第一节课
有监督学习(supervised learning):训练过程中的数据集均有标签,通常用于分类和回归(连续变量的预测)
半监督学习(semi supervised learning):其训练数据的一部分是有标签的,另一部分没有标签,而没标签数据的数量常常远远大于有标签数据数量。可以用于分类、回归、聚类、降维。
无监督学习(unsupervised learning):所有的数据集都没有标签,通常用于聚类。
强化学习(Reinforcement Learning):强化学习是智能体(Agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏(最大化回报函数)。强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号)。
参考:https://blog.csdn.net/weixin_41036461/article/details/88383529
model:带有未知参数的函数
label、feature、weight、bias
Loss:与weight和bias相关的损失函数
L = (1/n)Σe (默认求平均,pytorch中损失函数的reduction参数(' none ' | 'mean' | ' sum ')默认为mean,none返回一个向量)
MAE(mean absolute error):e = |y - y_hat|
MSE(mean square error):e = (y - y_hat)^2
Cross_entropy:交叉熵函数反应了真实值Y与预测值y各自分布的相似程度,当且仅当预测值 y = 真实值 Y时,交叉熵函数的值取到最小。
error surface:不同参数与Loss的关系图
hyperparameter:人为设定的超参数
parameter:机器学习过程中出现的参数
参数更新


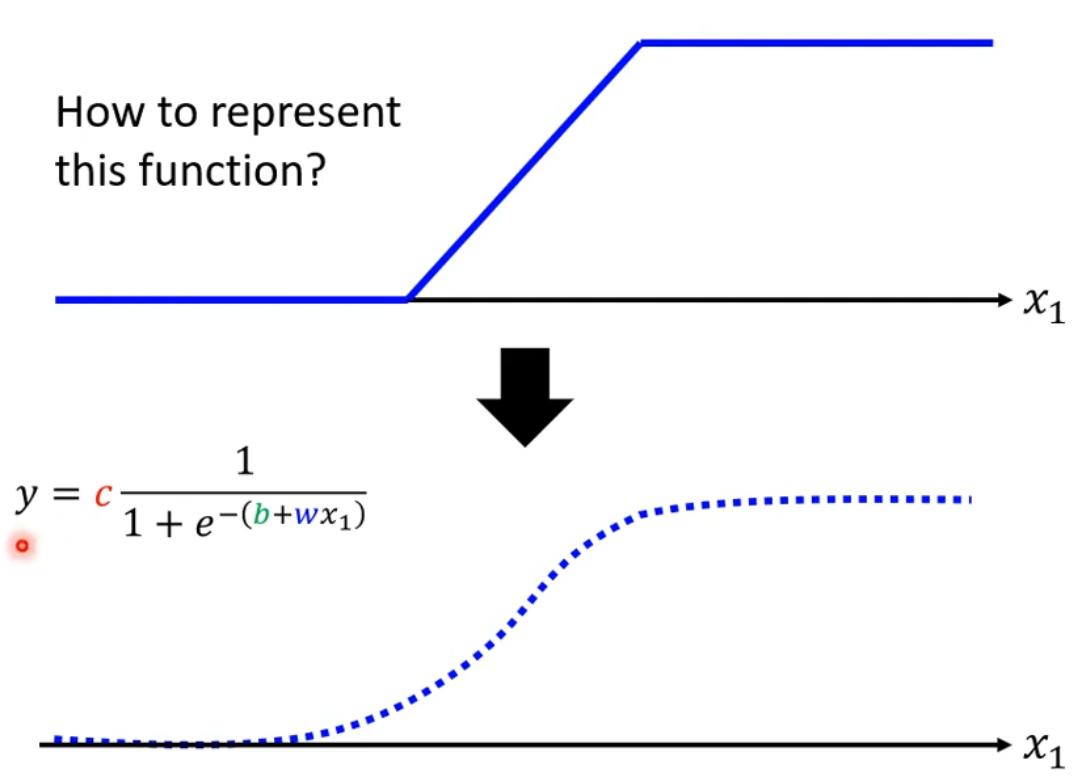
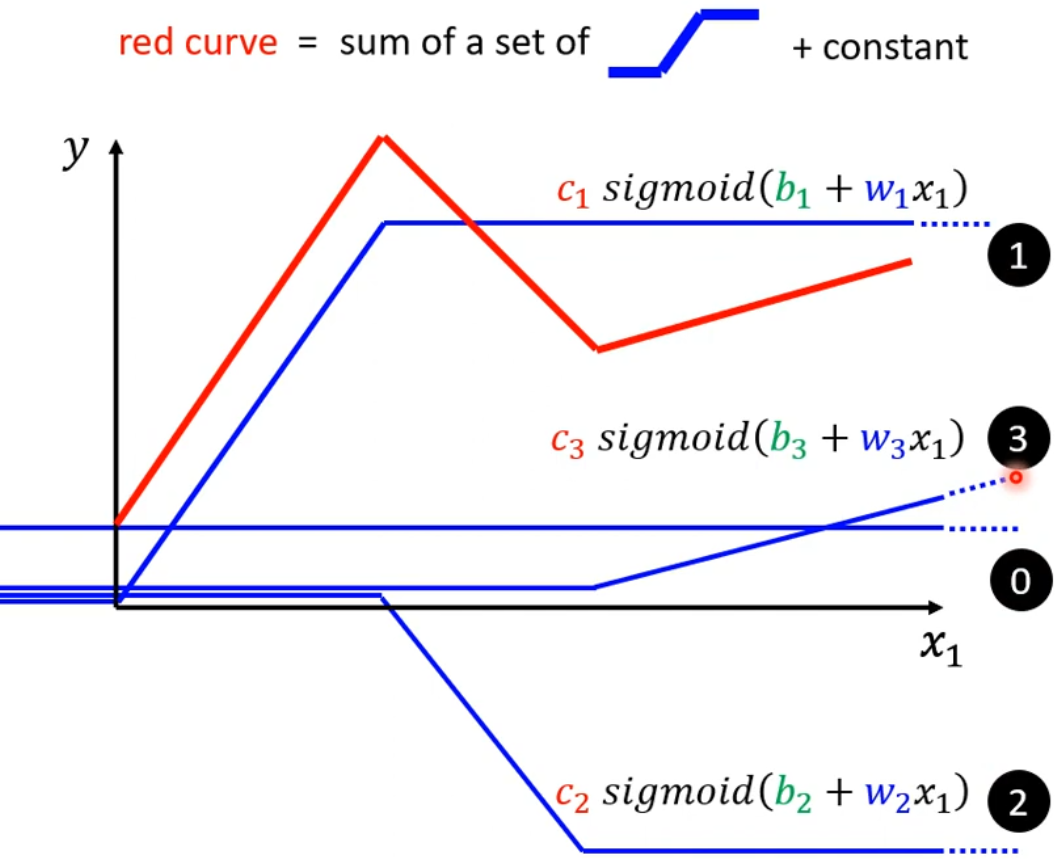
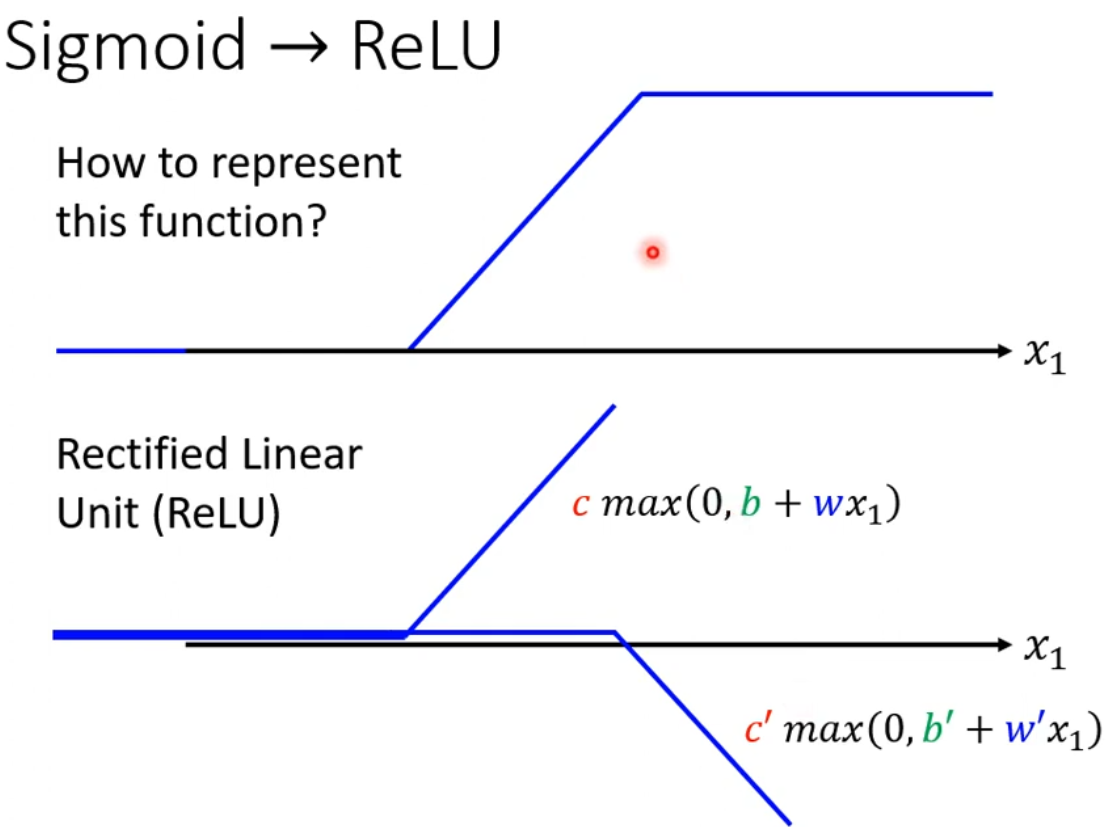
对与较为复杂的数据,单纯的线性函数难以拟合。可以将复杂的model分解为多个线性函数的和(类似于分段函数)。
每一小段的函数可以用sigmoid函数表示。其中c、b、w参数用于调节函数在水平或垂直方向上的移动以及函数的缩放。(将sigmoid函数调整成除了在model对应段上为近似斜线,其余近似为常数,在正无穷为1*c,在负无穷为0)
最后将多个sigmoid函数相加,即可得到最终结果。
【李沐】sigmoid将每个计算的结果进行映射,结果再作为下一个计算的输入进行计算。其目的在于对计算进行非线性化(多个线性计算的任意组合,其结果仍为线性运算)
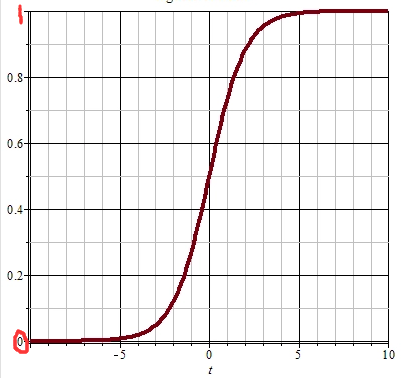
sigmoid
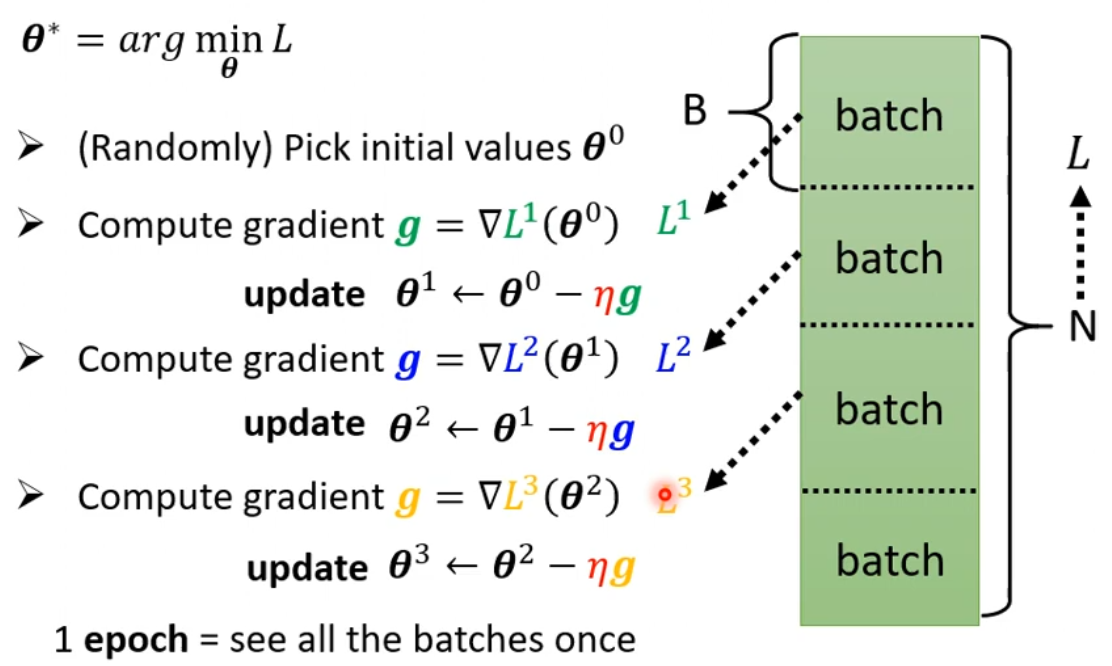
通常在实际操作中,将完整的数据集(数目为N)分为多个Batch(数目为B),每次的update为一个batch的数据参与计算并更新,当所有数据都计算完成后称为一个epoch
hard sigmoid函数可以使用两个ReLu函数替代
sigmoid函数
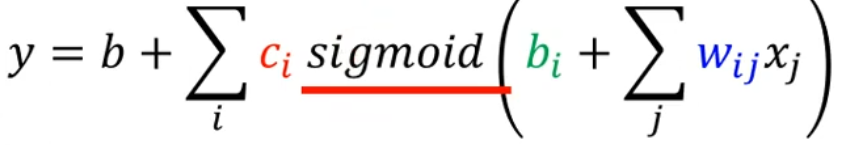
ReLu函数
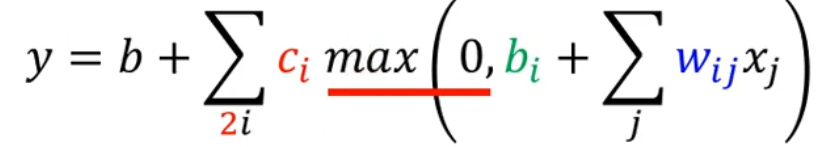
第二节课
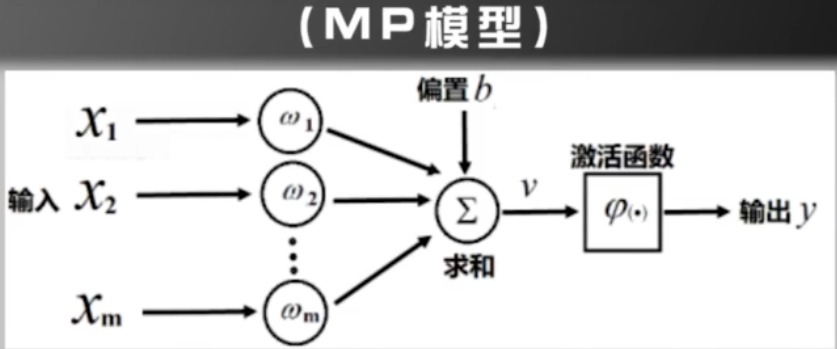
MP模型:按照生物神经元的结构和工作原理构造出来的一个抽象和简化了的模型。
感知器算法
必须保证数据集是线性可分的,则该算法必定收敛。

第三节课
判断模型是否合适
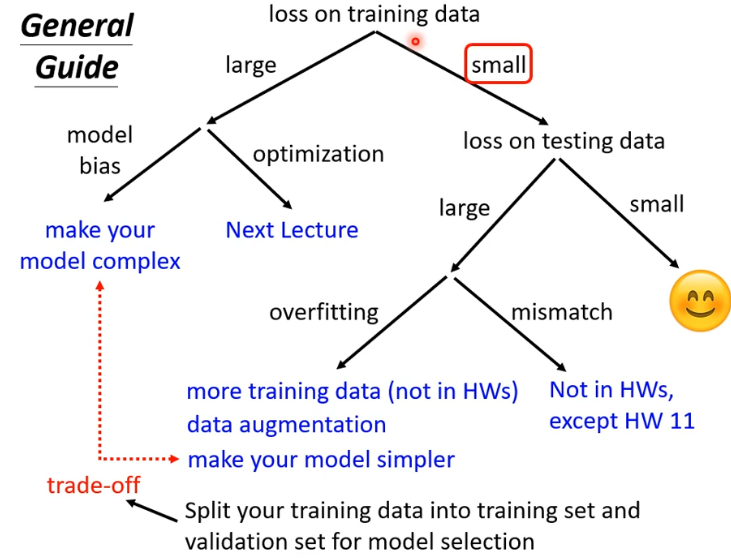
第四节课
当函数在某一点的倒数为0时,该点除了是极值点,也有可能是鞍点。
判断的方式是通过黑塞矩阵(hessian,即函数对任意两个未知数变量的二阶求导组成的矩阵)进行判断。
当hessian矩阵是正定矩阵(对于任意非零向量z,zT M z > 0,M为正定矩阵)时,该点是极小值点,
当hessian矩阵是负定矩阵时,该点是极大值点,
当hessian矩阵是不定矩阵时,该点不是极值点(可能是鞍点)
对hessian矩阵,若存在小于0的特征值,则该参数可以往该特征值对应的特征向量的方向更新。
batch size不同对训练结果的影响
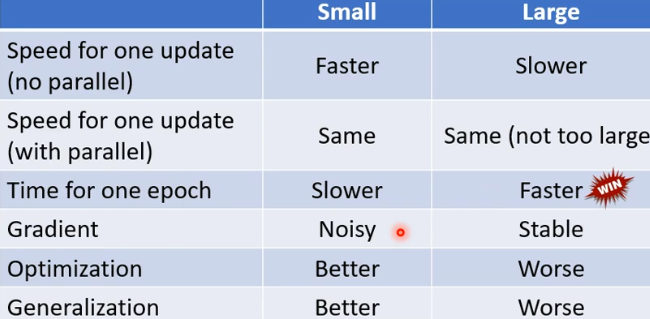
(原因仍然未解)
更好的参数更新方式(momentum)
在原来只往梯度的方向上更新的基础上,添加了momentum(类似于物理世界中的惯性,参数更新时不仅仅取决于梯度,同时也受到之前移动的方向的影响)
m(t) = λm(t-1) - ng 其中λ为超参数,通常为0.9;n为学习率;g为梯度
α(t) = α(t-1) + m(t) α为网络所需要学习的参数
当loss趋于平稳时,可能存在梯度仍然保持较大的值,在某个山谷间不断震荡
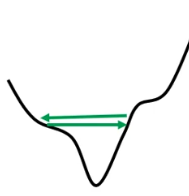
处理方法之一:自动调整学习率
Adagrad: α(t) = α(t-1) - (n/σ)g σ =根号(Σ(g^2)/n) 其中n为学习率,σ为该参数每次更新时计算所得的梯度的均方根(平方和求均值在开根号)
使得不同的参数以及参数在不同时刻的学习率不同。
RMSProp:与Adagrad不同之处在于,该方法的 σ = 根号(a σ(t-1) + (1-a)g^2),其中a是由用户决定,能够自由调整的参数
learning rate schedule:让学习率随着时间的改变而改变
包括learning rate decay(随着时间不断减小) 以及 warm up(先上升再下降)
Adam : RMSProp + momentum + learning rate schedule
cross-entropy : 分类中常用的损失函数,其内部自带有softmax。其本质为极大似然估计。
batch normalization : 在网络的计算过程中,将输入的数据统一做归一化(可以是在任意一层的输入),避免出现当输入的数据发生细微变化时,造成网络较大的震荡。极大加快了训练速度。
在test时,平均值采用moving average计算。