1. 区别 == 和 ===
== 比较的是两个变量的值
=== 比较两个变量的 类型 和 值
基本数据类型(undefined,boolean,number,string,null)
存放在栈内存中的简单数据段,数据大小确定,内存空间大小可以分配,是直接按值存放的,所以可以直接访问。
基本数据类型的比较是值的比较
引用数据类型(object)
放在堆中,其引用就是内存地址
引用类型的比较是引用的比较
2. 浅拷贝 和 深拷贝
(拿一个对象来说,当然也可以是数组。非基本类型的拷贝,才会有深拷贝、浅拷贝的区别)
- 只要不是层层拷贝,就是浅拷贝(Shallow Copy 老变量的改变,影响到了新的变量)。分为
(1)仅仅拷贝变量(变量的赋值)
- 这样的简单复制,拷贝的就是对象的引用,即拷贝了对象在内存空间中的地址,在内存中始终只有一个对象
-
var obj1 = { 'name' : 'zhangsan', 'age' : '18', 'arr' : [1,[2,3],[4,5]], }; var obj2 = obj1;
(2)一层拷贝
-
function shallowCopy(src) { // 一层浅拷贝 var dst = {}; for (var prop in src) { if (src.hasOwnProperty(prop)) { dst[prop] = src[prop]; } } return dst; } /**** test ****/ var obj = { a:1, arr: [2,3] }; var shallowObj = shallowCopy(obj);
造成的坏处就是:obj.arr[0] = 0; console.log(shallowObj.arr[0]); // obj 的里 arr 的改变,会影响到 shallowObj.arr
- 数组的 slice()、concat() 也是浅拷贝
- 对象的 Object.assign() 也是浅拷贝
-
let a = { name: "muyiy", book: { title: "You Don't Know JS", price: "45" } } let b = Object.assign({}, a); // 将所有可枚举属性的值从一个或多个源对象复制到目标对象。它将返回目标对象 a.name = "change"; a.book.price = "55"; console.log(a.name, ' ---- ', b.name); // 第一层的基础类型不会互相影响 console.log(a.book, ' ---- ', b.book); // 但是第一层的复杂数据类型,即第二层 互相影响了
- 扩展运算符的拷贝 也是浅拷贝
-
let a = { name: "muyiy", book: { title: "You Don't Know JS", price: "45" } } let b = {...a};// 将所有可枚举属性展开,放到一个新对象中 a.name = "change"; a.book.price = "55"; console.log(a, ' ---- ', b); console.log(a.book, ' ---- ', b.book);
会发现 和 Object.assign() 的效果一模一样。只是实现了第一层的拷贝,第二层更深层 会互相影响
- 深拷贝是层层拷贝(老变量与新变量,互不影响)
完全改变变量 a 之后对 b 没有任何影响,这就是深拷贝的魔力
(1)const b = JSON.parse(JSON.stringify(a));
原理:
- 利用 JSON.stringify() 将 原始数据 转换成 字符串(string 是基本数据类型存放在栈)
- 然后用 JSON.parse() 解析字符串为一个对象(这时会在内存中新建一个对象)
缺点:
- 对于undefined、symbol 和函数 这三种情况,会直接忽略
- 不能解决循环引用的对象(循环引用: 就是一个对象 有一个属性,这个属性 等于这个对象)
-
let obj = { a: 1, b: { c: 2, d: 3 } } obj.a = obj.b; obj.b.c = obj.a; let b = JSON.parse(JSON.stringify(obj)); // Uncaught TypeError: Converting circular structure to JSON
- 不能正确处理new Date()
-
// 木易杨 new Date(); // Mon Dec 24 2018 10:59:14 GMT+0800 (China Standard Time) JSON.stringify(new Date()); // ""2018-12-24T02:59:25.776Z"" JSON.parse(JSON.stringify(new Date())); // "2018-12-24T02:59:41.523Z"
解决方法转成字符串或者时间戳就好了。
// 木易杨 let date = (new Date()).valueOf(); // 1545620645915 JSON.stringify(date); // "1545620673267" JSON.parse(JSON.stringify(date)); // 1545620658688
- 不能处理正则
-
// 木易杨 let obj = { name: "muyiy", a: /'123'/ } console.log(obj); // {name: "muyiy", a: /'123'/} let b = JSON.parse(JSON.stringify(obj)); console.log(b); // {name: "muyiy", a: {}}
(2)三方库 jQuery.extend().
(3)原生三方库 lodash.cloneDeep()
-
var objects = [{ 'a': 1 }, { 'b': 2 }]; var deep = _.cloneDeep(objects); console.log(deep[0] === objects[0]); // => false
(4)自己写 思路就是递归调用刚刚的浅拷贝,把所有属于对象的属性类型 都遍历赋给另一个对象即可
-
// 内部方法:用户合并一个或多个对象到第一个对象 // 参数: // target 目标对象 对象都合并到target里 // source 合并对象 // deep 是否执行深度合并 function extend(target, source, deep) { for (key in source) if (deep && (isPlainObject(source[key]) || isArray(source[key]))) { // source[key] 是对象,而 target[key] 不是对象, 则 target[key] = {} 初始化一下,否则递归会出错的 if (isPlainObject(source[key]) && !isPlainObject(target[key])) target[key] = {} // source[key] 是数组,而 target[key] 不是数组,则 target[key] = [] 初始化一下,否则递归会出错的 if (isArray(source[key]) && !isArray(target[key])) target[key] = [] // 执行递归 extend(target[key], source[key], deep) } // 不满足以上条件,说明 source[key] 是一般的值类型,直接赋值给 target 就是了 else if (source[key] !== undefined) target[key] = source[key] } // Copy all but undefined properties from one or more // objects to the `target` object. $.extend = function(target){ var deep, args = slice.call(arguments, 1); //第一个参数为boolean值时,表示是否深度合并 if (typeof target == 'boolean') { deep = target; //target取第二个参数 target = args.shift() } // 遍历后面的参数,都合并到target上 args.forEach(function(arg){ extend(target, arg, deep) }) return target }
以上是 Zepto 中深拷贝的代码
3. 如何合并两个对象
- 利用扩展运算符(浅拷贝第一层)
-
const obj1 = {a: 0, b: 1, c: 2}; const obj2 = {c: 3, d: 4, e: 5}; const obj = {...obj1, ...obj2}; // obj => {a: 0, b: 1, c: 3, d: 4, e: 5} - for in 遍历对象 一步一步手写一个深拷贝(参考: https://juejin.im/post/5d6aa4f96fb9a06b112ad5b1#heading-3)
- 第一步,写一个浅拷贝
-
// 创建一个新的对象,遍历需要克隆的对象,将需要克隆对象的属性依次添加到新对象上,返回
function clone(target) { let cloneTarget = {}; for (const key in target) { cloneTarget[key] = target[key]; } return cloneTarget; }; - 第二步,如果是深拷贝的话,考虑到我们要拷贝的对象是不知道有多少层深度的,我们可以用递归来解决问题,稍微改写上面的代码
-
function clone(target) { if (typeof target === 'object') { // 只考虑了普通的 object let cloneTarget = {}; for (const key in target) { cloneTarget[key] = clone(target[key]); } return cloneTarget; } else { return target; } };
- 测试下上述代码
-
const oldObject = { field1: 1, field2: undefined, field3: 'ConardLi', field4: { child: 'child', child2: { child2: 'child2' } } }; const newObject = clone(oldObject); console.log(newObject);
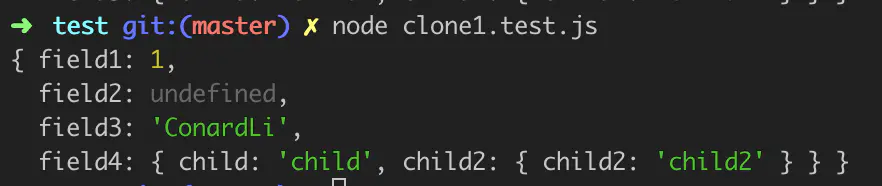
这个基础版本,还有很多不足,比如,还没有考虑数组
- 第三步,上面只考虑了普通的 object,下面我们只需要把初始化代码稍微一变,就可以兼容数组了
-
module.exports = function clone(target) { if (typeof target === 'object') { let cloneTarget = Array.isArray(target) ? [] : {}; for (const key in target) { cloneTarget[key] = clone(target[key]); } return cloneTarget; } else { return target; } }; /**** test ****/ const oldOne = { field1: 1, field2: undefined, field3: { child: 'child' }, field4: [2, 4, 8] }; const newOne = clone(oldOne); console.log(newOne);

- 第四步,上面的代码还存在一个循环引用的问题,我们解决它(循环引用: 对象的属性间接或直接的引用了自身的情况)
解决循环引用问题:
我们可以额外开辟一个存储空间,来存储当前对象和拷贝对象的对应关系
当需要拷贝当前对象时,先去存储空间中找,有没有拷贝过这个对象,如果有的话直接返回,如果没有的话继续拷贝
这样就巧妙化解的循环引用的问题
这个存储空间,需要可以存储 key-value 形式的数据,且 key 可以是一个引用类型,我们可以选择 Map 这种数据结构
- 检查
map中有无克隆过的对象 - 有 - 直接返回
- 没有 - 将当前对象作为
key,克隆对象作为value进行存储 - 继续克隆
-
function clone(target, map = new Map()) { if (typeof target === 'object') { let cloneTarget = Array.isArray(target) ? [] : {}; if (map.get(target)) { return map.get(target); } map.set(target, cloneTarget); for (const key in target) { cloneTarget[key] = clone(target[key], map); } return cloneTarget; } else { return target; } };
- 第五步,接下来,我们可以使用,WeakMap 替代 Map来使代码达到画龙点睛的作用
WeakMap 对象是一组键/值对的集合,其中的键是弱引用的。其键必须是对象,而值可以是任意的。
什么是弱引用呢?
在计算机程序设计中,弱引用与强引用相对,是指不能确保其引用的对象不会被垃圾回收器回收的引用。
一个对象若只被弱引用所引用,则被认为是不可访问(或弱可访问)的,并因此可能在任何时刻被回收。
- 我们默认创建一个对象:const obj = {},就默认创建了一个强引用的对象,
- 我们只有手动将obj = null,它才会被垃圾回收机制进行回收
- 如果是弱引用对象,垃圾回收机制会自动帮我们回收。
- 还有的优化就是 for、while、for in 中 while 的效率是最好的
-
如何写出一个惊艳面试官的深拷贝?
4. 改变对象的一个属性
例如 const a = {index: 1, name: 'kjf'};
需要把 index 改成 2
-
a = {...a, index: 2};
5. react 数据流 以及 vue 数据流
都是组件化编程
每个组件都有自己的 state 状态
react 的 state 发生变化 会触发重新 render 渲染组件
vue 的 state 发生变化 会尽量少的 页面渲染,先是在内存的虚拟dom 进行逻辑处理,然后批量的更新组件
6. 原型链
- 作用域链 找变量
- 原型链 对象找属性
每个函数都有一个 prototype 显示原型属性 ---- 原型对象
每个实例对象都有一个 __proto__ 隐式原型属性 ---- 指向其构造函数的原型对象
对象找属性时,会先在自身查找
如果没有 就沿着 __proto__属性一层一层的向上查找
直到查找到 Object.prototype.__proto__ === null 如果还没找到,就是 undefined
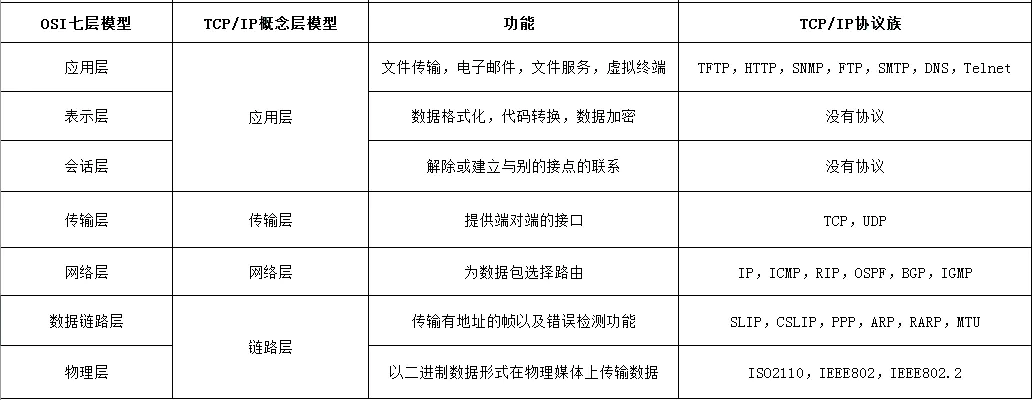
7. 计算机网络体系结构分几层、http 在哪一层
计算机网络体系结构分层: (有两种常见的模型)
- osi 7层模型
ing
- TCP/IP 五层概念层模型
应用层: HTTP、DNS、Telnet、FTP、SNMP、SMTP、TFTP
传输层: TCP/UDP
网络层: IP
数据链路层
物理层
8. 前后端联调 RESTful API,请求类型、作用以及区别
参考: https://www.cnblogs.com/tianxiaxuange/p/13324857.html
9. Object.defineProperty() 劫持属性的缺点,vue3 是如何解决的
参考: https://juejin.im/post/5bf3e632e51d452baa5f7375
- Object.defineProperty() 劫持属性的缺点:
- (1)Object.defineProperty 无法监控到数组下标的变化,导致直接通过数组的下标给数组设置值,不能实时响应
所以 vue 提供了 hack 处理过的八种方法 push()、pop()、shift()、unshift()、splice()、sort()、reverse()方法修改数组,可以触发渲染页面
this.$delete(target, propertyName/index) 避开 Vue 不能检测到 property 被删除的限制
this.$set( target, propertyName/index, value ) 向响应式对象中添加一个 property,并确保这个新 property 同样是响应式的,且触发视图更新
- vue3.0 采用了基于 Proxy 的观察者机制,消除了以前存在的警告,使速度加倍,并节省了一半的内存开销
- 用 Proxy 取代了 Object.defineProperty 这部分
- Proxy 是 es6 提供的新特性,兼容性不好,最主要的是这个属性无法用 polyfill 来兼容(目前 Proxy 并没有有效的兼容方案,所以 vue3.0 是大概会是3.0和2.0并行)
- babel 只负责语法转换,比如将ES6的语法转换成ES5。
- 但如果有些对象、方法,浏览器本身不支持,比如 Promise、WeakMap 等等,此时,需要引入 babel-polyfill 来模拟实现这些对象、方法
- Proxy 让我们能够以简洁易懂的方式控制外部对对象的访问。其功能非常类似于设计模式中的代理模式
- Proxy 可以理解成,Proxy 直接代理整个对象而非对象属性 ,在目标对象之前架设一层“拦截”,外界对该对象的访问,都必须先通过这层拦截,因此提供了一种机制,可以对外界的访问进行过滤和改写
- 正是因为这层拦截,可以劫持整个对象,并返回一个新对象
- Proxy 定义的 13种的trap/13种代理 操作方法:
- handler.get 获取对象的属性时拦截
- handler.set 设置对象的属性时拦截
- handler.has 拦截propName in proxy的操作,返回boolean
- handler.apply 拦截proxy实例作为函数调用的操作,proxy(args)、proxy.call(...)、proxy.apply(..)
- handler.construct 拦截proxy作为构造函数调用的操作
- handler.ownKeys 拦截获取proxy实例属性的操作,包括Object.getOwnPropertyNames、Object.getOwnPropertySymbols、Object.keys、for...in
- handler.deleteProperty 拦截delete proxy[propName]操作
- handler.defineProperty 拦截Objecet.defineProperty
- handler.isExtensible 拦截Object.isExtensible操作
- handler.preventExtensions 拦截Object.preventExtensions操作
- handler.getPrototypeOf 拦截Object.getPrototypeOf操作
- handler.setPrototypeOf 拦截Object.setPrototypeOf操作
- handler.getOwnPropertyDescriptor 拦截Object.getOwnPropertyDescriptor操作
Proxy代理目标对象,是通过操作上面的13种trap来完成的
-
// p 是代理后的对象。当外界每次对 p 进行操作时,就会执行 handler 对象上的一些方法 // target 是用Proxy包装的被代理对象(可以是任何类型的对象,包括原生数组,函数,甚至另一个代理) // handler 是一个对象,其声明了代理target 的一些操作,其属性是当执行一个操作时定义代理的行为的函数 // hander 是一个对象包含4个方法 { get:读取 set:修改 has:判断对象是否有该属性 construct:构造函数 } let p = new Proxy(target, handler);
let obj = {}; let handler = { get(target, property) { console.log(`${property} 被读取`); return property in target ? target[property] : 3; }, set(target, property, value) { console.log(`${property} 被设置为 ${value}`); target[property] = value; } } let p = new Proxy(obj, handler); p.name = 'tom' //name 被设置为 tom p.age; //age 被读取 3
10. 前后端分离 与 前后端不分离 的区别
- 前后端不分离:
- 优点:
- 动态展示的数据在页面的源代码中可以看见,有利于SEO优化推广(有利于搜索引擎的收录和抓取)
- 从服务器端获取的结果已经是解析渲染完成的了,不需要客户端再去解析渲染了,所以页面加载速度快(前提是服务器端处理的速度够快,能够处理过来)
所以类似于京东,淘宝这些网站,首屏数据一般都是由服务器端渲染的
- 缺点:
- 如果页面中存在实时更新的数据,每一次想要展示最新的数据,页面都要重新刷新一次,这样肯定不行,非常耗性能
- 都交给服务器端做数据渲染,服务器端的压力太大,如果服务器处理不过来,页面呈现的速度更慢(所以像京东和淘宝这类的网站,除了首屏是服务器端渲染的,其他屏一般都是客户端做数据渲染绑定的)
- 不利于开发,(开发效率低)
- 前后端分离:
- 优点:
- 可以根据需求,任意修改页面中的某一部分内容(例如实时刷新),整体页面不刷新,性能好,体验好(所有表单验证,需要实时刷新的等需求都要基于AJAX实现)
- 有利于开发,提高开发效率
- 后台不需要考虑前端如何实现, 前端也不需要考虑后台用什么技术,真正意义上实现了技术的划分
- 可以同时进行开发:项目开发开始,首先制定前后端数据交互的接口文档(文档中包含了,调取哪个接口或者哪些数据等协议规范),后台把接口先写好(目前很多公司也需要前端自己拿NODE来模拟这些接口),客户端按照接口调取即可,后台再去实现接口功能即可
- 缺点:
- 不利于SEO优化:第一次从服务器端获取的内容不包含需要动态绑定的数据,所以页面的源代码中没有这些内容,不利于SEO收录
后期通过JS添加到页面中的内容,并不会写在页面的源代码中(是源代码不是页面结构)
- 交由客户端渲染,首先需要把页面呈现,然后在通过JS的异步AJAX请求获取数据,在进行数据绑定
浏览器再把动态增加的部分重新渲染,无形中浪费了一些时间,没有服务器端渲染页面呈现速度快
11. vue seo 以及 vue 性能优化
https://juejin.im/post/5f0f1a045188252e415f642c
(1)v-for 的优先级其实是比 v-if 高的
(2)v-for 尽量不使用 index 去作为 key,而是使用唯一值如 id
(3)及时释放资源,如 setInterval
(4)路由懒加载(使得 Vue 服务在第一次加载时的压力就能够相应的小一些)
-
// require法 component: resolve=>(require(['@/components/HelloWorld'], resolve)) // import component: () => import('@/components/HelloWorld')
(5)webpack 处理打包的 JavaScript 文件,图片文件
(6)使用 Tree-Shaking 插件可以将一些无用的沉淀泥沙代码给清理掉
(7)使用CDN的方式引入一些依赖包,在正式环境下,通过CDN,确实有了一些明显的提升
(1)控制首页链接数量(不宜过多,也不宜过少)
(2)扁平化的目录层次(尽量让“蜘蛛爬虫”只要跳转3次,就能到达网站内的任何一个内页)
(3)导航优化 <img> 标签必须添加 “alt” 和 “title” 属性,告诉搜索引擎导航的定位,做到即使图片未能正常显示时,用户也能看到提示文字
<a>标签:页内链接,要加 “title” 属性加以说明,让访客和 “蜘蛛” 知道。
而外部链接,链接到其他网站的,则需要加上 el="nofollow" 属性, 告诉 “蜘蛛” 不要爬,因为一旦“蜘蛛”爬了外部链接之后,就不会再回来了
(4)良好的网站的结构布局,头部、主体(正文、热门)、底部
(5)突出重要内容---合理的设计title、<meta description>和 <meta keywords>
(6)语义化书写 HTML 代码,符合 W3C 标准
h1-h6 是用于标题类的
<nav> 标签是用来设置页面主导航
列表形式的代码使用 ul 或 ol
重要的文字使用 strong 等
(7)h1标签自带权重“蜘蛛” 认为它最重要,一个页面有且最多只能有一个H1标签,放在该页面最重要的标题上面
如首页的 logo 上可以加 H1 标签。副标题用 <h2> 标签, 而其它地方不应该随便乱用 h 标题标签
(8)
(9)
13. 源码解读及收获
(1)闭包结构封装:
jQuery 具体的实现,都被包含在了一个立即执行函数构造的闭包里面,为了不污染全局作用域,只在后面暴露 $ 和 jQuery 这 2 个变量给外界,尽量的避开变量冲突
根据函数作用域链,若没有传入window,就会一层一层向上查找window,而window对象是最顶层的对象,查找速度就会非常慢,传入后,只需要查找参数即可。
(3)jQuery 无 new 构造?
因为封装在了里面,jQuery 里面进行了 new 实例化
(4)链式调用(对象的方法,返回值还是这个对象)
()
1
1
14. typescript 的功能及优势
(1) 学习路线
(2)发展:
TypeScript 是 2012 年由 Microsoft 推出的一门工具
(3)功能:
- @types 智能提示
- JSDoc 函数注释
-
JSDoc 里@param的这个标记,在{}中间代表的就是一个 TS 的 type 类型
/** * 方法:foo * @param {string} name */ function foo (name) { console.log(name) return name }
-
/** * 方法:foo * @param {{firstname: string, nameLength: number}} name */ function foo (name) { console.log(name) return name }
这时函数内的 name 就不是一个string了,而是一个自定义的object类型。当然,当我们访问 name 时,会得到 firstname 和 nameLength 两个属性
-
/** * ajax方法 * * @example `ajax('url', options)` * * @typedef {Object} IAjaxOptions * @property {boolean} [jsonp] 是否jsonp * @property {boolean} [async] 是否async * @property {'GET'|'POST'} [methods] 请求方法 * @property {(options: any)=>void} [success] 成功回调函数 * * @param {string} url url * @param {IAjaxOptions} [options] 参数 * @param { Promise } */ function ajaxNew (url, options) {}
其中 @typedef 的效果是声明一个 type 类型(或者理解为将一个类型起个别名),比如这里就是object类型,名为IAjaxOptions。 而@property的作用是声明上面类型里面包含的属性,用法和@param一致
(4)优势:
15. redux-observable 和 RxJS
- (1)需要先学会函数式编程 RxJS
RxJS 是用 typescript 编写的
Angular 重度使用了 RxJS