- 目标:爬取猫眼电影排名前一百的数据
源码:
import requests import re def get_one_page(url): headers={"User-Agent":"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"} response = requests.get(url,headers=headers) response.encoding = 'utf-8' if response.status_code == 200: return response.text else: return response.status_code def parse_one_page(html): pattern = re.compile('<dd>.*?board-index.*?>(d+)</i>.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?</dd>',re.S) items = re.findall(pattern, html) for item in items: a=(item[0]+" "+item[1]+" "+item[2].strip()) write_to_file(a) def write_to_file(a): fp=open('result.txt','a',encoding='utf-8') fp.write(a+" ") def main(): for i in range(0,10): j=i*10 url="https://maoyan.com/board/4?offset="+str(j) print(url) html = get_one_page(url) parse_one_page(html) if __name__ == '__main__': main()
- 遇到的问题
1)访问网站时出现中文乱码。
解决办法:查看网页源码找到 charset 找到对应的编码
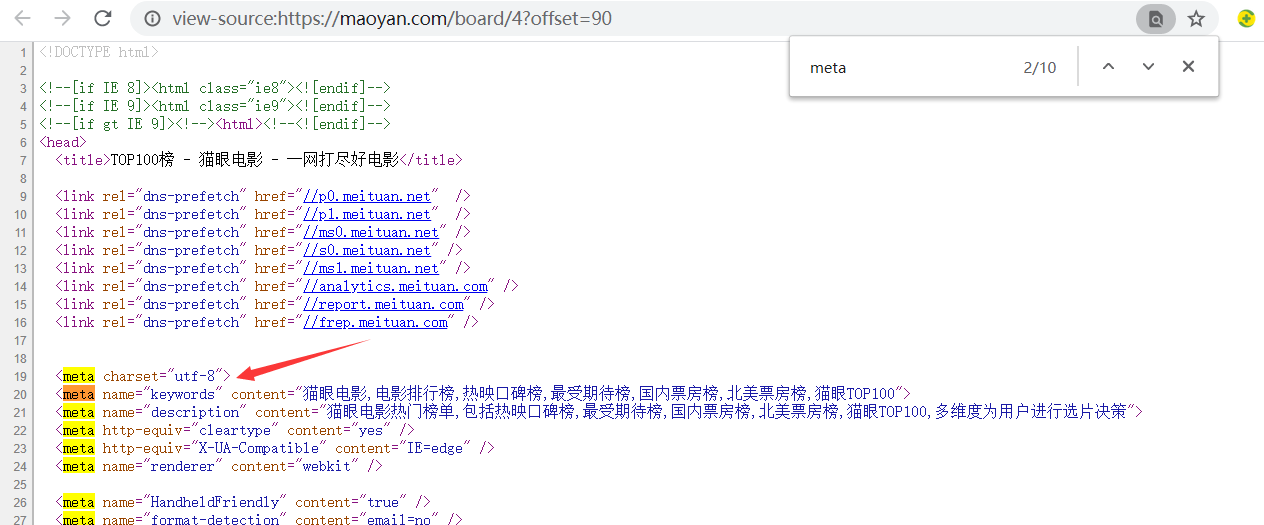
过后设置请求时的 encoding

2)访问网站时被有反爬虫机制,该网站具有UA检测。
解决办法:
添加 user-agent 头

3)写入文件时乱码。
解决办法:

小知识:
如果嫌慢可以利用进程池,但是这里为了排序我没有用,用了进程池回很快,需要添加或者改变的代码如下。
from multiprocessing import Pool
from
def main(offset): url = "https://maoyan.com/board/4?offset="+str(offset) html = get_one_page(url) parse_one_page(html) if __name__ == '__main__': pool = Pool() pool.map(main, [i*10 for i in range(1,10)])
stirp() 去掉空格和回车