应用举例

我们假设订票系统听到用户说:“ I would like to arrive Taipei on November 2nd”,你的系统有一些slot(有一个slot叫做Destination,一个slot叫做time of arrival),系统要自动知道这边的每一个词汇是属于哪一个slot,
比如Taipei属于Destination这个slot,November 2nd属于time of arrival这个slot。

这个问题你当然可以使用一个feedforward neural network来解,也就是说我叠一个feedforward neural network,input是一个词汇(把Taipei变成一个vector)
放到这个neural network里面去(你要把一个词汇丢到一个neural network里面去,就必须把它变成一个向量来表示)。
以下是把词汇用向量来表示的方法:

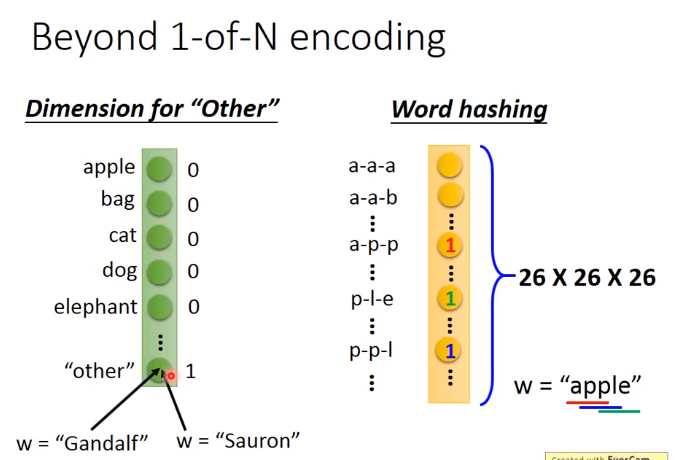

假设把词汇表示为vector,把这个vector丢到feedforward neural network里面去,在这个task里面,你就希望你的output是一个probability distribution。
这个probability distribution代表着我们现在input这词汇属于每一个slot的几率,比如Taipei属于destination的几率和Taipei属于time of departure的几率。

假设现在有一个使用者说:“arrive Taipei on November 2nd”(arrive-other,Taipei-dest, on-other,November-time,2nd-time)。那现在有人说:"leave Taipei on November 2nd",这时候Taipei就变成了“place of departure”,
它应该是出发地而不是目的地。但是对于neural network来说,input一样的东西output就应该是一样的东西(input "Taipei",output要么是destination几率最高,要么就是place of departure几率最高),
你没有办法一会让出发地的几率最高,一会让它目的地几率最高。这个怎么办呢?这时候就希望我们的neural network是有记忆力的。如果今天我们的neural network是有记忆力的,
它记得它看过红色的Taipei之前它就已经看过arrive这个词汇;它记得它看过绿色之前,它就已经看过leave这个词汇,它就可以根据上下文产生不同的output。如果让我们的neural network是有记忆力的话,
它就可以解决input不同的词汇,output不同的问题。
RNN 可以解决这个问题

这种有记忆的neural network就叫做Recurrent Neural network(RNN)。在RNN里面,每一次hidden layer的neuron产生output的时候,这个output会被存到memory里去(用蓝色方块表示memory)。
那下一次当有input时,这些neuron不只是考虑input x1,x2 还会考虑存到memory里的值。对它来说除了 x1,x2以外,这些存在memory里的值 a1,a2也会影响它的output
Example
memory 要有初始值

虽然input一样,但是由于存在memory的值不同,那么output也不同

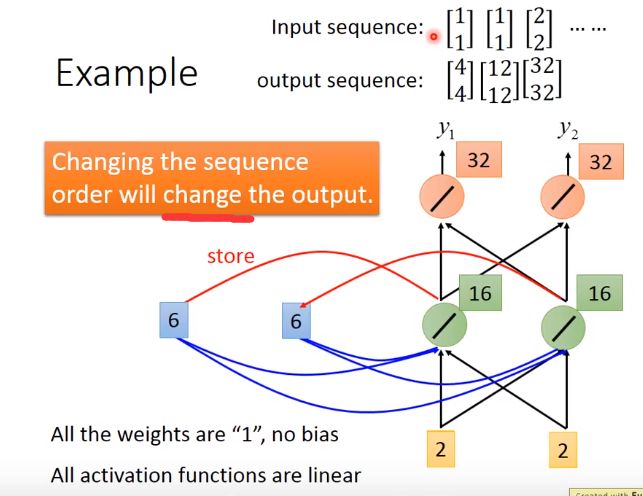
还是之前的例子

虽然都是Taipei,但是一个arrive,是一个是leave


两种RNN

双向RNN


LSTM

刚才讲的memory是最单纯的,我们可以随时把值存到memory去,也可以把值读出来。但现在最常用的memory称之为Long Short-term Memory(长时间的短期记忆)。这个Long Short-term Memory是比较复杂的。
这个Long Short-term Memory是有三个gate,当外界某个neural的output想要被写到memory cell里面的时候,必须通过一个input Gate,那这个input Gate要被打开的时候,你才能把值写到memory cell里面去,
如果把这个关起来的话,就没有办法把值写进去。至于input Gate是打开还是关起来,这个是neural network自己学的.那么输出的地方也有一个output Gate,这个output Gate会决定说,外界其他的neural可不可以
从这个memory里面把值读出来.那跟input Gate一样,output Gate什么时候打开什么时候关闭,network是自己学到的。那第三个gate叫做forget Gate,forget Gate决定说:什么时候memory cell要把过去记得的东西忘掉。这也是network自己学到的。
那整个LSTM你可以看成,它有四个input 1个output,这四个input中,一个是想要被存在memory cell的值(但它不一定存的进去)还有操控input Gate的讯号,操控output Gate的讯号,操控forget Gate的讯号,有着四个input但它只会得到一个output
冷知识:这个“-”应该在short-term中间,是长时间的短期记忆。想想我们之前看的Recurrent Neural Network,它的memory在每一个时间点都会被洗掉,只要有新的input进来,每一个时间点都会把memory 洗掉,所以的short-term是非常short的,但如果是Long Short-term Memory,它记得会比较久一点(只要forget Gate不要决定要忘记,它的值就会被存起来)。

LSTM_example
假设g 和h 都是linear ,cell的初始值为0

当x为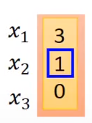 时
时

同理当x 时
时

当x 为  时
时
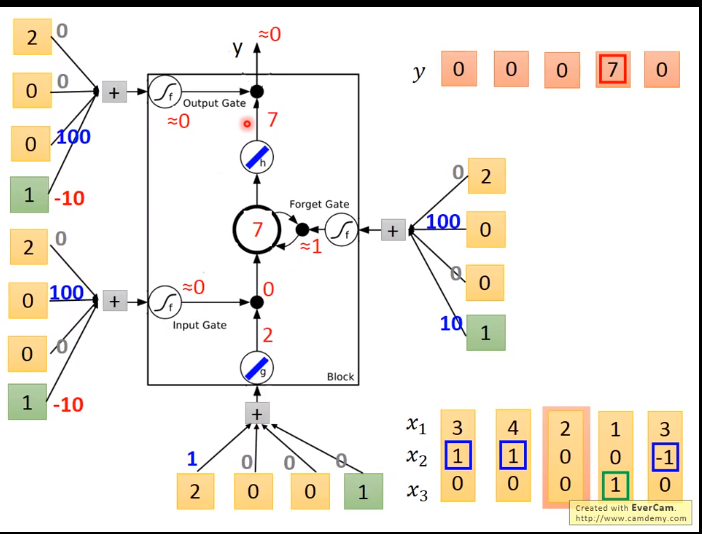
当 x为  时
时

当 x为 时
时

LSTM 和原来Network 的区别


区别:
原来的neuron是1个input,1个output
现在的LSTM是4个input,(是不同的)1个output
那么,LSTM的network需要的参数量是一般network的4倍(neuron的数目一样时)

假设我们现在有一整排的neuron(LSTM),这些LSTM里面的memory都存了一个值,把所有的值接起来就变成了vector,写为
c(t-1)(一个值就代表一个dimension)。现在在时间点t,input一个vector xt,这个vector首先会乘上一matrix(一个linear transform变成一个vector z,
z这个vector的dimension就代表了操控每一个LSTM的input(z这个dimension正好就是LSTM memory cell的数目)。z的第一维就丢给第一个cell(以此类推)
这个xt会乘上另外的一个transform得到zi ,然后这个zi的dimension也跟cell的数目一样,zi 的每一个dimension都会去操控input gate
(forget gate 跟output gate也都是一样,这里就不在赘述)。所以我们把xt 乘以四个不同的transform得到四个不同的vector,四个vector的dimension跟cell的数目一样,
这四个vector合起来就会去操控这些memory cell运作

一个memory cell就长这样,现在input分别就是z,zi,zo,zf (都是vector),丢到cell里面的值其实是vector的一个dimension(一个值),
因为每一个cell input的dimension都是不一样的,(一个是第一维,一个是第二维。。。。)所以每一个cell input的值都会是不一样。所以cell是可以共同一起被运算的,怎么共同一起被运算呢?
zi 通过activation function跟z相乘,zf 通过activation function跟之前存在cell里面的值相乘,
然后将z跟zi相乘的值加上zf跟c(t-1) 相乘的值,zo 通过activation function的结果output,跟之前相加的结果再相乘,最后就得到了output yt

之前那个相加以后的结果就是memory里面存放的值ct,这个process反复的进行,在下一个时间点input x(t+1),把z跟input gate相乘,把forget gate跟存在memory里面的值相乘,然后将前面两个值再相加起来,
在乘上output gate的值,然后得到下一个时间点的输y(t+1)
你可能认为说这很复杂了,但是这不是LSTM的最终形态,真正的LSTM,
会把上一个时间的输出接进来,当做下一+个时间的input,也就说下一个时间点操控这些gate的值不是只看那个时间点的input xt,还看前一个时间点的output ht。其实还不止这样,
还会加一个东西叫做“peephole”,这个peephole就是把存在memory cell里面的值也拉过来。那操控LSTM四个gate的时候,你是同时考虑了x(t+1),ht, ct,你把这三个vector并在一起乘上不同的transform
得到四个不同的vector再去操控LSTM。


LSTM通常不会只有一层,若有五六层的话。大概是这个样子。每一个第一次看这个的人,反映都会很难受。现在还是 quite standard now,
当有一个人说我用RNN做了什么,你不要去问他为什么不用LSTM,因为他其实就是用了LSTM。现在当你说,你在做RNN的时候,其实你指的就用LSTM。Keras支持三种RNN:‘’LSTM‘’,“GRU”,"SimpleRNN"
GRU
GRU是LSTM稍微简化的版本,它只有两个gate,虽然少了一个gate,但是performance跟LSTM差不多(少了1/3的参数,也是比较不容易overfitting)。如果你要用这堂课最开始讲的那种RNN,你要说是simple RNN才行。