Mac部署hadoop3(伪分布式)
环境信息
- 操作系统:macOS Mojave 10.14.6
- JDK:1.8.0_211 (安装位置:/Library/Java/JavaVirtualMachines/jdk1.8.0_211.jdk/Contents/Home)
- hadoop:3.2.1
免密码登录
- 执行以下命令创建秘钥:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
一路next,最终会在~/.ssh目录生成id_rsa和id_rsa.pub文件
2. 执行以下命令,将自己的秘钥放在ssh授权目录,这样ssh登录自身就不需要输入密码了:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- ssh登录试试,这次不需要密码了:
Last login: Sun Oct 13 21:44:17 on ttys000
(base) zhaoqindeMBP:~ zhaoqin$ ssh localhost
Last login: Sun Oct 13 21:48:57 2019
(base) zhaoqindeMBP:~ zhaoqin$
下载hadoop
- 下载hadoop,地址是:http://hadoop.apache.org/releases.html
- 将下载文件hadoop-3.2.1.tar.gz解压,我这里解压后的地址是:~/software/hadoop-3.2.1/
如果只需要hadoop单机模式,现在就可以了,但是单机模式没有hdfs,因此接下来要做伪分布模式的设置;
伪分布模式设置
进入目录hadoop-3.2.1/etc/hadoop,做以下设置:
- 打开hadoop-env.sh文件,增加JAVA的路径设置:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_211.jdk/Contents/Home
- 配置hdfs地址和端口,打开core-site.xml文件,将configuration节点改为如下内容,(#由于我们将在hadoop中存储数据,同时所有组件都运行在本地主机,这些数据都需要存储在本地文件系统的某个地方,不管选择何种模式,hadoop默认使用hadoop.tmp.dir属性作为根目录,所有文件和数据都写入该目录。):
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
- 修改hdfs备份数,打开hdfs-site.xml文件,将configuration节点改为如下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
- mapreduce中jobtracker的地址和端口,打开mapred-site.xml文件,将configuration节点改为如下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 打开yarn-site.xml文件,将configuration节点改为如下内容:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
- 初始化hdfs文件系统,在目录hadoop-3.2.1/bin执行以下命令,初始化hdfs:
./hdfs namenode -format
初始化成功后,可见如下信息:
2019-10-13 22:13:32,468 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2019-10-13 22:13:32,473 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2019-10-13 22:13:32,474 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at zhaoqindeMBP/192.168.50.12
************************************************************/
启动
- 进入目录hadoop-3.2.1/sbin,执行./start-dfs.sh启动hdfs:
(base) zhaoqindeMBP:sbin zhaoqin$ ./start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [zhaoqindeMBP]
zhaoqindeMBP: Warning: Permanently added 'zhaoqindembp,192.168.50.12' (ECDSA) to the list of known hosts.
2019-10-13 22:28:30,597 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
上面的警告不会影响使用;
2. 浏览器访问地址:localhost:9870 ,可见hadoop的web页面如下图: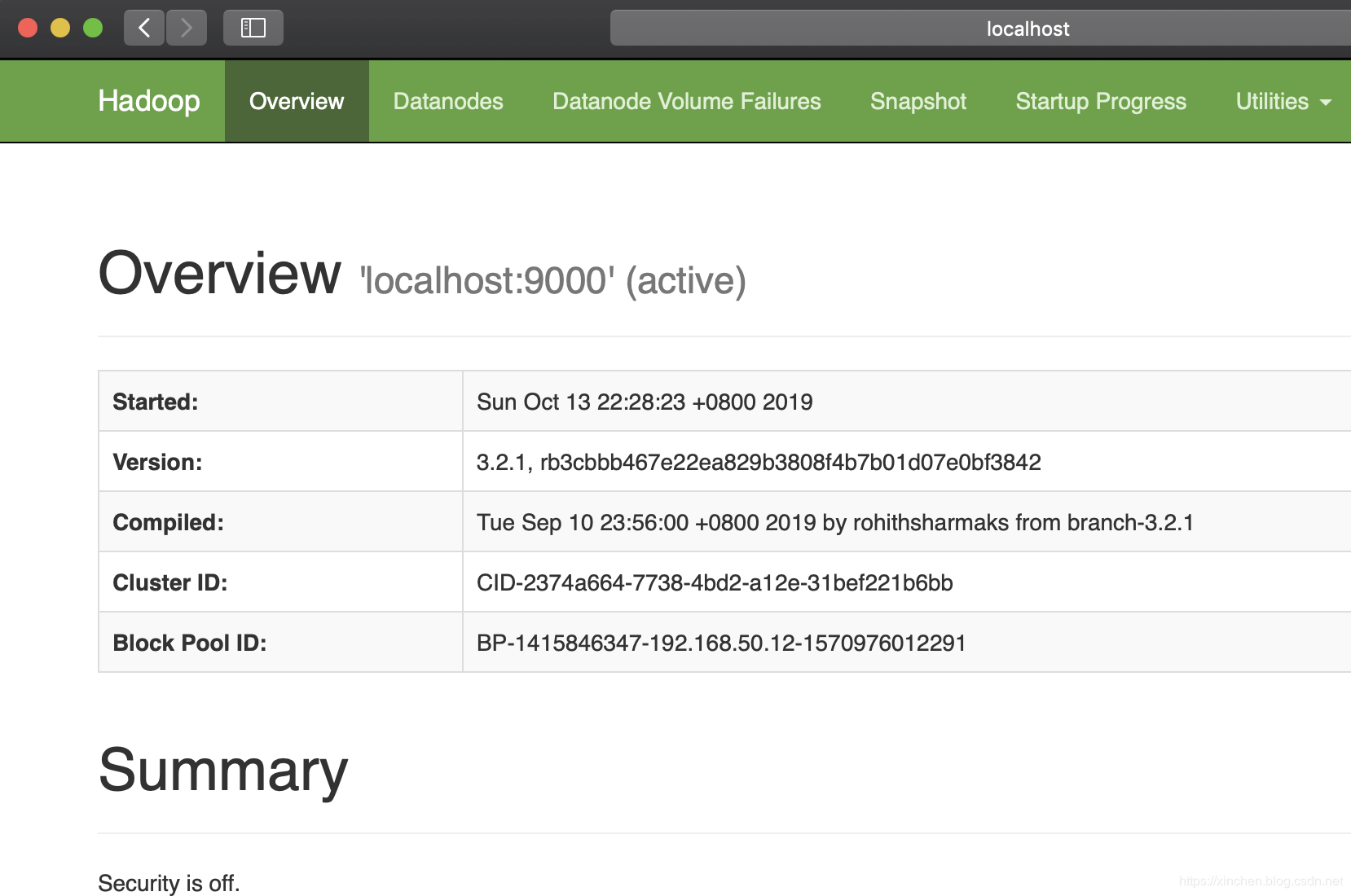
3. 进入目录hadoop-3.2.1/sbin,执行./start-yarn.sh启动yarn:
base) zhaoqindeMBP:sbin zhaoqin$ ./start-yarn.sh
Starting resourcemanager
Starting nodemanagers
- 浏览器访问地址:localhost:8088 ,可见yarn的web页面如下图:

- 问题来了:http://localhost:8088/cluster这个页面启动不了????
一直报上面的错误,对于java痴而言,根本不知道啥原因,搜索了好长时间,发现说是要更换jdk,好嘛,从12换到jdk8,可以了~心力憔悴呀。 - 执行jps命令查看所有java进程,正常情况下可以见到以下进程:
(base) zhaoqindeMBP:sbin zhaoqin$ jps
2161 NodeManager
1825 SecondaryNameNode
2065 ResourceManager
1591 NameNode
2234 Jps
1691 DataNode
至此,hadoop3伪分布式环境的部署、设置、启动都已经完成。
停止hadoop服务
进入目录hadoop-3.2.1/sbin,执行./stop-all.sh即可关闭hadoop的所有服务:
(base) zhaoqindeMBP:sbin zhaoqin$ ./stop-all.sh
WARNING: Stopping all Apache Hadoop daemons as zhaoqin in 10 seconds.
WARNING: Use CTRL-C to abort.
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [zhaoqindeMBP]
2019-10-13 22:49:00,941 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Stopping nodemanagers
Stopping resourcemanager
以上就是Mac环境部署hadoop3的全部过程,希望能给您一些参考。
四:运行Hadoop自带的MapReduce程序(wordcount)
wordcount: 用于统计每个单词出现的次数
# 在HDFS中创建层级目录
bin/hadoop fs -mkdir -p /wordcount/input
# 将hadoop中的LICENSE.txt文件上传到层级目录中
bin/hdfs dfs -put README.txt /wordcount/input
# 查看某个层级目录下面的内容
bin/hdfs dfs -ls /wordcount/input
# 运行hadoop自带的示例程序hadoop-mapreduce-examples-3.1.1.jar 该jar中有多个示例,wordcount是其中一个示例,用于统计每个单词出现的次数,
# /wordcount/input/LICENSE.txt 表示要统计的文件
# /wordcount/output 存放统计结果存放的目录,注意/wordcount/output目录不能存在
bin/hadoop jar /usr/local/Cellar/hadoop/3.1.1/libexec/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar wordcount /wordcount/input/README.txt /wordcount/output
# 查看目录内容,运行完wordcount程序,输出目录下会有一个文件叫part-r-00000,这个就是统计的结果
bin/hdfs dfs -ls /wordcount/output
# 查看统计结果
bin/hadoop fs -cat /wordcount/output/part-r-00000
# 将hdfs指定的目录内容拉到自己机器上
bin/hadoop fs -get /wordcount/output /Users/mengday/Desktop/wordcount
统计结果part-r-00000
http://localhost:9870/ Utilities -> Browse the file system
另外一篇:https://blog.csdn.net/pgs1004151212/article/details/104391391
五:hadoop 安装启动问题
1. There are 0 datanode(s) running and no node(s) are excluded in this operation.
有的时候在启动hadoop的时候使用jps查看如果没有启动datanode
原因
当我们使用hadoop namenode -format格式化namenode时,会在namenode数据文件夹(这个文件夹为自己配置文件中dfs.name.dir的路径)中保存一个current/VERSION文件,记录clusterID,datanode中保存的current/VERSION文件中的clustreID的值是上一次格式化保存的clusterID,这样,datanode和namenode之间的ID不一致。
解决方法
第一种:如果dfs文件夹中没有重要的数据,那么删除dfs文件夹(dfs目录在core-site.xml中hadoop.tmp.dir配置),再重新格式化和启动hadoop即可。此种方式会将数据清空!
hadoop namenode -format
sbin/start-dfs.sh
第二种:如果dfs文件中有重要的数据,那么在dfs/name目录下找到一个current/VERSION文件,记录clusterID并复制。然后dfs/data目录下找到一个current/VERSION文件,将其中clustreID的值替换成刚刚复制的clusterID的值即可;
第三种:提示:ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode.
要在/etc/hosts中加入本机的IP,而不是127.0.0.1,本机ip变了后,要在这里添加上一行:
192.168.13.40 localhost
2. mkdir: Cannot create directory /user. Name node is in safe mode. 可通过执行下面命令执行。
# 离开安全模式
bin/hadoop dfsadmin -safemode leave
3. 运行wordcount示例程序一直循环打印日志updateStatus
ipc.Client: IPC Client (389993238) connection to /0.0.0.0:8032 from mengday got value #80
ipc.ProtobufRpcEngine: Call: getApplicationReport took 1ms
security.UserGroupInformation: PrivilegedAction as:mengday (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:328)
mapred-site.xml去掉mapreduce.framework.name配置,并重启hadoop: sbin/stop-all.sh 和 sbin/start-all.sh。
<configuration>
<!--
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
-->
<property>
<name>mapreduce.job.tracker</name>
<value>hdfs://127.0.0.1:8001</value>
<final>true</final>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>200</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>200</value>
</property>
</configuration>
yarn-site.xml 中增加yarn.resourcemanager.address、yarn.app.mapreduce.am.resource.mb、yarn.scheduler.minimum-allocation-mb配置
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>127.0.0.1:8032</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>200</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>50</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
七、Pyspark开发环境搭建
3、下载hadoop
4、下载winutils.exe并放在hadoopin目录下
5 、pip install -U -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark安装pyspark和py4j.
6、Pycharm环境测试
pyspark代码一:
import os
os.environ['JAVA_HOME'] = "C:Program FilesJavajdk1.8.0_191"
os.environ['HADOOP_HOME'] = "E:softwarehadoop"
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("PythonWordCount")
sc = SparkContext(conf = conf)
links = sc.parallelize(["A","B","C","D"])
C = links.flatMap(lambda dest:(dest,1)).count()
D = links.map(lambda dest:(dest,1)).count()
print(C)
print(D)
c = links.flatMap(lambda dest:(dest,1)).collect()
d = links.map(lambda dest:(dest,1)).collect()
print(c)
print(d)
代码运行结果为:
['A', 1, 'B', 1, 'C', 1, 'D', 1]
[('A', 1), ('B', 1), ('C', 1), ('D', 1)]
Process finished with exit code 0
pyspark代码二:
import os
os.environ['JAVA_HOME'] = "C:Program FilesJavajdk1.8.0_191"
os.environ['HADOOP_HOME'] = "E:softwarehadoop"
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
# 初始化
spark = SparkSession.builder.master("local[*]").appName("FiratApp1").getOrCreate()
# 下面两句都可以获取0到9的数据
# data = spark.createDataFrame(map(lambda x: (x,), range(10)), ["id"])
data = spark.range(0, 10).select(col("id").cast("double"))
# 求和
data.agg({'id': 'sum'}).show()
# 关闭
spark.stop()
+-------+
|sum(id)|
+-------+
| 45.0|
+-------+
MAC Spark安装和环境变量设置
Spark安装
1.官网下载spark
本文下载版本是https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.5/
2.安装spark到/usr/local/
terminal中定位到spark-2.3.0-bin-hadoop2.7.tgz目录,移动spark-2.3.0-bin-hadoop2.7.tgz到/usr/local
rm spark-2.3.0-bin-hadoop2.7.tgz /usr/local
解压缩spark-2.3.0-bin-hadoop2.7.tgz
tar -zvxf spark-2.3.0-bin-hadoop2.7.tgz(若要改名,再添加一个变量为你想改动的名字,本文未改动)
3.安装pyspark(本文使用python3,且mac自带python 2.7)
pip3 install pyspark
4.设置环境变量
打开~/.bash_profile
vim ~/.bash_profile
添加
export SPARK_HOME=/usr/local/spark-2.3.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
使环境变量生效
source ~/.bash_profile
5.在terminal中输入
pyspark进入到Spark目录的conf配置文件中~/Applications/spark-2.4.5-bin-hadoop2.7/conf,执行命令:cp spark-env.sh.template spark-env.sh将spark-env.sh.template拷贝一份:vim spark-env.sh,在里面加入如下内容:
export SCALA_HOME=/usr/local/Cellar/scala/2.12.6
export SPARK_MASTER_IP=localhost
export SPARK_WORKER_MEMORY=4G
配置好之后,命令行执行:spark-shell,如果出现如下所示的画面,就表明spark安装成功了
9. pycharm配置
使用pycharm创建一个project。
创建过程中选择python的环境。进入之后点击Run--》Edit Configurations--》Environment variables.
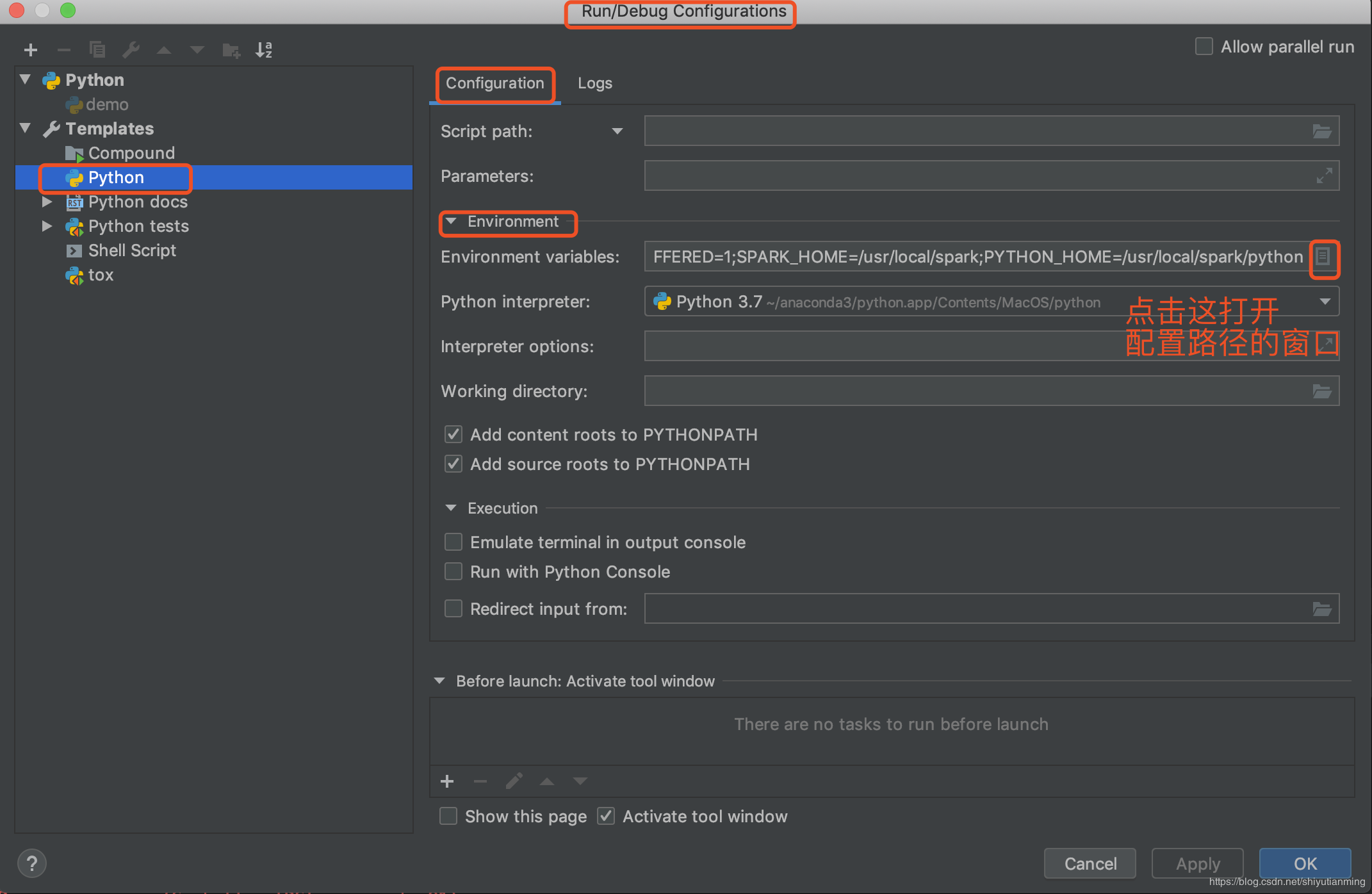
在弹出的窗口中输入两个路径
点击+,输入两个name,一个是SPARK_HOME,另外一个是PYTHONPATH,设置它们的values,
SPARK_HOME的value是安装文件夹spark-2.1.1-bin-hadoop2.7的绝对路径,例如我的SPARK_HOME的value是/usr/local/spark
PYTHONPATH的value是该绝对路径加上/python,例如我的PYTHONPATH的value是/usr/local/spark/python 。设置好了保存。(注意不管是路径的哪里,都不能有空格!!尤其是结尾!!) 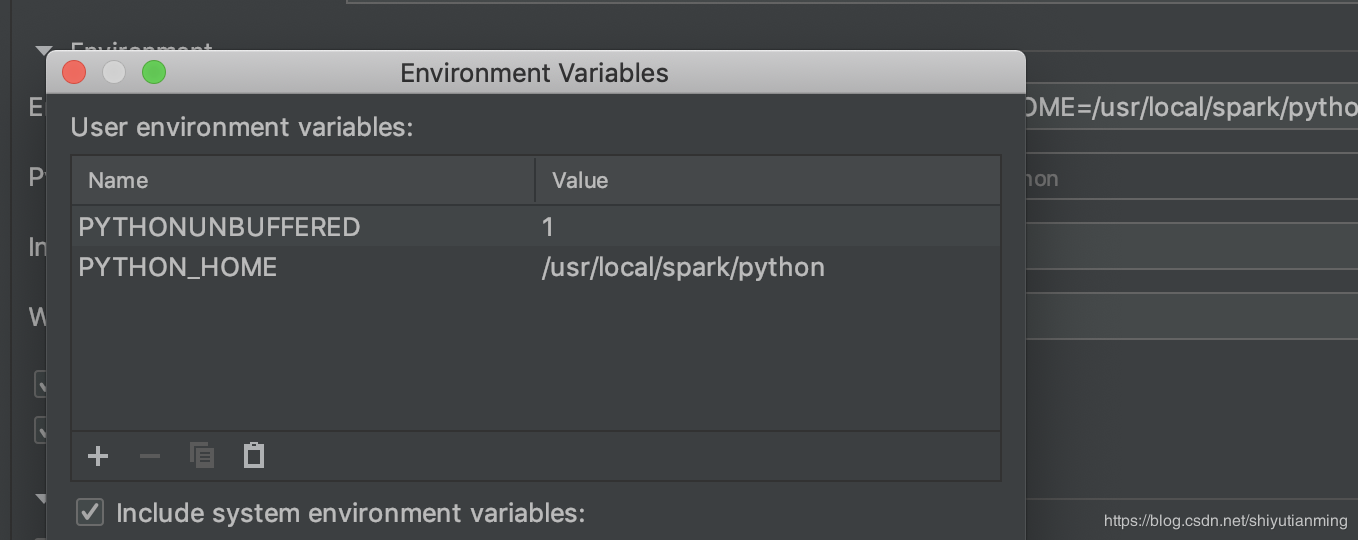
还要配置两个压缩包,否则会报错
点击Pycharm-Preference中的project structure中点击右边的“add content root”,添加py4j-some-version.zip和pyspark.zip的路径(这两个文件都在Spark中的python文件夹下)
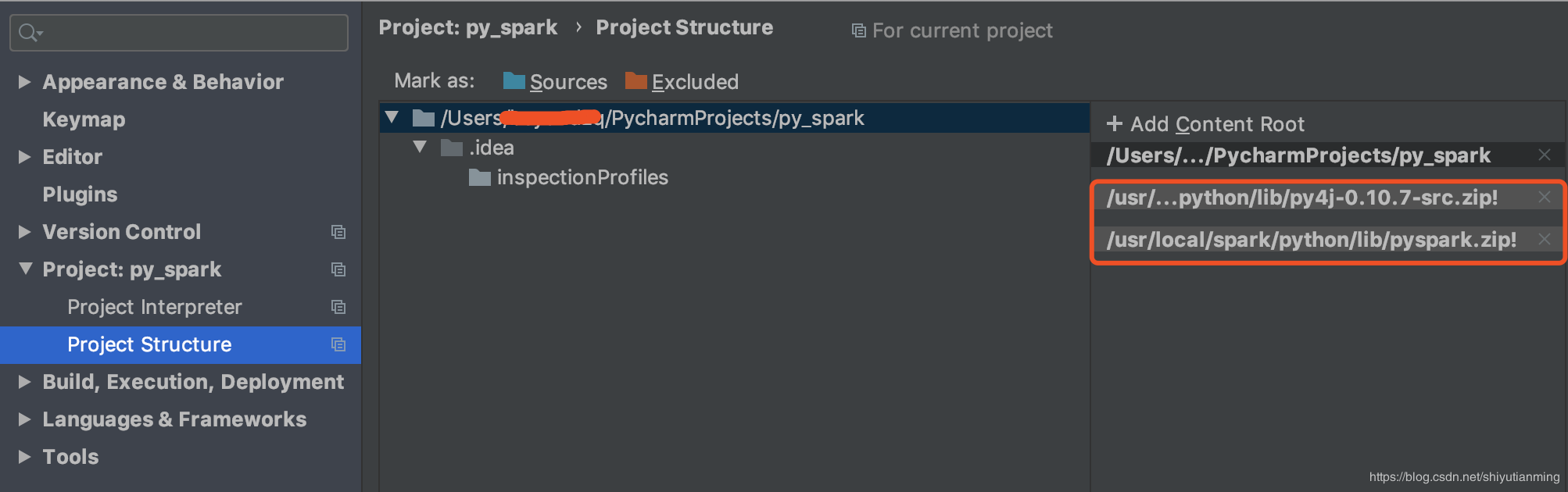
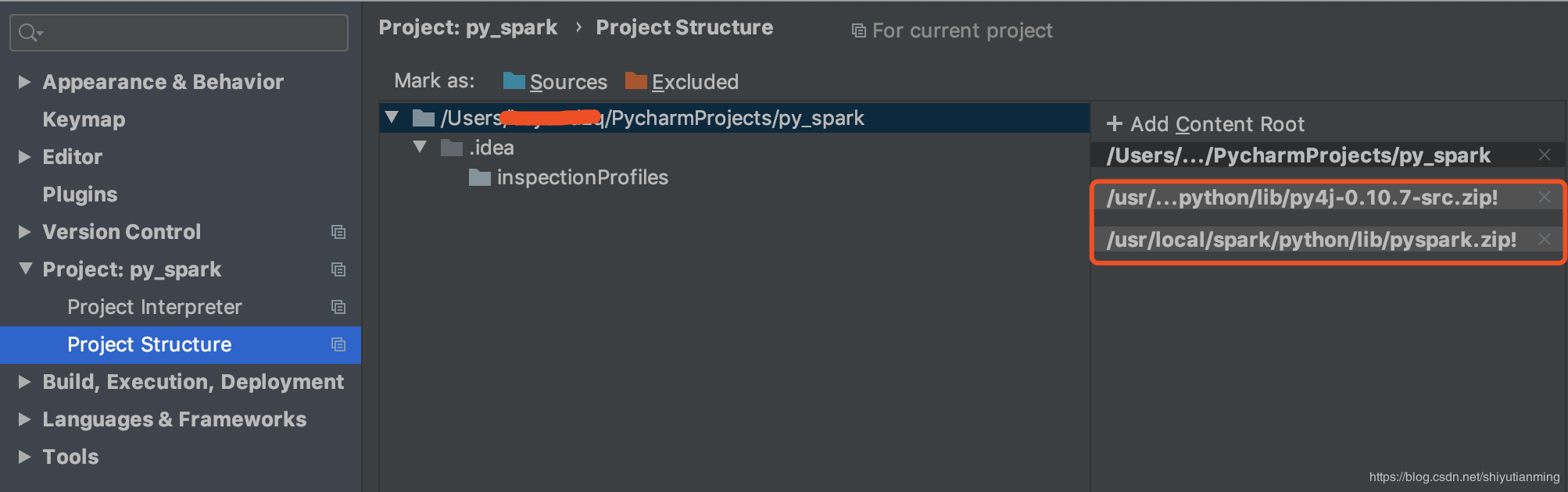
至此,配置完成,写一个例子测试一下:
编写pyspark wordcount测试一下。我这边使用的是pyspark streaming程序。
代码如下:
WordCount.py
from pyspark import SparkContext from pyspark.streaming import StreamingContext # Create a local StreamingContext with two working thread and batch interval of 1 second sc = SparkContext("local[2]", "NetWordCount") ssc = StreamingContext(sc, 1) # Create a DStream that will connect to hostname:port, like localhost:9999 lines = ssc.socketTextStream("localhost", 9999) # Split each line into words words = lines.flatMap(lambda line: line.split(" ")) # Count each word in each batch pairs = words.map(lambda word: (word, 1)) wordCounts = pairs.reduceByKey(lambda x, y: x + y) # Print the first ten elements of each RDD generated in this DStream to the console wordCounts.pprint() ssc.start() # Start the computation ssc.awaitTermination() # Wait for the computation to terminate
先到终端运行如下命令:
$ nc -lk 9999
接着可以在pycharm中右键运行一下。然后在上面这个命令行中输入单词以空格分割:
我输入如下:
a b a d d d d
然后摁回车。可以看到pycharm中输出如下结果:
Time: 2017-12-17 22:06:19
-------------------------------------------
('b', 1)
('d', 4)
('a', 2)
至此,spark完成。
例子:
# coding=utf-8
from pyspark.sql import SparkSession
from pyspark.sql.types import IntegerType
spark = SparkSession .builder .master("local[2]") .appName("test") .getOrCreate()
sc = spark.sparkContext
data = [1, 2, 3, 4, 5]
# 将 list 转化为 rdd
distData = sc.parallelize(data)
print(distData.collect())
# 把 rdd 转化为 df
df = spark.createDataFrame(distData, IntegerType())
df.show()
# 将 df 注册成临时表
df.createTempView("tmp")
spark.sql("select * from tmp").show()
export SCALA_HOME=/Users/xxxxxx/Applications/scala-2.13.1scala
export PATH=$PATH:$SCALA_HOME/bin
输入scala验证。
<property>
<name>dfs.webhdfs.enabled</name><value>true</value></property>