1.下载
https://github.com/ARM-software/ComputeLibrary
2.由于我交叉编译器已经加入环境变量,修改SConstruct文件下
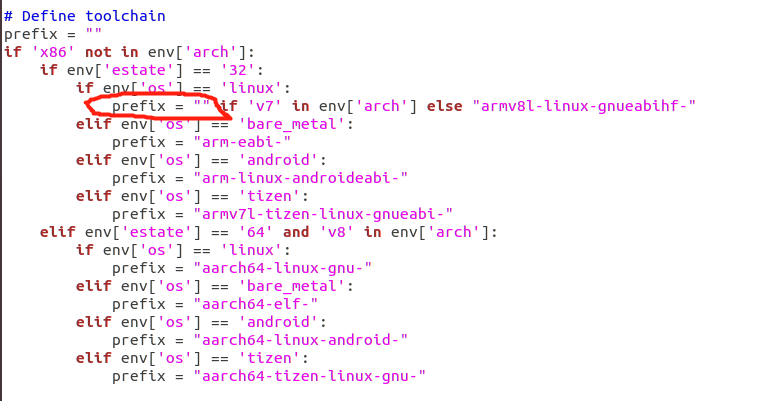
3.编译
opencl一起编译进去 embed_kernels=1
scons Werror=0 debug=0 asserts=1 neon=1 opencl=1 embed_kernels=1 os=linux arch=armv7a
如果只用到neon加速
scons Werror=0 debug=0 asserts=0 neon=1 opencl=1 os=linux arch=armv7a
debug和asserts用于调试,会增加运行时间;
4.链接
编译成功后会在根目录下生成build文件夹,我只用到下面两个so文件。
文件夹
#include "arm_compute/core/Types.h" #include "tests/Utils.h" #include "arm_compute/runtime/NEON/NEScheduler.h" #include "arm_compute/runtime/NEON/functions/NEGEMM.h"
5.运行,矩阵乘法
neon加速
TensorShape AShape(K,M); TensorShape BShape(N,K); TensorShape OShape(N,M); Tensor ATensor, BTensor, OTensor , CTensor; ATensor.allocator()->init(TensorInfo(AShape, Format::F32)); BTensor.allocator()->init(TensorInfo(BShape, Format::F32)); OTensor.allocator()->init(TensorInfo(OShape, Format::F32)); NEGEMM armGemm; armGemm.configure(&ATensor, &BTensor,nullptr, &OTensor,ALPHA, 0.0); ATensor.allocator()->allocate(); BTensor.allocator()->allocate(); OTensor.allocator()->allocate(); Window A_window; A_window.use_tensor_dimensions(ATensor.info()->tensor_shape()); Iterator A_it(&ATensor, A_window); execute_window_loop(A_window, [&](const Coordinates & id) { *reinterpret_cast<float *>(A_it.ptr()) = A[id.z() * (M * K) + id.y() * K + id.x()]; }, A_it); Window B_window; B_window.use_tensor_dimensions(BTensor.info()->tensor_shape()); Iterator B_it(&BTensor, B_window); execute_window_loop(B_window, [&](const Coordinates & id) { *reinterpret_cast<float *>(B_it.ptr()) = B[id.z() * (K * N) + id.y() * N + id.x()]; }, B_it); //warmup run armGemm.run(); for(int h = 0; h < M; h++) { for(int w = 0; w < N; w++) { C[h*N + w] = *reinterpret_cast<float*>( OTensor.buffer() + OTensor.info()->offset_element_in_bytes(Coordinates(w,h,0))); } }
opencl加速需要opencl2.0以上或者支持-cl-arm-non-uniform-work-group-size