04. 卷积神经网络
第二周 深度卷积网络实例分析
2.1 & 2.2 经典网络
经典的卷积神经网络包括:
- LeNet-5
- AlexNet
- VGG
都是从解决分类任务的过程中发展出来的,下面逐个进行介绍。
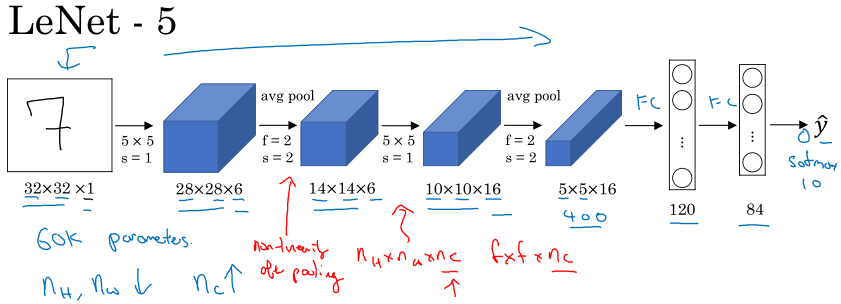
LeNet-5的特点:
网络比较浅,参数量60K左右;一个或几个卷积层后加一个池化层,最后全连接层的设计模式成为典范;没有采用padding;激活函数采用sigmoid,tanh等;采用平均池化;
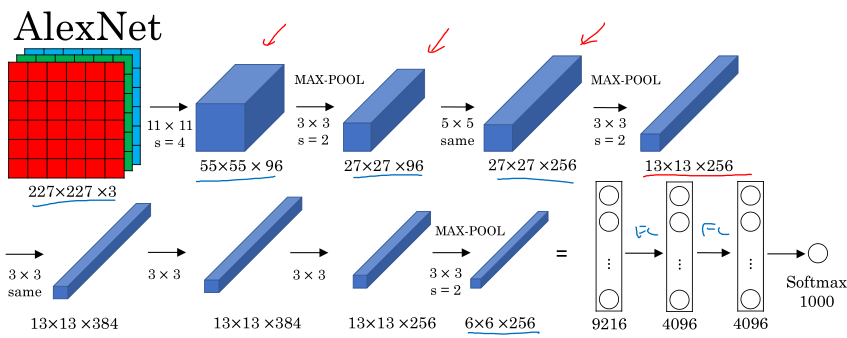
AlexNet的特点:
与LeNet-5比较相似,但是更大,参数量60M左右;采用ReLU激活函数;采用最大池化;多GPU运行;局部响应归一化(没用);
VGG-16的特点:
网络继续加深,参数量138M左右;规范化的设计,超参很少;采用3×3的小卷积核加padding的same卷积;采用2×2,步长为2的最大池化;卷积层使图像的通道数加倍,然后图像的长宽经过池化层减小一半,非常规律,因此很受欢迎;

2.3 & 2.4 残差网络
理论上网络的层数越深,表达能力越强,最后的效果也应该更好,然而实际上越深的网络越难训练,还会出现网络越深、效果越差的情况。ResNet的出现解决了这个问题,其中的关键就是shortcut(捷径)或者叫skip connection(跳连)。
首先是残差块(residual block),每两个卷积层加一个跳连构成一个残差块:

注意:
- 以普通神经网络为例进行说明,表达式为:( a^{[l+2]} = g(z^{[l+2]} + a^{[l]}) ) 或 ( a^{[l+2]} = g(z^{[l+2]} + W_s a^{[l]}) )
- 跳连是接到第二个卷积层的激活函数之前,与主路上的特征图按通道进行相加,为了保证这一点,因此卷积都是same卷积,如果通道数不同,还要通过卷积操作来调整通道数。
将这些残差块堆叠起来就构成了残差网络:

残差网络成功的原因在于通过跳连结构使网络能够更容易的学习恒等映射:
我们原本的想法是,当网络加深时,如果增加的层数没用,完全可以通过学习一个恒等映射来解决,所以出现网络越深效果越差说明网络在学习恒等映射时可能出了问题。而跳连结构所实现的,首先是确保网络最差可以学习到恒等映射,然后只要网络学习到一点有用的东西,效果就应该更好。
2.5 1×1卷积
看似没用,实际上:
1×1卷积可以改变通道数,因此可以用来降维;而且卷积层的非线性激活函数可以增强模型的表达能力。
2.6 & 2.7 Inception网络
在设计卷积网络时有大量的超参数需要选择,比如每一层的卷积核尺寸,是否需要池化等等,然后你就会很自然的去想:小孩子才做选择,我全都要……所以Inception网络诞生了!
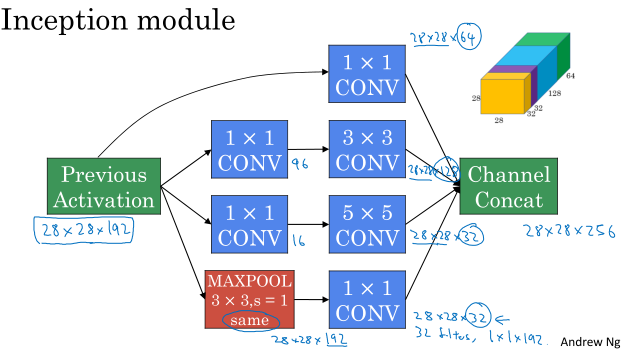
Inceptioin网络的每一层提供多种尺寸的卷积核,让它们各自独立进行卷积运算,然后把所有结果拼在一起,这样就不用做选择了,你网络想要什么都在这里挑就可以了……
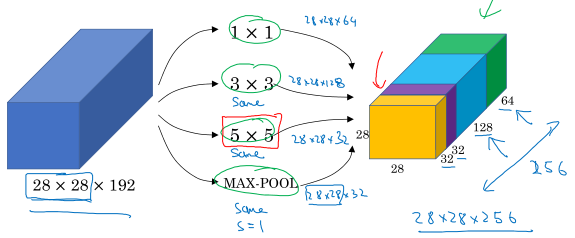
如上图,为了最后能够进行channel concatenation,所有卷积、池化都通过padding保证尺寸不变。
其中还是有几个小问题:
- 5×5的卷积运算量太大。
注意啊,我们前面讲了怎么计算参数量,而这里的问题是运算量太大。运算量怎么计算呢?
只考虑乘法操作:从每个卷积层的输出去考虑,因为输出的每一个值都对应一次卷积运算,所以对于输出尺寸28×28×32、每个卷积核尺寸为5×5×192的卷积层,乘法的运算量为( (28 imes 28 imes 32) imes (5 imes 5 imes 192) approx 120M ).
为了减小运算量,就需要用到前面提到的1×1卷积:
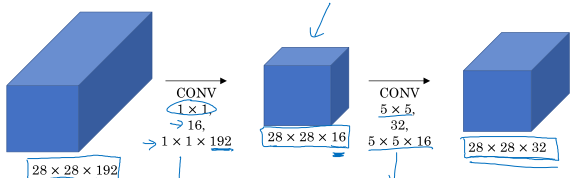
先用1×1卷积减少通道数,然后再进行5×5卷积,这样计算量为( [28 imes 28 imes 16 imes 192] + [28 imes 28 imes 32 imes 5 imes 5 imes 16] approx 12.4M ).
这样运算量就降下来了,中间这个结构也叫做瓶颈(bottleneck)。
- 池化层并不能减少通道数。
如果不处理,输出中大部分通道都将被池化的输出占据。解决方法也是通过在后面加一个1×1卷积运算。
解决了问题之后,就得到了原始版本的Inception模块:
将这种模块堆叠起来就可以得到Inception网络了,还有个更巧妙的名字:GoogLeNet。不过这只是Inception v1,后面还有v2, v3, v3+等改进版本,不在赘述。
2.8 开源实现方案
如何从github上抄码子……
2.9 迁移学习
不仅要下载别人的码子,还要下载人家训好的权重。
如果你自己的数据很少,那么只需重新训练最后一层的参数;
如果你有更多的数据,那么你可以固定更少的层数,训练更多的层数;
如果你有非常多的数据,那么你可以只用人家的权重作初始化,训练整个模型;
2.10 数据扩充
这个之前也说过,不过对于计算机视觉好像比较重要。
图片翻转、随即裁剪、改变颜色等方法进行扩充。
2.11 计算机视觉现状
吴恩达老师讲了自己的一些理解,我觉得很有道理。
机器学习中知识的来源主要有两个:
- 有标记的数据
- 手工设计的网络结构
当你的任务数据不够时,就要花费时间来精心设计网络结构。而计算机视觉领域的各种任务普遍数据不够,这也是为什么各种稀奇古怪的模型、组件层出不穷的原因。
随着数据增多,网络结构的设计可能真的回归“大道至简”了!
再有就是吴恩达老师还是比较偏工程的,比较注重实际应用情况,鄙视那些刷benchmark/竞赛的技巧,他感觉花里胡哨的不实用。比如ensembling和multi-crop at test time.
关于这两个还是要多说几句,以前的理解似是而非:
- 集成(ensembling)是初始化多个模型,然后分别训练,最后输出结果进行平均(不是模型参数平均)。
- Multi-crop的意思是,测试数据作类似数据增强的处理,然后用平均后的测试结果作为最终结果。