一.爬虫对象
猫眼电影TOP100排行榜
二.代码如下
import requests import re,json from lxml import etree import csv class Spider(): def open_csv(self): ''' 在CSV文件的开头写一行标题 :return: ''' with open('data.csv', 'a', newline='', encoding='utf-8') as f: spamwriter = csv.writer(f) spamwriter.writerow(['名称', '主演', '上映时间', '评分']) def __get_page(self,url,headers): ''' 获取文本内容 :param url: :param headers: :return: ''' try: response = requests.get(url, headers=headers) if response.status_code == 200: return response.text else: return None except Exception: return None def __parse_page(self,html): ''' 解析HTML,并得到提取的数据 :param html: :return: ''' data = etree.HTML(html) results = data.xpath('//*[@class="board-wrapper"]/dd/div/div') for result in results: # 电影名称 电影主演 电影上映日期 评分 ws = [ result.xpath('./div[1]/p[1]/a/text()')[0], result.xpath('./div[1]/p[2]/text()')[0].strip(), result.xpath('./div[1]/p[3]/text()')[0], result.xpath('./div[2]/p/i[1]/text()')[0] + result.xpath('./div[2]/p/i[2]/text()')[0], ] #保存到CSV with open('data.csv', 'a', newline='', encoding='utf-8') as f: writer = csv.writer(f) writer.writerow(ws) def run(self): ''' 程序运行入口 :return: ''' self.open_csv() for i in range(11): url ='http://maoyan.com/board/4?offset={}'.format(10*i) headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64)' ' AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' } html = self.__get_page(url,headers) self.__parse_page(html) #实例化类 spider = Spider() spider.run()
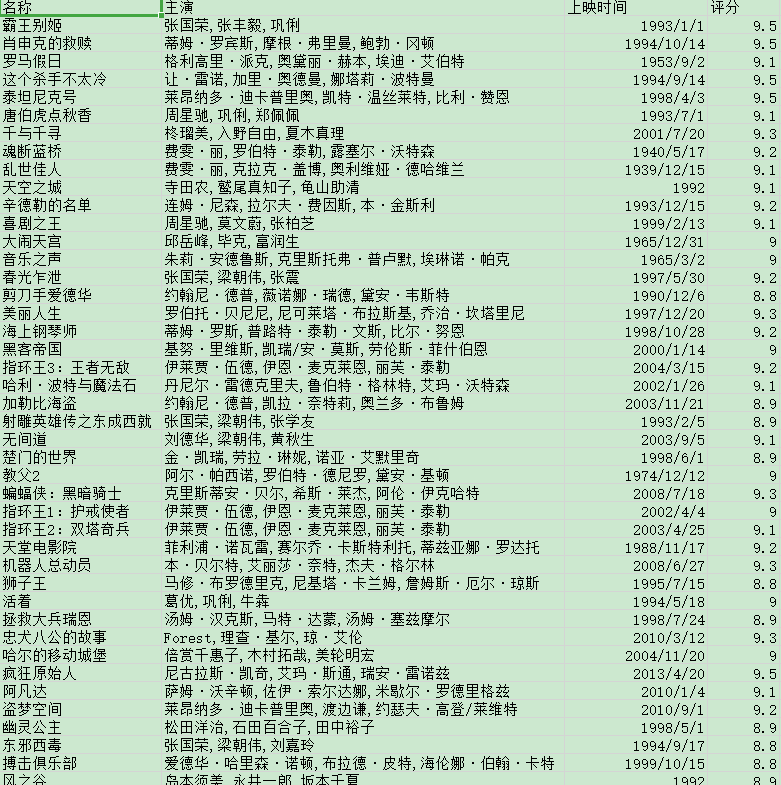
三.运行结果

四.数据分析
(1)电影评分比例
一部电影质量由评分能直接体现出来,而总体评分分布能体现出播放器的质量。
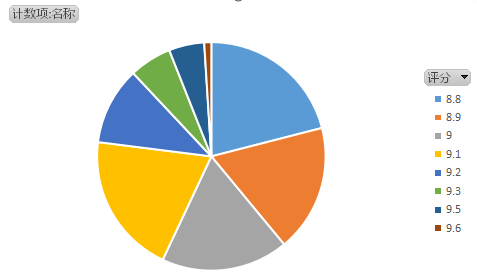
由上图看出8.8-9.1分数的电影比较多,所以猫眼电影的质量还是可以的。
(2)电影的成功除了质量之外,发布的时间也是很重要的。
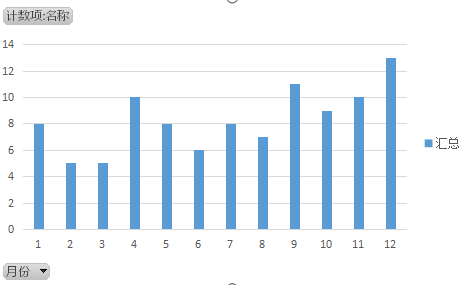
大家看电影都知道,电影基本在假期上映更有热度,这里统计出来,发现下半年的电影比上半年电影好很多。
(3)通过数据透视表可以看出,在猫眼电影TOP100排行榜中,有一部由周星驰主演的《大话西游之月光宝盒》评分远远超过其他的电影,看来星爷的经典难以被超越
