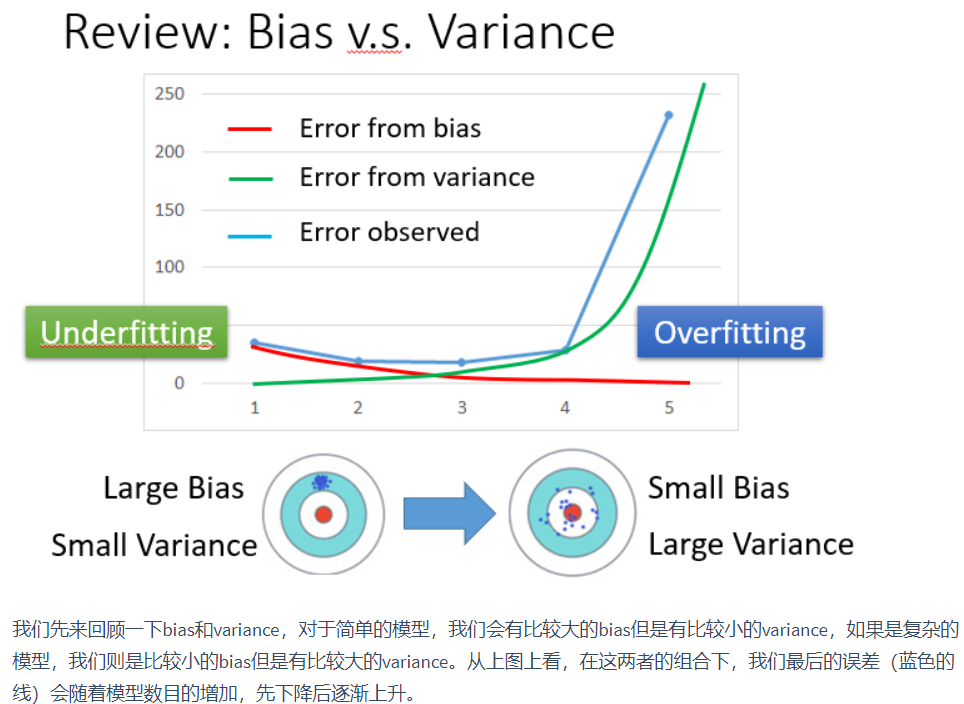
Ensemble的框架

Ensemble的方法就是一种团队合作,好几个模型一起上的方法。
- 第一步:通常情况是有很多的classifier,想把他们集合在一起发挥更强大的功能,这些classifier一般是diverse的,这些classifier有不同的属性和不同的作用。
- 第二步:就是要把classifier用比较好的方法集合在一起,就好像打王的时候坦和DD都站不同的位置,通常用ensemble可以让我们的表现提升一个档次,一般在kaggle之类的比赛中,ensemble用的最多的也是效果最好的,一般前几名都需要用ensemble。
Bagging
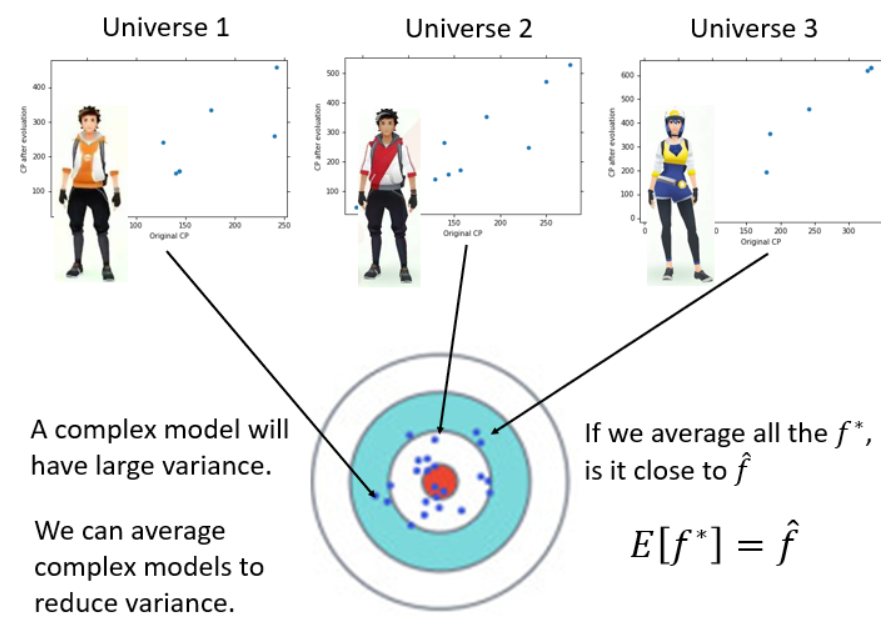

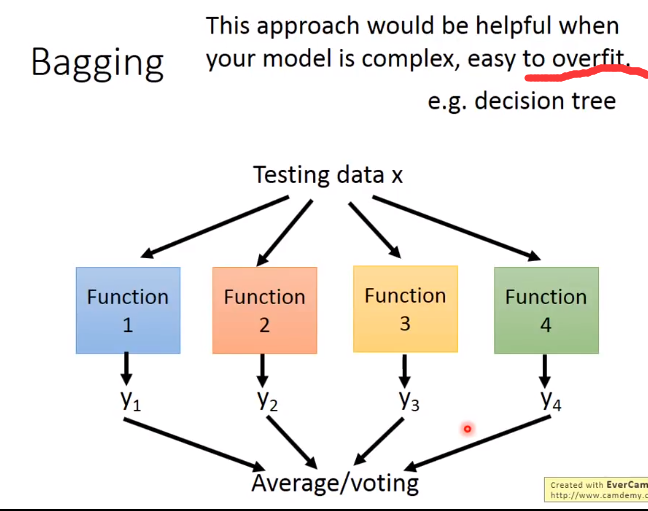
上图表示了用自己采样的数据进行Bagging的过程。在原来的N笔训练数据中进行采样,过程就是每次从N笔训练数据中取N‘(通常N=N’)建立很多个dataset,
这个过程抽取到的可能会有重复的数据,但是每次抽取的是随机形成的dataset。每个dataset都有N'笔data,但是每个dataset的数据都是不一样的,接下来就是用一个复杂的模型对四个dataset都进行学习得到四个function,
接下来在testing的时候,就把这testing data放到这四个function里面,再把得出来的结果做平均(回归)或者投票(分类),通常来说表现(variance比较小)都比之前的好,这样就不容易产生过拟合。
做Bagging的情况:模型比较复杂,容易产生过拟合。(容易产生过拟合的模型:决策树)目的:降低方差
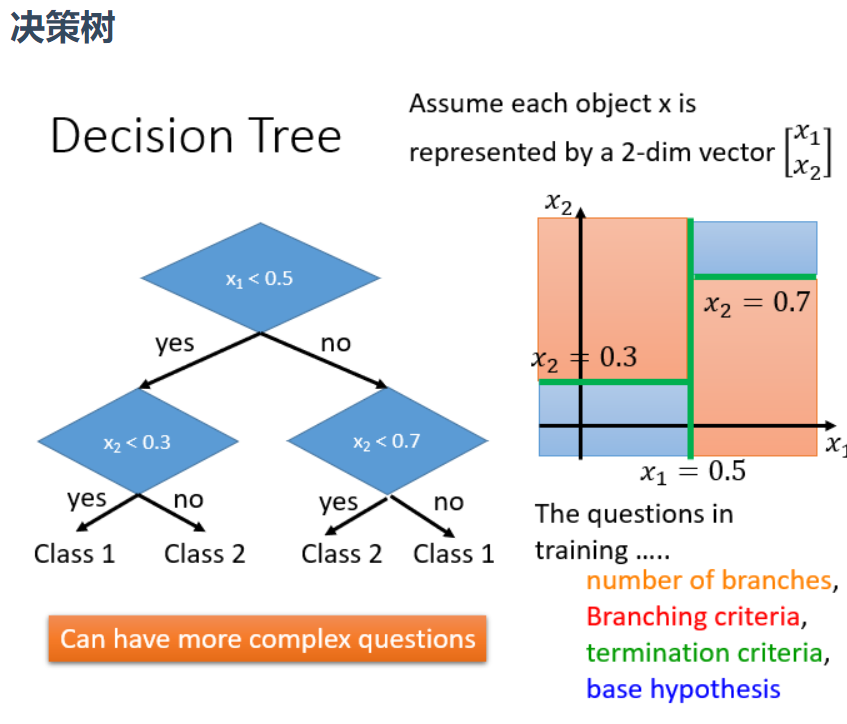
决策树的实际例子:初音问题

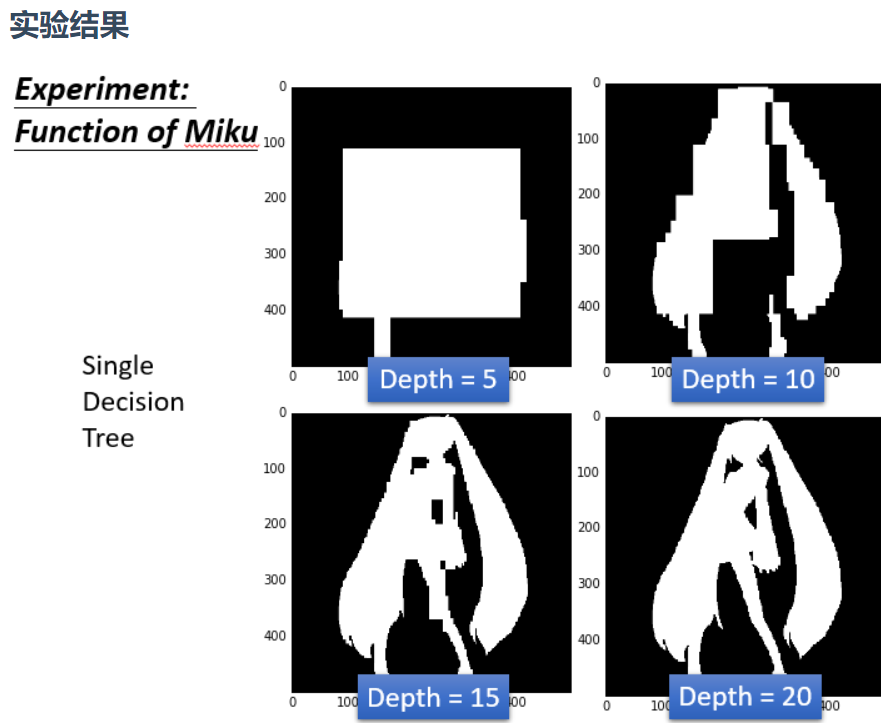
上图可以看到,深度是5的时候效果并不好,图中白色的就是class1,黑色的是class2.当深度是10的时候有一点初音的样子,当深度是15的时候,基本初音的轮廓就出来了,但是一些细节还是很奇怪(比如一些凸起来的边角)
当深度是20的时候,就可以完美的把class1和class2的位置区别开来,就可以完美地把初音的样子勾勒出来了。对于决策树,理想的状况下可以达到错误是0的时候,最极端的就是每一笔data point就是很深的树的一个节点,这样正确率就可以达到100%(树够深,决策树可以做出任何的function)但是决策树很容易过拟合,如果只用决策树一般很难达到好的结果



强调一点是做Bagging更不会使模型能fit data,所有用深度为5的时候还是不能fit出一个function,所有就是5颗树的一个平均,相当于得到一个比较平滑的树。当深度是10的时候,大致的形状能看出来了,当15的时候效果就还不错,但是细节没那么好,当20 的时候就可以完美的把初音分出来。

Boosting是用在很弱的模型上的,当我们有很弱的模型的时候,不能fit我们的data的时候,我们就可以用Boosting的方法
Boosting的训练是有顺序的(sequentially),Bagging是没有顺序的(可以同时train)







权重的更改

下面数学推导d1


那么这个算法的实现过程


错误率低的classifier,arfa(t)大,最后在最终结果的投票上会有比较大的权重
下面举个例子
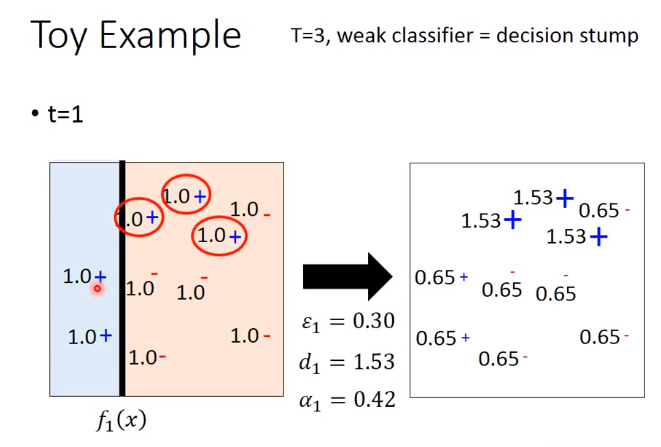
让分类对的权重小些,分类错的权重大些
同理t=2
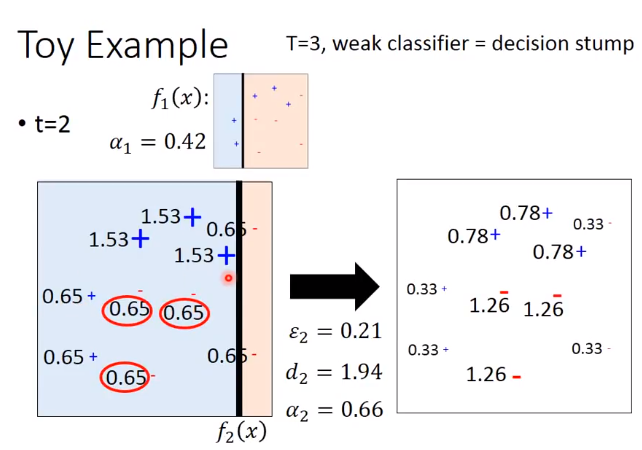


结果整合:这个三个分类器把平面分割成六个部分,左上角三个分类器都是蓝色的,那就肯定就蓝色的。上面中间部分第一个分类器是红色的,第二个第三个是蓝色的,但是后面两个加起来的权重比第一个大,
所以最终中间那块是蓝色的,对于右边部分,第一个第二个分类器合起来的权重比第三个蓝色的权重大,所以就是红色的。下面部分也是按照同样道理,分别得到蓝色,红色和红色。
所以这三个弱分类器其实本事都会犯错,但是我们把这三个整合起来就能达到100%的正确率了。
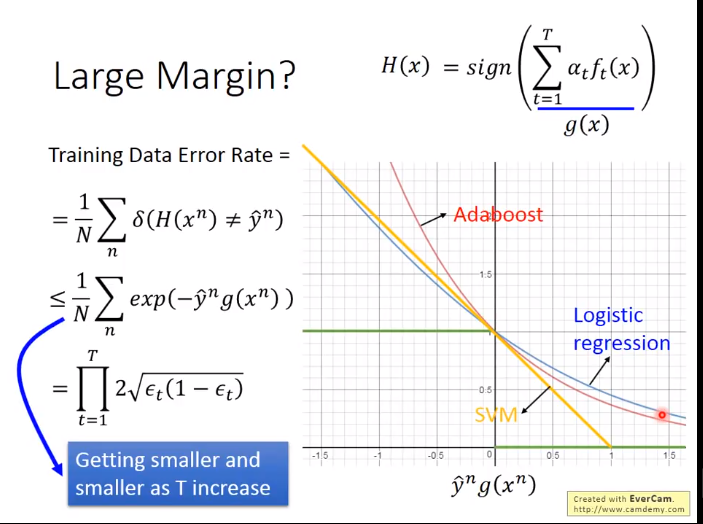
AdaBoost证明推导

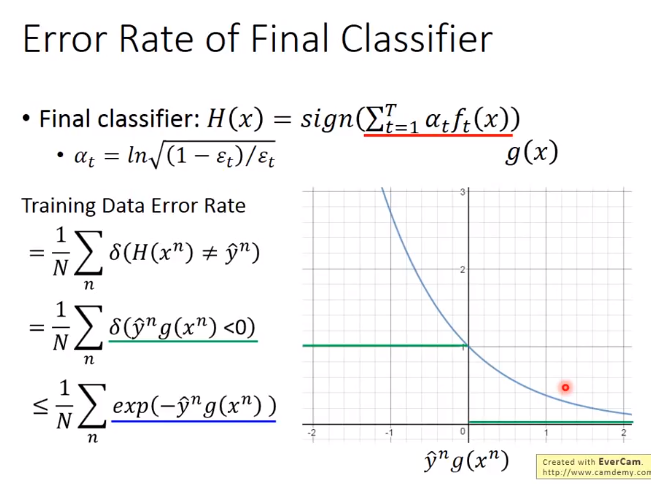

证明上界函数会越来越小



AdaBoost的神秘现象



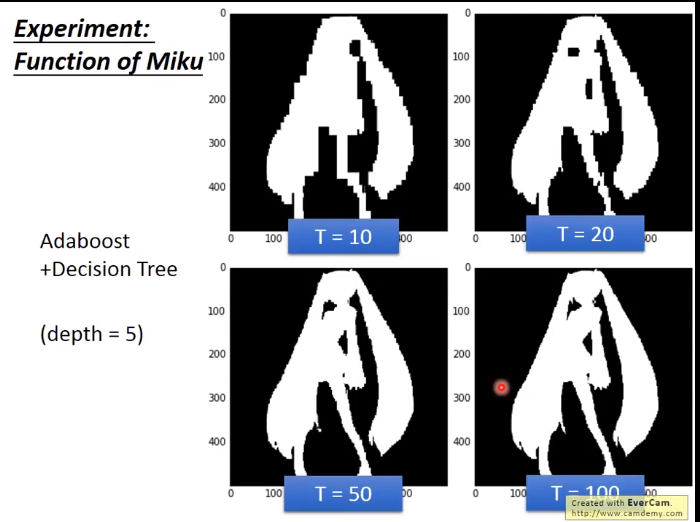
本来深度是5的决策树是不能做好初音的分类(只能通过增加深度来进行改进),但是现在有了AdaBoost的决策树是互补的,所以用AdaBoost就可以很好的进行分类。
T代表AdaBoost运行次数,图中可知用AdaBoost,100棵树就可以很好的对初音进行分类。
Gradient Boosting






Stacking
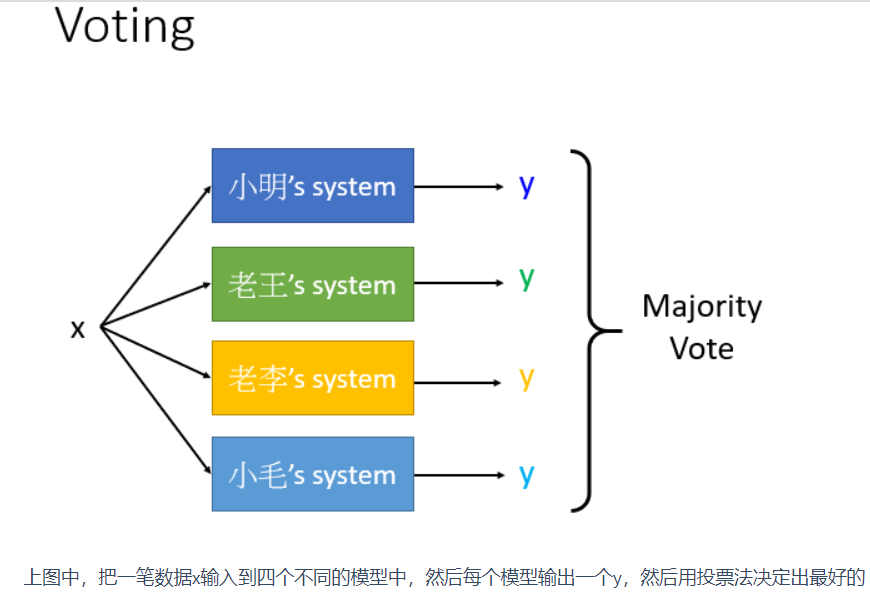

但是有个问题就是并不是所有系统都是好的,有些系统会比较差(如 小毛的系统不好),但是如果采用之前的设置低权重的方法又会伤害小毛的自尊心,
这样我们就提出一种新的方法: 把得到的y当做新的特征输入到一个最终的分类器中,然后再决定最终的结果。 对于这个最终的分类器,应当采用比较简单的函数(比如说逻辑回归),
不需要再采用很复杂的函数,因为输入的y已经训练过了。 在做stacking的时候我们需要把训练数据集再分成两部分,一部分拿来学习最开始的那些模型,另外一部分的训练数据集拿来学习最终的分类器。
原因是有些前面的分类器只是单纯去拟合training data,比如小明的代码可能是乱写的,他的分类器就是很差的,他做的只是单纯输出原来训练数据集的标签,但是根本没有训练。
如果还用一模一样的训练数据去训练最终分类器,这个分类器就会考虑小明系统的功能。所以我们必须要用另外一部分的数据来训练最终的分类器,然后最终的分类器就会给之前的模型不同的权重。