一、爬虫基础
1.爬虫概念
网络爬虫(又称为网页蜘蛛),是一种按照一定的规则,自动地抓取万维网信息的程序或脚本。用爬虫最大的好出是批量且自动化得获取和处理信息。对于宏观或微观的情况都可以多一个侧面去了解;
2.urllib库
urllib是python内置的HTTP请求库,旗下有4个常用的模块库:
urllib.request 请求模块
urllib.error 异常处理模块
urllib.parse url解析模块
urllib.robotparser robots.txt解析模块
3.urllib常用函数
接下来我们要具体介绍urllib模块常用的4个函数方法:
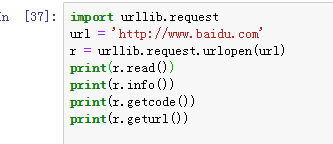
3.1 urllib.request.urlopen(url,data,timeout) 创建一个表示远程URL的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据;
urlopen返回对象提供方法:
read(),readline(),readlines(),fileno(),close():对HTTPResponse类型数据进行操作。
info():返回HTTPResponse对象,表示远程服务器返回的头信息。
getcode():返回http状态码。
geturl():返回请求的url。
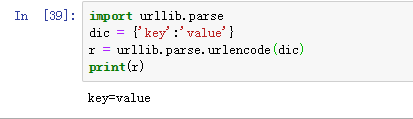
3.2 urllib.parse.urlencode(dict) 将dict或者包含两个元素的元组列表转换成url参数。
例如:字典{'name':'dark-bull','age':200}将被转换为‘name=dark-bull&age=200’

3.3 urllib.request.ProxyHandler(dict) 可以讲dict字典里的ip当作代理进行设置。
网站对某个ip做了限制、封锁时,可以用该方法当成代理去设置

通过代理设置一个http的请求;
3.4 urllib.parse.urlparse(urlstring,scheme='',allow_fragments=True) URL解析函数的重点是将URL字符串拆分为其组件,或者将URL组件合为一个URL字符串。

3.5 urllib.request.urlretrieve(url,filename=None,reporthook=None,data=None)
rulretrieve()方法直接将远程数据下载到本地。
参数url 指定url请求的地址
参数filename指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据)
参数reporthook是一个回调函数,当连接上服务器,以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
参数data指post到服务器的数据,该方法返回一个包含两个元素的(filename,headers)元组,filename表示保存到本地的路径,header表示服务器的响应头。



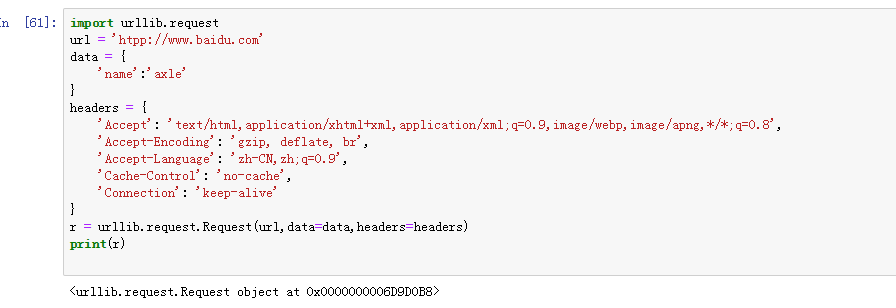
3.6 urllib.request.Request(url,data=None,headers={},origin_req_host=None,unverifiable=False,method=None)
常用参数:
url:访问的地址
data:此参数为可选字段,其中传递的参数需要转为bytes,如果是字典我们只需要通过urllib.parse.urlencode转换即可:
headers:http相应headers传递的信息,构造方法:headers参数传递,通过调用Request对象的 add_header()方法来添加请求头。
(python3.x爬虫基础---http headers详解,可参考此文章。)
3.7 urllib.request.HTTPCookieProcessor()
网站中通过cookie进行判断权限是很常见的,那么我们可以通过urllib.request.HTTPCookieProcesor(cookie)来操作cookie。使用Cookie和使用代理IP一样,也需要创建一个自己的opener。在HTTP包中,提供了cookiejar模块,用于提供对Cookie的支持。http.cookiejar功能强大,我们可以利用本模块的CookieJar类的对象来捕获cookie并在后续链接请求时重新发送,比如可以实现模拟登陆功能,该模块主要的对象有cookieJar、FileCookieJar、MozillCookieJar、LWOCookieJar。
用该函数模拟用户登录的cookie

二、urllib异常处理
当抓取某个网站,出现超时异常;
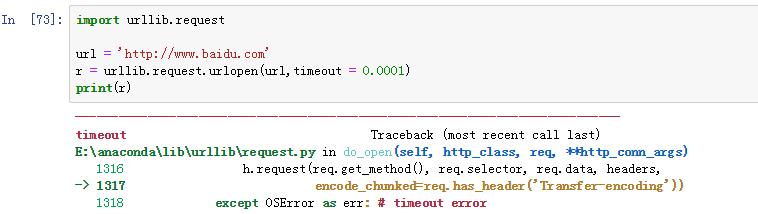
当出现超时脚本结果中不要出现这些错误信息,如何改进呢?我们导入socket包,用try语句捕捉异常数据进行处理;

三、python爬虫之requests库
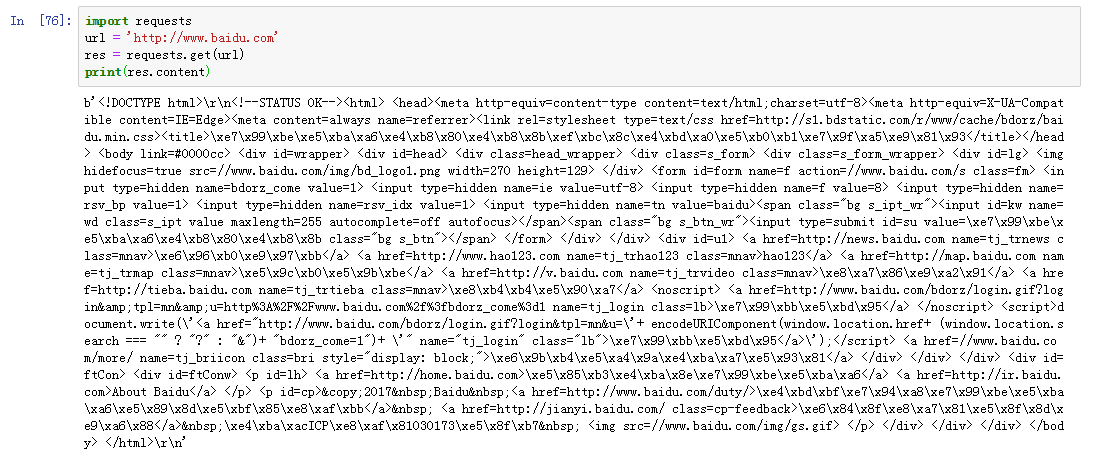
requests 是python实现的简单易用的HTTP库,使用起来比urllib简洁很多;
1.requests常用函数:
requests.get('http://httpbin.org/get')
requests.post('http://httpbin.org/post')
requests.put('http://httpbin.org/put')
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/head')
requests.options('http://httpbin.org/options')

其他方法同上
2.requests返回对象的属性和函数
response.content 返回二进制内容(比如音频)
response.text 返回文本内容
response.status_code 返回请求的状态码
response.headers 返回请求的头信息
response.cookies 获取cookie信息
response.json() 返回json编码信息