Python实现MapReduce
下面使用mapreduce模式实现了一个简单的统计日志中单词出现次数的程序:
from functools import reduce
from multiprocessing import Pool
from collections import Counter
def read_inputs(file):
for line in file:
line = line.strip()
yield line.split()
def count(file_name):
file = open(file_name)
lines = read_inputs(file)
c = Counter()
for words in lines:
for word in words:
c[word] += 1
return c
def do_task():
job_list = ['log.txt'] * 10000
pool = Pool(8)
return reduce(lambda x, y: x+y, pool.map(count, job_list))
if __name__ == "__main__":
rv = do_task()
一个python实现的mapreduce程序
map:
# !/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print ("%s %s") % (word, 1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
reduce:
#!/usr/bin/env python
import operator
import sys
current_word = None
curent_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split(' ', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
curent_count += count
else:
if current_word:
print '%s %s' % (current_word,curent_count)
current_word=word
curent_count=count
if current_word==word:
print '%s %s' % (current_word,curent_count)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
测试:
[root@node1 input]# echo "foo foo quux labs foo bar zoo zoo hying" | /home/hadoop/input/max_map.py | sort | /home/hadoop/input/max_reduce.py- 1
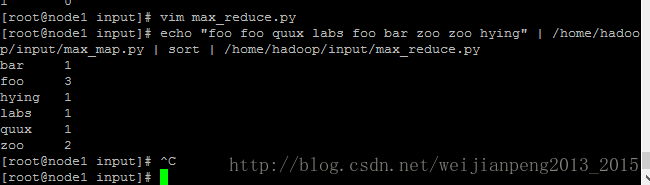
执行:可将其写入脚本文件
//注意-file之间一定不能空格
hadoop jar /hadoop64/hadoop-2.7.1/share/hadoop/tools/lib/hadoop-*streaming*.jar -D stream.non.zero.exit.is.failure=false -file /home/hadoop/input/max_map.py -mapper /home/hadoop/input/max_map.py -file /home/hadoop/input/max_reduce.py -reducer /home/hadoop/input/max_reduce.py -input /input/temperature/ -output /output/temperature- 1
- 2
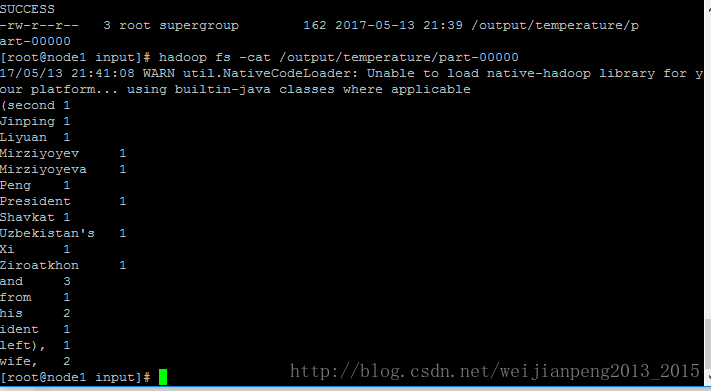
Hadoop(三):MapReduce程序(python)
使用python语言进行MapReduce程序开发主要分为两个步骤,一是编写程序,二是用Hadoop Streaming命令提交任务。
还是以词频统计为例
一、程序开发
1、Mapper
1 for line in sys.stdin:
2 filelds = line.strip.split(' ')
3 for item in fileds:
4 print item+' '+'1'
2、Reducer

1 import sys
2
3 result={}
4 for line in sys.stdin:
5 kvs = line.strip().split(' ')
6 k = kvs[0]
7 v = kvs[1]
8 if k in result:
9 result[k]+=1
10 else:
11 result[k] = 1
12 for k,v in result.items():
13 print k+' '+v
....
写完发现其实只用map就可以处理了...reduce只用cat就好了
3、运行脚本
1)Streaming简介
Hadoop的MapReduce和HDFS均采用Java进行实现,默认提供Java编程接口,用户通过这些编程接口,可以定义map、reduce函数等等。
但是如果希望使用其他语言编写map、reduce函数怎么办呢?
Hadoop提供了一个框架Streaming,Streaming的原理是用Java实现一个包装用户程序的MapReduce程序,该程序负责调用hadoop提供的Java编程接口。
2)运行命令
/.../bin/hadoop streaming
-input /..../input
-output /..../output
-mapper "mapper.py"
-reducer "reducer.py"
-file mapper.py
-file reducer.py
-D mapred.job.name ="wordcount"
-D mapred.reduce.tasks = "1"
3)Streaming常用命令
(1)-input <path>:指定作业输入,path可以是文件或者目录,可以使用*通配符,-input选项可以使用多次指定多个文件或目录作为输入。
(2)-output <path>:指定作业输出目录,path必须不存在,而且执行作业的用户必须有创建该目录的权限,-output只能使用一次。
(3)-mapper:指定mapper可执行程序或Java类,必须指定且唯一。
(4)-reducer:指定reducer可执行程序或Java类,必须指定且唯一。
(5)-file, -cacheFile, -cacheArchive:分别用于向计算节点分发本地文件、HDFS文件和HDFS压缩文件,具体使用方法参考文件分发与打包。
(6)numReduceTasks:指定reducer的个数,如果设置-numReduceTasks 0或者-reducer NONE则没有reducer程序,mapper的输出直接作为整个作业的输出。
(7)-jobconf | -D NAME=VALUE:指定作业参数,NAME是参数名,VALUE是参数值,可以指定的参数参考hadoop-default.xml。
-jobconf mapred.job.name='My Job Name'设置作业名
-jobconf mapred.job.priority=VERY_HIGH | HIGH | NORMAL | LOW | VERY_LOW设置作业优先级
-jobconf mapred.job.map.capacity=M设置同时最多运行M个map任务
-jobconf mapred.job.reduce.capacity=N设置同时最多运行N个reduce任务
-jobconf mapred.map.tasks 设置map任务个数
-jobconf mapred.reduce.tasks 设置reduce任务个数
-jobconf mapred.compress.map.output 设置map的输出是否压缩
-jobconf mapred.map.output.compression.codec 设置map的输出压缩方式
-jobconf mapred.output.compress 设置reduce的输出是否压缩
-jobconf mapred.output.compression.codec 设置reduce的输出压缩方式
-jobconf stream.map.output.field.separator 设置map输出分隔符
例子:-D stream.map.output.field.separator=: 以冒号进行分隔
-D stream.num.map.output.key.fields=2 指定在第二个冒号处进行分隔,也就是第二个冒号之前的作为key,之后的作为value
(8)-combiner:指定combiner Java类,对应的Java类文件打包成jar文件后用-file分发。
(9)-partitioner:指定partitioner Java类,Streaming提供了一些实用的partitioner实现,参考KeyBasedFiledPartitoner和IntHashPartitioner。
(10)-inputformat, -outputformat:指定inputformat和outputformat Java类,用于读取输入数据和写入输出数据,分别要实现InputFormat和OutputFormat接口。如果不指定,默认使用TextInputFormat和TextOutputFormat。
(11)cmdenv NAME=VALUE:给mapper和reducer程序传递额外的环境变量,NAME是变量名,VALUE是变量值。
(12)-mapdebug, -reducedebug:分别指定mapper和reducer程序失败时运行的debug程序。
(13)-verbose:指定输出详细信息,例如分发哪些文件,实际作业配置参数值等,可以用于调试。
使用python实现MapReduce的wordcount实例
Hadopp的基本框架是用java实现的,而各类书籍基本也是以java为例实现mapreduce,但笔者日常工作都是用python,故此找了一些资料来用python实现mapreduce实例。
一、环境
2、python3.5
二、基本思想介绍
使用python实现mapreduce调用的是Hadoop Stream,主要利用STDIN(标准输入),STDOUT(标准输出)来实现在map函数和reduce函数之间的数据传递。
我们需要做的是利用python的sys.stdin读取输入数据,并把输入传递到sys.stdout,其他的工作Hadoop的流API会为我们处理。
三、实例
以下是在hadoop官网下载的python版本mapper函数和reducer函数,文件位置默认在/usr/local/working中,
1、mapper.py
(1)代码
-
import sys
-
#输入为标准输入stdin
-
for line in sys.stdin:
-
#删除开头和结果的空格
-
line = line.strip( )
-
#以默认空格分隔行单词到words列表
-
words = line.split( )
-
for word in words:
-
#输出所有单词,格式为“单词,1”以便作为reduce的输入
-
print('%s %s' % (word,1))
echo "aa bb cc dd aa cc" | python mapper.py
2、reducer.py
(1)代码
-
import sys
-
-
current_word = None
-
current_count = 0
-
word = None
-
-
#获取标准输入,即mapper.py的输出
-
for line in sys.stdin:
-
line = line.strip()
-
#解析mapper.py输出作为程序的输入,以tab作为分隔符
-
word,count = line.split(' ',1)
-
#转换count从字符型成整型
-
try:
-
count = int(count)
-
except ValueError:
-
#非字符时忽略此行
-
continue
-
#要求mapper.py的输出做排序(sort)操作,以便对连续的word做判断
-
if current_word == word:
-
current_count +=count
-
else:
-
if current_word:
-
#输出当前word统计结果到标准输出
-
print('%s %s' % (current_word,current_count))
-
current_count =count
-
current_word =word
-
-
#输出最后一个word统计
-
if current_word ==word:
-
print('%s %s' % (current_word,current_count))
echo "aa aa bb cc dd dd" | python mapper.py | python reducer.py
3、确保已经搭建好完全分布式的hadoop环境,在HDFS中新建文件夹
bin/hdfs dfs -mkdir /temp/
bin/hdfs dfs -mkdir /temp/hdin
4、将hadoop目录中的LICENSE.txt文件上传到HDFS中
bin/hdfs dfs -copyFromLocal LICENSE.txt /temp/hdin
5、执行文件work.sh
(1)代码
-
#!/bin/bash
-
#mapper函数和reducer函数文件地址
-
export CURRENT=/usr/local/working
-
#先删除输出目录
-
$HADOOP_HOME/bin/hdfs dfs -rm -r /temp/hdout
-
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.7.3.jar
-
-input "/temp/hdin/*"
-
-output "/temp/hdout"
-
-mapper "python mapper.py"
-
-reducer "python reducer.py"
-
-file "$CURRENT/mapper.py"
-
-file "$CURRENT/reducer.py"
sh work.sh
6、查看结果
bin/hdfs dfs -cat /temp/hdout/*
-
"AS 16
-
"COPYRIGHTS 1
-
"Contribution" 2
-
"Contributor" 2
-
"Derivative 1
-
"Legal 1
-
"License" 1
-
"License"); 1
-
"Licensed 1
-
"Licensor" 1
-
"Losses") 1
-
"NOTICE" 1
-
"Not 1
-
...
Python结合Shell/Hadoop实现MapReduce
基本流程为:
cat data | map | sort | reduce
cat devProbe | ./mapper.py | sort| ./reducer.py
echo "foo foo quux labs foo bar quux" | ./mapper.py | sort -k1,1 | ./reducer.py
# -k, -key=POS1[,POS2] 键以pos1开始,以pos2结束
如不执行下述命令,可以再py文件前加上python调用
chmod +x mapper.py
chmod +x reducer.py
对于分布式环境下,可以使用以下命令:
hadoop jar /[YOUR_PATH]/hadoop/tools/lib/hadoop-streaming-2.6.0-cdh5.4.4.jar
-file mapper.py -mapper mapper.py
-file reducer.py -reducer reducer.py
-input [IN_FILE] -output [OUT_DIR]
mapper.py
#!/usr/bin/python
# -*- coding: UTF-8 -*-
__author__ = 'Manhua'
import sys
for line in sys.stdin:
line = line.strip()
item = line.split('`')
print "%s %s" % (item[0]+'`'+item[1], 1)
reducer.py
#!/usr/bin/python
# -*- coding: UTF-8 -*-
__author__ = 'Manhua'
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split(' ', 1)
try:
count = int(count)
except ValueError: #count如果不是数字的话,直接忽略掉
continue
if current_word == word:
current_count += count
else:
if current_word:
print "%s %s" % (current_word, current_count)
current_count = count
current_word = word
if word == current_word: #不要忘记最后的输出
print "%s %s" % (current_word, current_count)
其它:
Python+Hadoop Streaming实现MapReduce任务:https://blog.csdn.net/czl389/article/details/77247534
用Python编写MapReduce代码与调用-某一天之前的所有活跃用户统计https://blog.csdn.net/babyfish13/article/details/53841990
Python 实践之 400 行 Python 写一个类 Hadoop 的 MapReduce 框架:https://www.v2ex.com/t/149803,https://github.com/xiaojiaqi/py_hadoop
http://xiaorui.cc/2014/11/14/python使用mrjob实现hadoop上的mapreduce/
MapReduce实现两表的Join--原理及python和java代码实现
用Hive一句话搞定的,但是有时必须要用mapreduce
1. 概述
在传统数据库(如:MYSQL)中,JOIN操作是非常常见且非常耗时的。而在HADOOP中进行JOIN操作,同样常见且耗时,由于Hadoop的独特设计思想,当进行JOIN操作时,有一些特殊的技巧。本文首先介绍了Hadoop上通常的JOIN实现方法,然后给出了几种针对不同输入数据集的优化方法。
2. 常见的join方法介绍
假设要进行join的数据分别来自File1和File2.2.1 reduce side join
reduce side join是一种最简单的join方式,其主要思想如下:在map阶段,map函数同时读取两个文件File1和File2,为了区分两种来源的key/value数据对,对每条数据打一个标签(tag),比如:tag=0表示来自文件File1,tag=2表示来自文件File2。即:map阶段的主要任务是对不同文件中的数据打标签。
在reduce阶段,reduce函数获取key相同的来自File1和File2文件的value list, 然后对于同一个key,对File1和File2中的数据进行join(笛卡尔乘积)。即:reduce阶段进行实际的连接操作。
2.2 map side join
之所以存在reduce side join,是因为在map阶段不能获取所有需要的join字段,即:同一个key对应的字段可能位于不同map中。Reduce side join是非常低效的,因为shuffle阶段要进行大量的数据传输。Map side join是针对以下场景进行的优化:两个待连接表中,有一个表非常大,而另一个表非常小,以至于小表可以直接存放到内存中。这样,我们可以将小表复制多份,让每个map task内存中存在一份(比如存放到hash table中),然后只扫描大表:对于大表中的每一条记录key/value,在hash table中查找是否有相同的key的记录,如果有,则连接后输出即可。
为了支持文件的复制,Hadoop提供了一个类DistributedCache,使用该类的方法如下:
(1)用户使用静态方法DistributedCache.addCacheFile()指定要复制的文件,它的参数是文件的URI(如果是HDFS上的文件,可以这样:hdfs://namenode:9000/home/XXX/file,其中9000是自己配置的NameNode端口号)。JobTracker在作业启动之前会获取这个URI列表,并将相应的文件拷贝到各个TaskTracker的本地磁盘上。(2)用户使用DistributedCache.getLocalCacheFiles()方法获取文件目录,并使用标准的文件读写API读取相应的文件。
2.3 SemiJoin
SemiJoin,也叫半连接,是从分布式数据库中借鉴过来的方法。它的产生动机是:对于reduce side join,跨机器的数据传输量非常大,这成了join操作的一个瓶颈,如果能够在map端过滤掉不会参加join操作的数据,则可以大大节省网络IO。实现方法很简单:选取一个小表,假设是File1,将其参与join的key抽取出来,保存到文件File3中,File3文件一般很小,可以放到内存中。在map阶段,使用DistributedCache将File3复制到各个TaskTracker上,然后将File2中不在File3中的key对应的记录过滤掉,剩下的reduce阶段的工作与reduce side join相同。
更多关于半连接的介绍,可参考:半连接介绍:http://wenku.baidu.com/view/ae7442db7f1922791688e877.html
2.4 reduce side join + BloomFilter
在某些情况下,SemiJoin抽取出来的小表的key集合在内存中仍然存放不下,这时候可以使用BloomFiler以节省空间。BloomFilter最常见的作用是:判断某个元素是否在一个集合里面。它最重要的两个方法是:add() 和contains()。最大的特点是不会存在false negative,即:如果contains()返回false,则该元素一定不在集合中,但会存在一定的true negative,即:如果contains()返回true,则该元素可能在集合中。
因而可将小表中的key保存到BloomFilter中,在map阶段过滤大表,可能有一些不在小表中的记录没有过滤掉(但是在小表中的记录一定不会过滤掉),这没关系,只不过增加了少量的网络IO而已。
更多关于BloomFilter的介绍,可参考:http://blog.csdn.net/jiaomeng/article/details/1495500
3. 二次排序
在Hadoop中,默认情况下是按照key进行排序,如果要按照value进行排序怎么办?即:对于同一个key,reduce函数接收到的value list是按照value排序的。这种应用需求在join操作中很常见,比如,希望相同的key中,小表对应的value排在前面。有两种方法进行二次排序,分别为:buffer and in memory sort和 value-to-key conversion。
对于buffer and in memory sort,主要思想是:在reduce()函数中,将某个key对应的所有value保存下来,然后进行排序。 这种方法最大的缺点是:可能会造成out of memory。
对于value-to-key conversion,主要思想是:将key和部分value拼接成一个组合key(实现WritableComparable接口或者调用setSortComparatorClass函数),这样reduce获取的结果便是先按key排序,后按value排序的结果,需要注意的是,用户需要自己实现Paritioner,以便只按照key进行数据划分。Hadoop显式的支持二次排序,在Configuration类中有个setGroupingComparatorClass()方法,可用于设置排序group的key值,
reduce-side-join python代码
hadoop有个工具叫做steaming,能够支持python、shell、C++、PHP等其他任何支持标准输入stdin及标准输出stdout的语言,其运行原理可以通过和标准java的map-reduce程序对比来说明:
使用原生java语言实现Map-reduce程序
- hadoop准备好数据后,将数据传送给java的map程序
- java的map程序将数据处理后,输出O1
- hadoop将O1打散、排序,然后传给不同的reduce机器