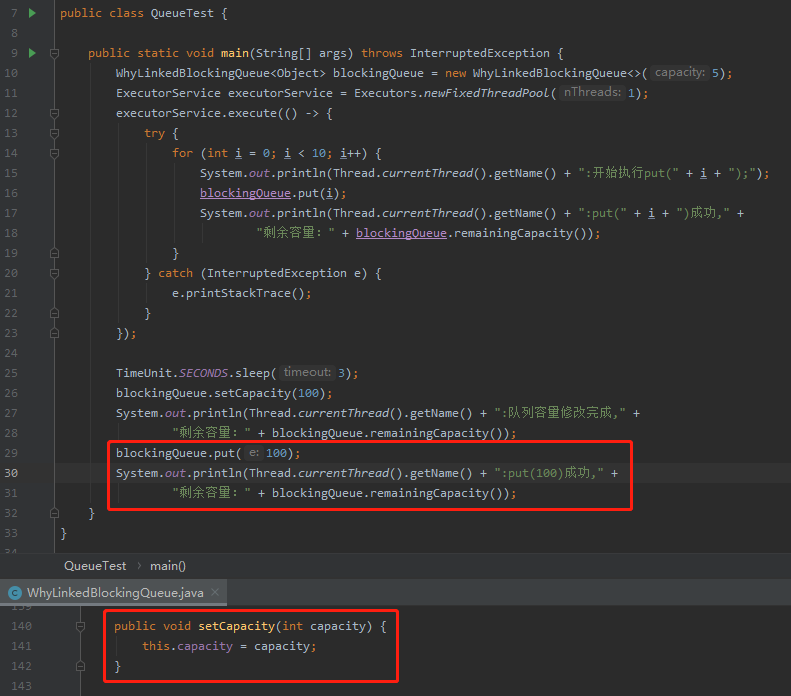
在调用完 setCapacity 方法之后,再次调用 put 方法,也能得到预期的输出:
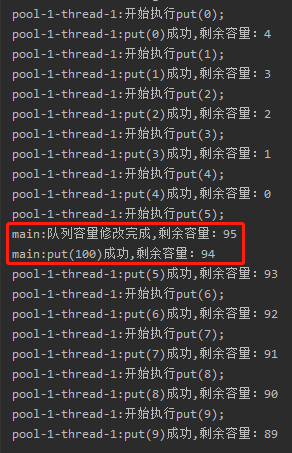
我们观察 put 方法就能发现其实道理是一样的:
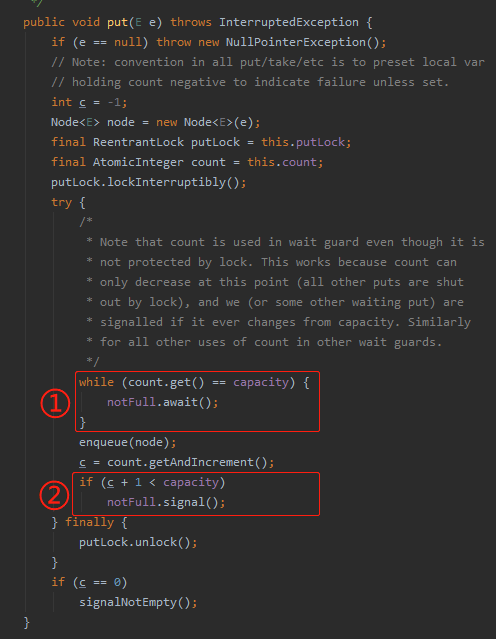
当调用完 setCapacity 方法之后,再次调用 put 方法,由于不满足标号为 ① 的代码的条件,所以就不会被阻塞。
于是可以顺利走到标号为 ② 的地方唤醒被阻塞的线程。
所以也就变相的达到了改变队列长度,唤醒被阻塞的任务目的。
而究根结底,就是需要执行一次唤醒的操作。
那么那一种优雅一点呢?
那肯定是第一种把逻辑封装在 setCapacity 方法里面操作起来更加优雅。
第二种方式,大多适用于那种“你也不知道为什么,反正这样写程序就是正常了”的情况。

现在我们知道在线程池里面动态调整队列长度的坑是什么了。
那就是队列满了之后,调用 put 方法的线程就会被阻塞住,即使此时另外的线程调用了 setCapacity 方法,改变了队列长度,如果没有线程再次触发 put 操作,被阻塞的线程也不会被唤醒。
是不是?
了不了解?
对不对?
这是不对的,朋友们。

看到前面内容,频频点头的朋友,要注意了。
这地方要开始转弯了。
开始转弯
线程池里面往队列里面添加对象的时候,用的是 offer 命令,并没有用 put 命令:
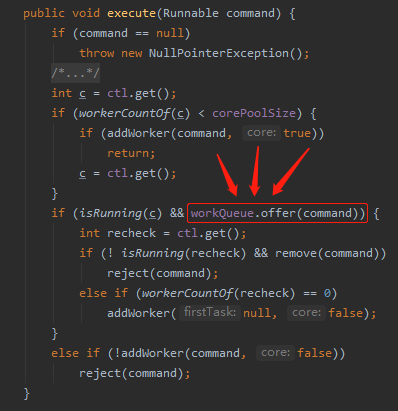
我们看看 offer 命令在干啥事儿:
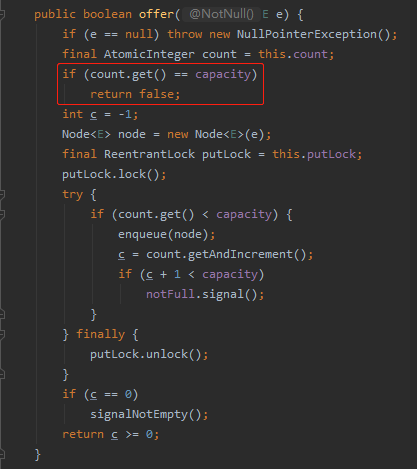
队列满了之后,直接返回 false,不会出现阻塞的情况。
也就是说,线程池中根本就不会出现我前面说的需要唤醒的情况,因为根本就没有阻塞中的线程。
在和大佬交流的过程中,他提到了一个 VariableLinkedBlockingQueue 的东西。
这个类位于 MQ 包里面,我前面提到的 setCapacity 方法的修改方式就是在它这里学来的:
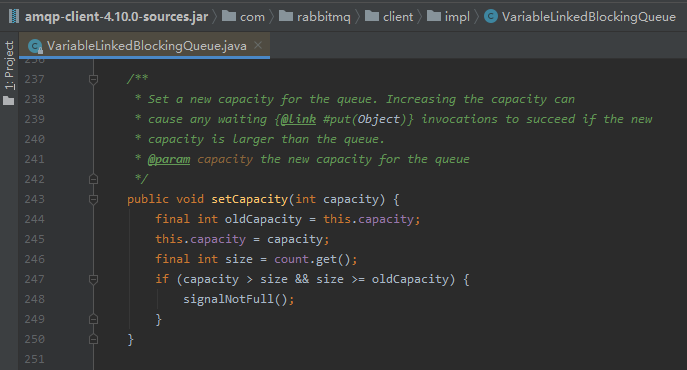
同时,项目里面也用到了它的 put 方法:
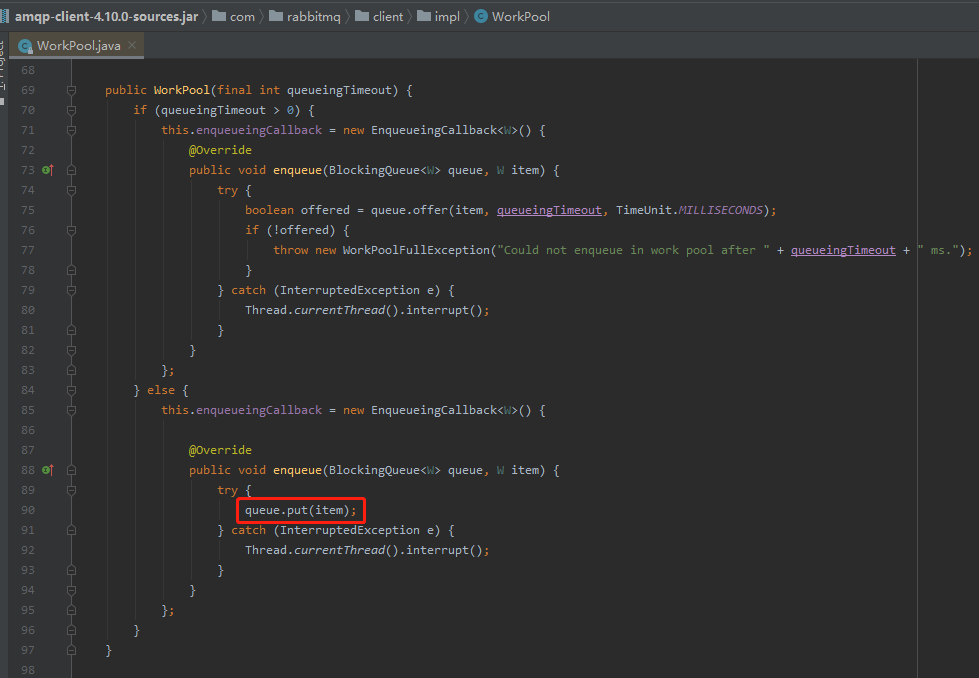
所以,它是有可能出现我们前面分析的情况,有需要被唤醒的线程。
但是,你想想,线程池里面并没有使用 put 方法,是不是就刚好避免这样的情况?
是的,确实是。
但是,不够严谨,如果知道有问题了的话,为什么要留个坑在这里呢?
你学 MQ 的 VariableLinkedBlockingQueue 考虑的周全一点,就算 put 方法阻塞的时候也能用,它不香吗?
写到这里其实好像除了让你熟悉一下 LinkedBlockingQueue 外,似乎是一个没啥卵用的知识点,
但是,我能让这个没有卵用的知识点起到大作用。
因为这其实是一个小细节。
假设我出去面试,在面试的时候提到动态调整方法的时候,在不经意间拿捏一下这个小细节,即使我没有真的落地过动态调整,但是我提到这样的一个小细节,就显得很真实。
面试官一听:很不错,有整体,有局部,应该是假不了。

在 VariableLinkedBlockingQueue 里面还有几处细节,拿 put 方法来说:
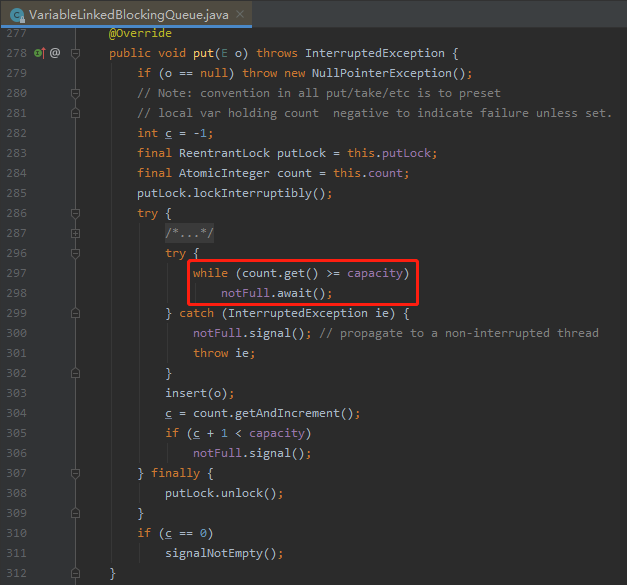
判断条件从 count.get() >= capacity 变成了 count.get() = capacity,目的是为了支持 capacity 由大变小的场景。
这样的地方还有好几处,就不一一列举了。
魔鬼,都在细节里面。
同学们得好好的拿捏一下。
JDK bug
其实原计划写到前面,就打算收尾了,因为我本来就只是想补充一下我之前没有注意到的细节。
但是,我手贱,跑到 JDK bug 列表里面去搜索了一下 LinkedBlockingQueue,想看看还有没有什么其他的收获。
我是万万没想到,确实是有一点意外收获的。
首先是这一个 bug ,它是在 2019-12-29 被提出来的:
https://bugs.openjdk.java.net/browse/JDK-8236580
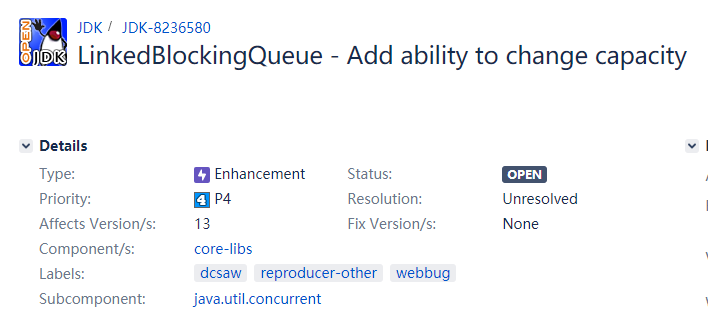
看标题的意思也是想要给 LinkedBlockingQueue 赋能,可以让它的容量进行修改。
加上他下面的场景描述,应该也想要和线程池配合,找到队列的抓手,下钻到底层逻辑,联动监控系统,拉通配置页面,打出一套动态适应的组合拳。

但是官方并没有采纳这个建议。

回复里面说写 concurrent 包的这些哥们对于在并发类里面加东西是非常谨慎的。他们觉得给 ThreadPoolExecutor 提供可动态修改的特性会带来或者已经带来众多的 bug 了。
我理解就是简单一句话:建议还是不错的,但是我不敢动。并发这块,牵一发动全身,不知道会出些什么幺蛾子。
所以要实现这个功能,还是得自己想办法。
这里也就解释了为什么用 final 去修饰了队列的容量,毕竟把功能缩减一下,出现 bug 的几率也少了很多。

第二个 bug 就有意思了,和我们动态调整线程池的需求非常匹配:
https://bugs.openjdk.java.net/browse/JDK-8241094
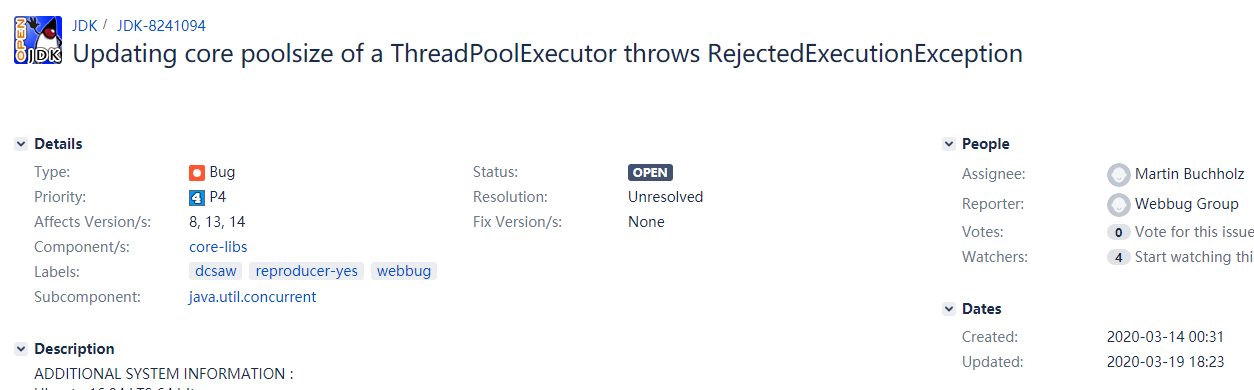
这是一个 2020 年 3 月份提出的 bug,描述的是说在更新线程池的核心线程数的时候,会抛出一个拒绝异常。
在 bug 描述的那部分他贴了很多代码,但是他给的代码写的很复杂,不太好理解。
好在 Martin 大佬写了一个简化版,一目了然,就好理解的多:
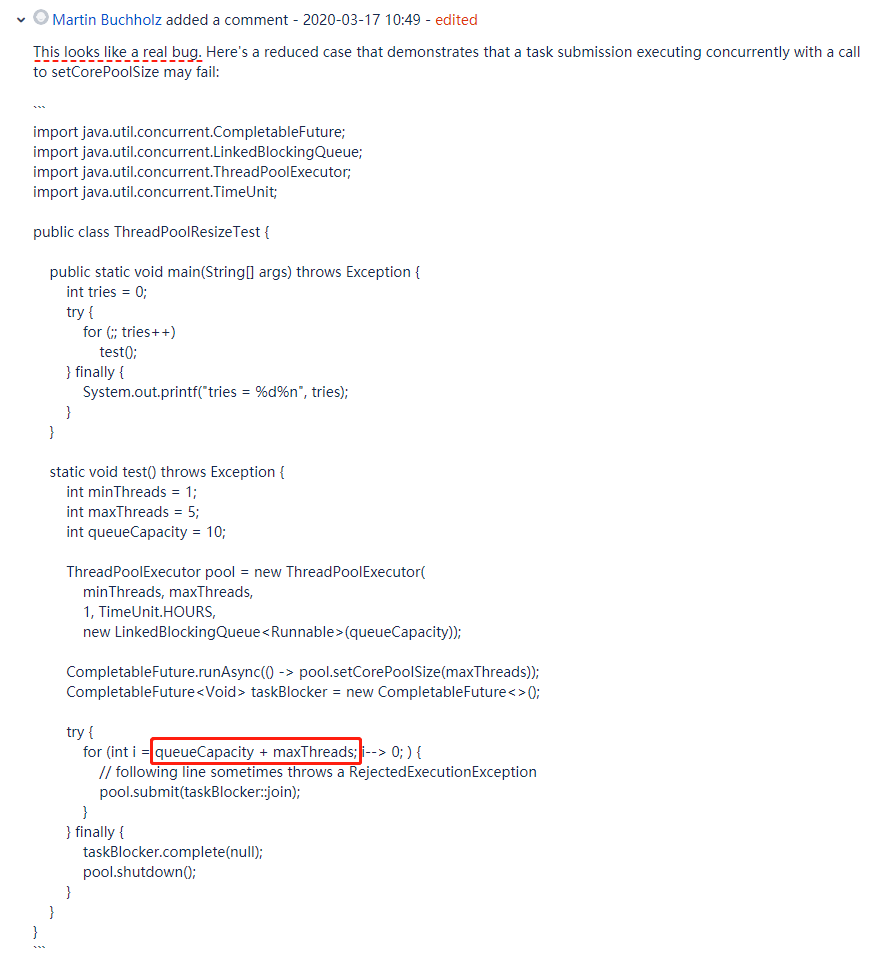
这段代码是干了个啥事儿呢,简单给大家汇报一下。
首先 main 方法里面有个循环,循环里面是调用了 test 方法,当 test 方法抛出异常的时候循环结束。
然后 test 方法里面是每次都搞一个新的线程池,接着往线程池里面提交队列长度加最大线程数个任务,最后关闭这个线程池。
同时还有另外一个线程把线程池的核心线程数从 1 修改为 5。
你可以打开前面提到的 bug 链接,把这段代码贴出来跑一下,非常的匪夷所思。
Martin 大佬他也认为这是一个 BUG.
说实在的,我跑了一下案例,我觉得这应该算是一个 bug,但是经过 Doug Lea 老爷子的亲自认证,他并不觉得这是一个 Bug。
主要是这个 bug 确实也有点超出我的认知,而且在链接中并没有明确的说具体原因是什么,导致我定位的时间非常的长,甚至一度想要放弃。
但是最终定位到问题之后也是长叹一口:害,就这?没啥意思。
先看一下问题的表现是怎么样的:
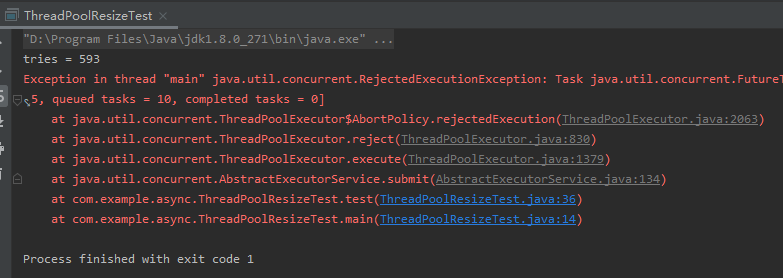
上面的程序运行起来后,会抛出 RejectedExecutionException,也就是线程池拒绝执行该任务。
但是我们前面分析了,for 循环的次数是线程池刚好能容纳的任务数:
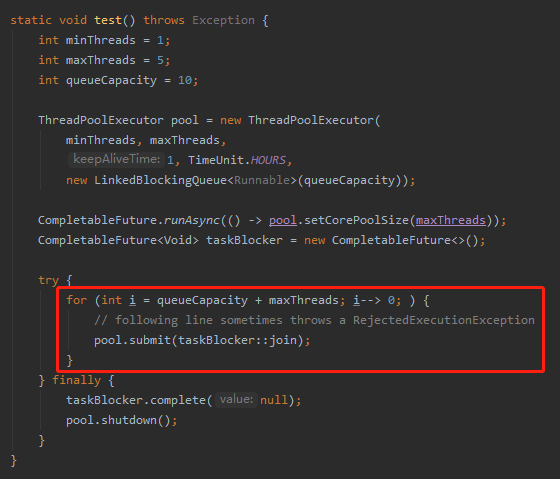
按理来说不应该有问题啊?
这也就是提问的哥们纳闷的地方:

他说:我很费解啊,我提交的任务数量根本就不会超过 queueCapacity+maxThreads,为什么线程池还抛出了一个 RejectedExecutionException?而且这个问题非常的难以调试,因为在任务中添加任何形式的延迟,这个问题都不会复现。
他的言外之意就是:这个问题非常的莫名其妙,但是我可以稳定复现,只是每次复现出现问题的时机都非常的随机,我搞不定了,我觉得是一个 bug,你们帮忙看看吧。
我先不说我定位到的 Bug 的主要原因是啥吧。
先看看老爷子是怎么说的:

老爷子的观点简单来说就是四个字:

老爷子说他没有说服自己上面的这段程序应该被正常运行成功。
意思就是他觉得抛出异常也是正常的事情。但是他没有说为什么。
一天之后,他又补了一句话:

我先给大家翻译一下:
他说当线程池的 submit 方法和 setCorePoolSize 或者 prestartAllCoreThreads 同时存在,且在不同的线程中运行的时候,它们之间会有竞争的关系。
在新线程处于预启动但还没完全就绪接受队列中的任务的时候,会有一个短暂的窗口。在这个窗口中队列还是处于满的状态。
解决方案其实也很简单,比如可以在 setCorePoolSize 方法中把预启动线程的逻辑拿掉,但是如果是用 prestartAllCoreThreads 方法,那么还是会出现前面的问题。
但是,不管是什么情况吧,我还是不确定这是一个需要被修复的问题。
怎么样,老爷子的话看起来是不是很懵?
是的,这段话我最开始的时候读了 10 遍,都是懵的,但是当我理解到这个问题出现的原因之后,我还是不得不感叹一句:
还是老爷子总结到位,没有一句废话。
到底啥原因?
首先我们看一下示例代码里面操作线程池的这两个地方:
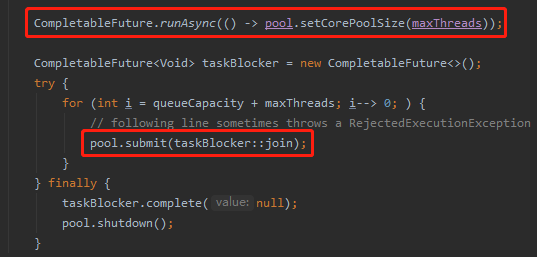
修改核心线程数的是一个线程,即 CompletableFuture 的默认线程池 ForkJoinPool 中的一个线程。
往线程池里面提交任务是另外一个线程,即主线程。
老爷子的第一句话,说的就是这回事:

racing,就是开车,就是开快车,就是与...比赛的意思。
这是一个多线程的场景,主线程和 ForkJoinPool 中的线程正在 race,即可能出现谁先谁后的问题。
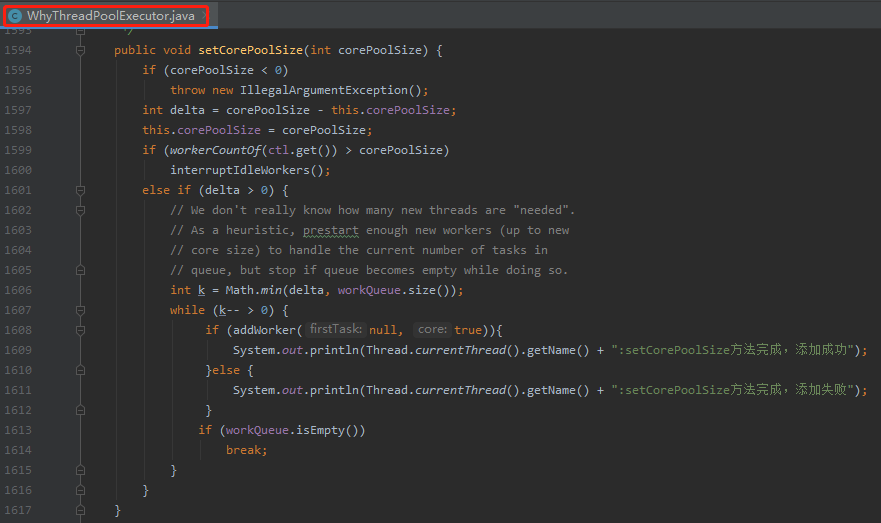
接着我们看看 setCorePoolSize 方法干了啥事:
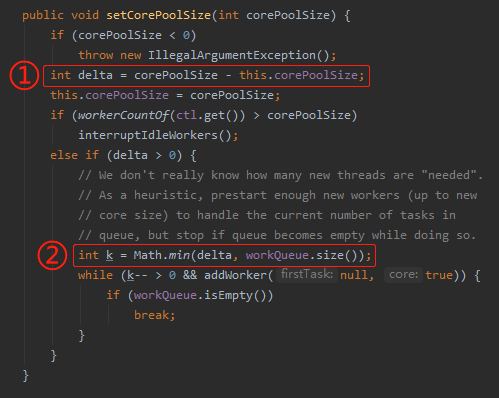
标号为 ① 的地方是计算新设置的核心线程数与原核心线程数之间的差值。
得出的差值,在标号为 ② 的地方进行使用。
也就是取差值和当前队列中正在排队的任务数中小的那一个。
比如当前的核心线程数配置就是 2,这个时候我要把它修改为 5。队列里面有 10 个任务在排队。
那么差值就是 5-2=3,即标号为 ① 处的 delta=3。
workQueue.size 就是正在排队的那 10 个任务。
也就是 Math.min(3,10),所以标号为 ② 处的 k=3。
含义为需要新增 3 个核心线程数,去帮忙把排队的任务给处理一下。
但是,你想新增 3 个就一定是对的吗?
会不会在新增的过程中,队列中的任务已经被处理完了,有可能根本就不需要 3 个这么多了?
所以,循环终止的条件除了老老实实的循环 k 次外,还有什么?
就是队列为空的时候:
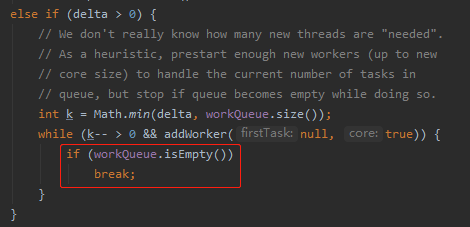
同时,你去看代码上面的那一大段注释,你就知道,其实它描述的和我是一回事。
好,我们接着看 addWorker 里面,我想要让你看到地方:

在这个方法里面经过一系列判断后,会走入到 new Worker() 的逻辑,即工作线程。
然后把这个线程加入到 workers 里面。
workers 就是一个存放工作线程的 HashSet 集合:
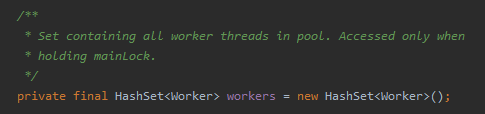
你看我框起来的这两局代码,从 workers.add(w) 到 t.start()。
从加入到集合到真正的启动,中间还有一些逻辑。
执行中间的逻辑的这一小段时间,就是老爷子说的 “window”。
there's a window while new threads are in the process of being prestarted but not yet taking tasks。
就是在新线程处于预启动,但尚未接受任务时,会有一个窗口。
这个窗口会发生啥事儿呢?
就是下面这句话:
the queue may remain (transiently) full。
队列有可能还是满的,但是只是暂时的。
接下来我们连起来看:

所以怎么理解上面被划线的这句话呢?
带入一个实际的场景,也就是前面的示例代码,只是调整一下参数:

这个线程池核心线程数是 1,最大线程数是 2,队列长度是 5,最多能容纳的任务数是 7。
另外有一个线程在执行把核心线程池从 1 修改为 2 的操作。
假设我们记线程池 submit 提交了 6 个任务,正在提交第 7 个任务的时间点为 T1。
为什么是要强调这个时间点呢?
因为当提交第 7 个任务的时候,就需要去启用非核心线程数了。
具体的源码在这里:
java.util.concurrent.ThreadPoolExecutor#execute
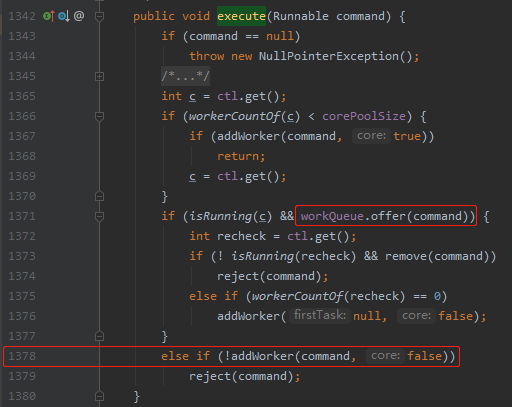
也就是说此时队列满了, workQueue.offer(command) 返回的是 fasle。因此要走到 addWorker(command, false) 方法中去了。
代码走到 1378 行这个时间点,是 T1。
如果 1378 行的 addWorker 方法返回 false,说明添加工作线程失败,抛出拒绝异常。
前面示例程序抛出拒绝异常就是因为这里返回了 fasle。
那么问题就变成了:为什么 1378 行中的 addWorker 执行后返回了 false 呢?
因为当前不满足这个条件了 wc >= (core ? corePoolSize : maximumPoolSize):
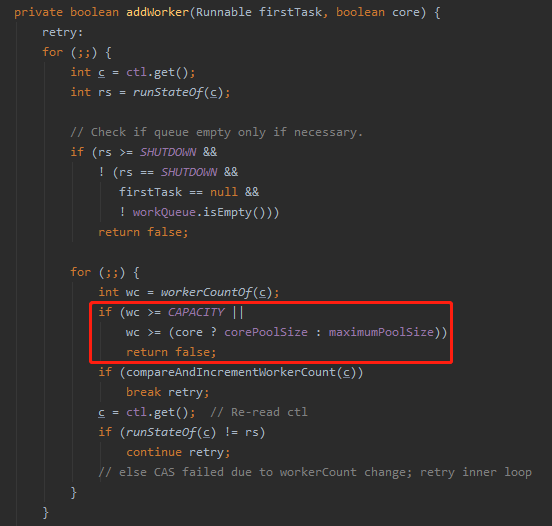
wc 就是当前线程池,正在工作的线程数。
把我们前面的条件带进去,就是这样的 wc >=(false?2:2)。
即 wc=2。
为什么会等于 2,不应该是 1 吗?
多的哪一个是哪里来的呢?
真相只有一个:恰好此时 setCorePoolSize 方法中的 addWorker 也执行到了 workers.add(w),导致 wc 从 1 变成了 2。
撞车了,所以抛出拒绝异常。
那么为什么大多数情况下不会抛出异常呢?
因为从 workers.add(w) 到 t.start()这个时间窗口,非常的短暂。
大多数情况下,setCorePoolSize 方法中的 addWorker 执行了后,就会理解从队列里面拿一个任务出来执行。
而这个情况下,另外的任务通过线程池提交进来后,发现队列还有位子,就放到队列里面去了,根本不会去执行 addWorker 方法。
道理,就是这样一个道理。
这个多线程问题确实是比较难复现,我是怎么定位到的呢?
加日志。
源码里面怎么加日志呢?
我不仅搞了一个自定义队列,还把线程池的源码粘出来了一份,这样就可以加日志了:
另外,其实我这个定位方案也是很不严谨的。
调试多线程的时候,最好是不要使用 System.out.println,有坑!
场景
我们再回头看看老爷子给出的方案:

其实它给了两个。
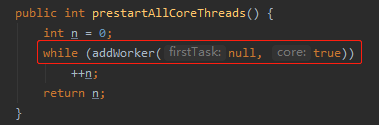
第一个是拿掉 setCorePoolSize 方法中的 addworker 的逻辑。
第二个是说原程序中,即提问者给的程序中,使用的是 prestartAllCoreThreads 方法,这个里面必须要调用 addWorker 方法,所以还是有一定的几率出现前面的问题。
但是,老爷子不明白为什么会这样写?
我想也许他是没有想到什么合适的场景?
其实前面提到的这个 Bug,其实在动态调整的这个场景下,还是有可能会出现的。
虽然,出现的概率非常低,条件也非常苛刻。
但是,还是有几率出现的。
万一出现了,当同事都在抠脑壳的时候,你就说:这个嘛,我见过,是个 Bug。不一定每次都出现的。
这又是一个你可以拿捏的小细节。
但是,如果你在面试的时候遇到这个问题了,这属于一个傻逼问题。
毫无意义。
属于,面试官不知道在哪看到了一个感觉很厉害的观点,一定要展现出自己很厉害的样子。
但是他不知道的是,这个题:

最后说一句
好了,看到了这里了,安排一个点赞吧。写文章很累的,需要一点正反馈。
给各位读者朋友们磕一个了:

本文已收录自个人博客,欢迎大家来玩:
https://www.whywhy.vip/