主要内容:
- 付费IP的使用方式
- Auth认证
- cookie登录验证
- requests模块
一、付费IP使用方式:
1.1 无论是免费IP还是付费IP,在使用之前,都需要测试一下,如果好使,再去使用IP爬取数据。
1.2 IP池:列表套字典
eg:[{"https": "IP1:端口1"}, {"http": "IP2: 端口2"}, {"https": "IP3: 端口3"}]
1.3 遍历IP池,利用遍历出来的IP创建IP处理器,再利用处理创建发送网络请求的opener对象
1.4 opener.open()中有一个参数timeout=x,即:x秒之后如果程序还没有反应,就算做超时,报超时,x默认为30
1.5 利用异常处理IP值不好用的报错或者超时
代码:
1 import urllib.request 2 3 爬取百度首页"https://www.baidu.com/" 4 def proxy_user(): 5 #1.目标网页URL 6 url = "https://www.baidu.com/" 7 #2. User-Agent 8 user_agent = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"] 9 request = urllib.request.Request(url) 10 request.add_header("User-Agent", user_agent[0]) 11 #3. 代理IP池 12 #3.1 创建代理IP池 13 #IP池结构是:列表套字典 14 proxy_ip_list = [{"HTTP": "58.253.152.23:9999"}, {"HTTP": "112.87.68.242:9999"}, {"HTTP": "60.13.42.99:9999"}] 15 #3.2 遍历IP 16 for choose__proxy_ip in proxy_ip_list: 17 #3.3 利用遍历出来的IP创建IP处理器 18 proxy_ip_handler = urllib.request.ProxyHandler(choose__proxy_ip) 19 #3.4 利用处理器创建opener对象 20 opener = urllib.request.build_opener(proxy_ip_handler) 21 #3.5 发送网络请求 22 #利用异常处理+timeout参数,处理IP失效问题 23 #如果IP使用异常,或者超过timeout设置时间, 24 #则抛出异常,暂停使用当前IP,接着使用下一个IP 25 try: 26 #使用opener.open()发送网络请求, 27 #超时参数timeout设置为10,超过10秒未响应,视为超时 28 response = opener.open(request, timeout = 10) 29 except Exception as e: 30 #如果IP使用异常,或者超时,打印异常信息 31 print(e) 32 33 34 proxy_user()

查看结果,发现当上一个IP不好用时,程序会自动使用下一个IP
2. 付费IP的两种写法:
2.1 写法1:发送付费的代理IP请求
(1)创建代理IP池
(2)创建handler处理器
(3)创建opener对象
(4)发送网络请求
注意:付费代理IP需要有:1. 购买时的用户名 2. 购买时的密码
代理IP池结构:列表套字典
其中字典结构:{"协议类型": "username: password@IP地址:端口号"}
1 import urllib.request
2
3 #付费代理IP第一种写法:
4 def money_proxy_user():
5 #url = "http://www.baidu.com/"
6
7 #1. IP池
8 #结构:{"http/https": "username:pwd@IP:端口号"}
9 money_proxy_list = [{"http": "abc:123@58.253.152.23:9999"},
10 {"http": "abc:123@112.87.68.242:9999"},
11 {"http": "abc:123@60.13.42.99:9999"}]
12 #遍历IP
13 for proxy_ip in money_proxy_list:
14 #2. 创建代理IP处理器handler
15 ProxyHandler = urllib.request.ProxyHandler(proxy_ip)
16 #3. 创建opener对象
17 opener = urllib.request.build_open(ProxyHandler)
18 #4. 发送网络请求
19 response = opener.open(url)
2.2 付费IP第二种写法:使用密码管理器(推荐)
(1)创建IP池
(2)创建密码管理器
(3)向密码管理器中,添加用户名和密码
(4)创建处理器
(5)创建opener对象
(6)opener对象发送网络请求
1 import urllib.request
2
3 #付费代理IP第二种写法:
4 def money_proxy_user():
5 url = "http://www.baidu.com/"
6
7 #1. 创建IP池
8 #结构:{"http/https": "IP值:端口号"}
9 money_proxy_list = [{"http": "58.253.152.23:9999"},
10 {"http": "112.87.68.242:9999"},
11 {"http": "60.13.42.99:9999"}]
12 #遍历IP
13 for proxy_ip in money_proxy_list:
14 #2. 创建密码管理器
15 #密码管理器需要购买IP的用户名和密码
16 user_name = "abc"
17 password = "123"
18 pass_word_manager = urllib.request.HTTPPasswordMgrWithDefaultRealm()
19 #3. 向密码管理器添加用户名和密码
20 pass_word_manager.add_password(None, proxy_ip, user_name, password)
21 #4. 创建handler处理器
22 money_proxy_handler = urllib.request.ProxyBasicAuthHandler(pass_word_manager)
23 #5. 创建opener对象
24 opener =urllib.request.build_opener(money_proxy_handler)
25 #6. 发送请求
26 response = opener.open(url)
27
注意:
1. 密码管理器对象,添加用户名和密码的方法:'
add_password(Realm, uri, user_name, password)
第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None
参数uri:填写代理IP!!!
user_name:付费IP用户名
password:付费IP密码
2. 本方式中,如果程序中提供的代理IP全部都不能使用,程序会使用本地IP
二、Auth认证:
使用范围:
(1)爬取公司内网数据
(2)通过第三方认证的方式(如:微信账号登录),进行爬取
方法:使用密码管理器
代码:
1 import urllib.request
2
3 def auth_user():
4 #1. 给出内网账号和密码
5 user_name = "abc"
6 pwd = "123"
7 #2. 内网的URL地址
8 nei_url = "xxx"
9
10 #3. 创建密码管理器
11 pwd_manager = urllib.request.HTTPPasswordMgrWithDefaultRealm()
12 #4. 向密码管理器中,添加用户名和密码
13 #注意此时,add_password()的第二个参数要访问的目标网页URL地址
14 pwd_manager.add_password(None, nei_url, user_name, pwd)
15
16 #5. 创建处理器Handler
17 auth_handler = urllib.request.HTTPBasicAuthHandler(pwd_manager)
18 #6. 创建opener对象
19 opener = urllib.request.build_opener(auth_handler)
20
21 #7. 发送网络请求:
22 response = opener.open(nei_url)
2.5:SSL爬虫报错:SSL: CERTIFICATE_VERIFY_FAILED
当使用urllib.request.urlopen()向https网页发送网络请求时,有时会报这个错误:
urllib2.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:581)
解决方法:导入ssl模块和如下代码,即可解决
1 import ssl
2
3 ssl._create_default_https_context = ssl._create_unverified_context
三、Cookie与登录信息:
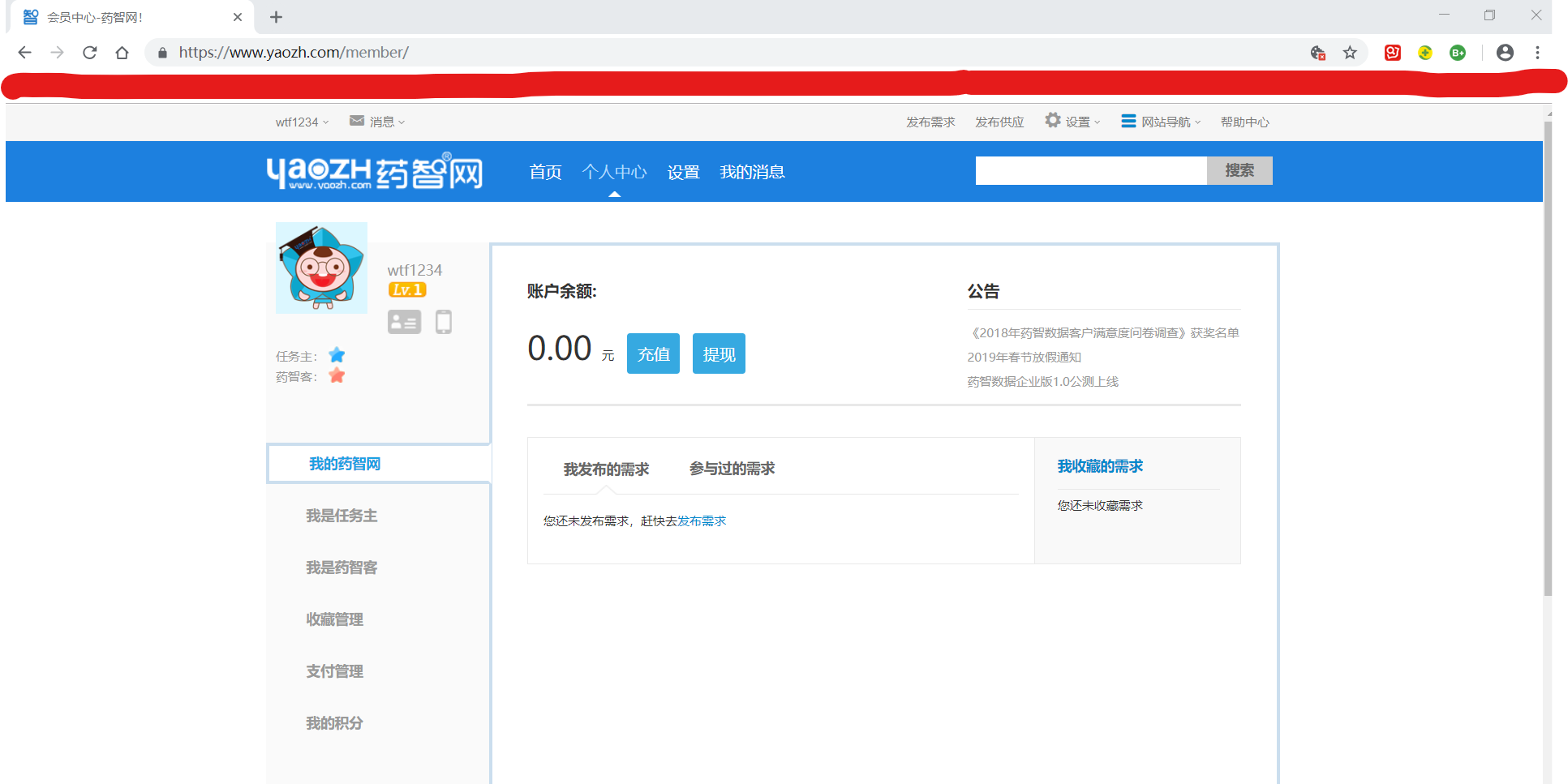
目标:爬取药智网的会员中心页面数据
URL:https://www.yaozh.com/member/
目标网页截图:
3.1 第一次爬取:
1 import urllib.request
2 import ssl
3
4 #忽略SSL验证
5 ssl._create_default_https_context = ssl._create_unverified_context
6
7 #1. 目标网页URL
8 url = "https://www.yaozh.com/member/"
9
10 #2. User-Agent
11 #2.1 创建request对象
12 request = urllib.request.Request(url)
13 #2.2 User-Agent池
14 user_agent_headers = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"]
15 #2.3 向request对象添加User-Agent
16 request.add_header("User-Agent", user_agent_headers[0])
17
18 #也可以直接在创建request对象时,添加User-Agent
19 #request = urllib.request.Request(url, headers=user_agent_headers[0])
20
21
22 #3. 代理IP
23 #3.1 代理IP池
24 proxy_ip = {"https": "60.13.42.101:9999"}
25 #3.2 创建自定义处理器handler
26 proxy_handler = urllib.request.ProxyHandler(proxy_ip)
27 #3.3 创建自定义opener对象
28 opener = urllib.request.build_opener(proxy_handler)
29
30
31 #4. 发送网络请求
32 response = opener.open(request)
33
34 #5. 读取返回的数据
35 data = response.read().decode('utf-8')
36
37 #6. 数据持久化
38 with open("yaozh01.html", 'w', encoding='utf-8') as f:
39 f.write(data)
得到结果:
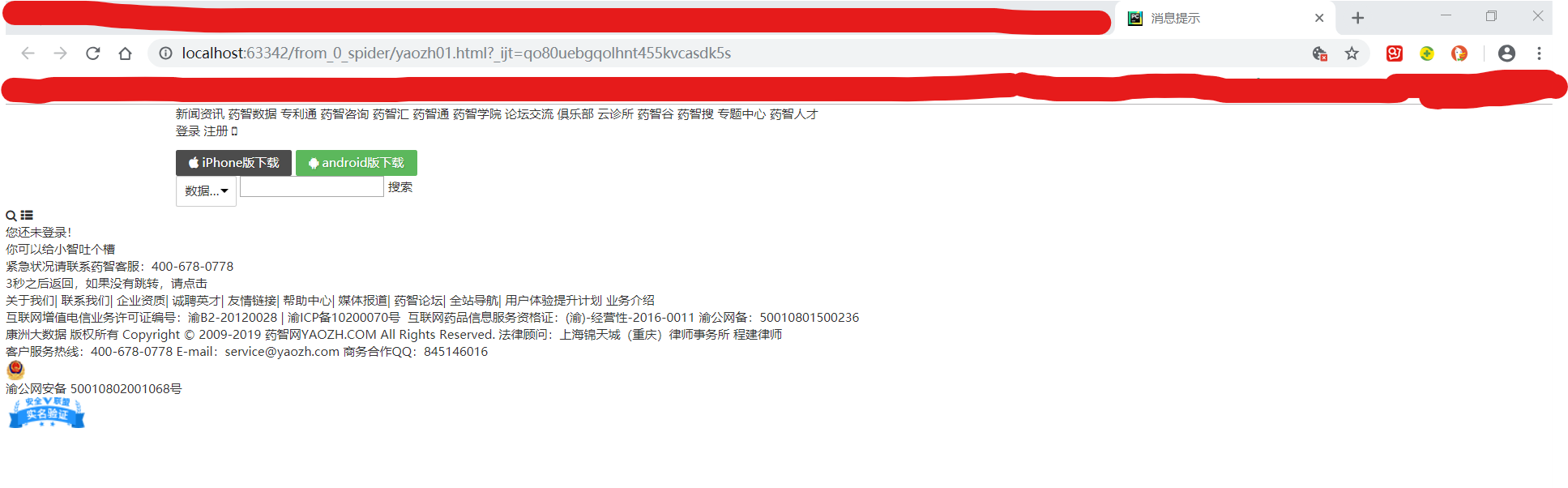
结果,个人中心页面未登录
——(1)原因:登录需要账号信息:用户名和密码
但是,爬虫代码中,没有这两个信息
——(2)解决方法:向请求头中,添加cookie
因为,所有的个人信息,包括:账号和密码都保存在cookie中。
一旦用户登录成功,其账号和密码就会自动保存在cookie中。
而cookie位于请求头中。
——(3)所以,我们需要先登录成功一次,获取cookie,然后,将cookie添加到请求头中。这样,以后爬虫代码发送网络请求登录时,就可以自动使用第一次登陆成功后,保存下来的cookie,使用它里面的账号信息。
3.2 方式1:手动获取添加cookie:
(1)手动登录账号,进入个人中心页面
(2)f12,进入network,查看请求头request_headers
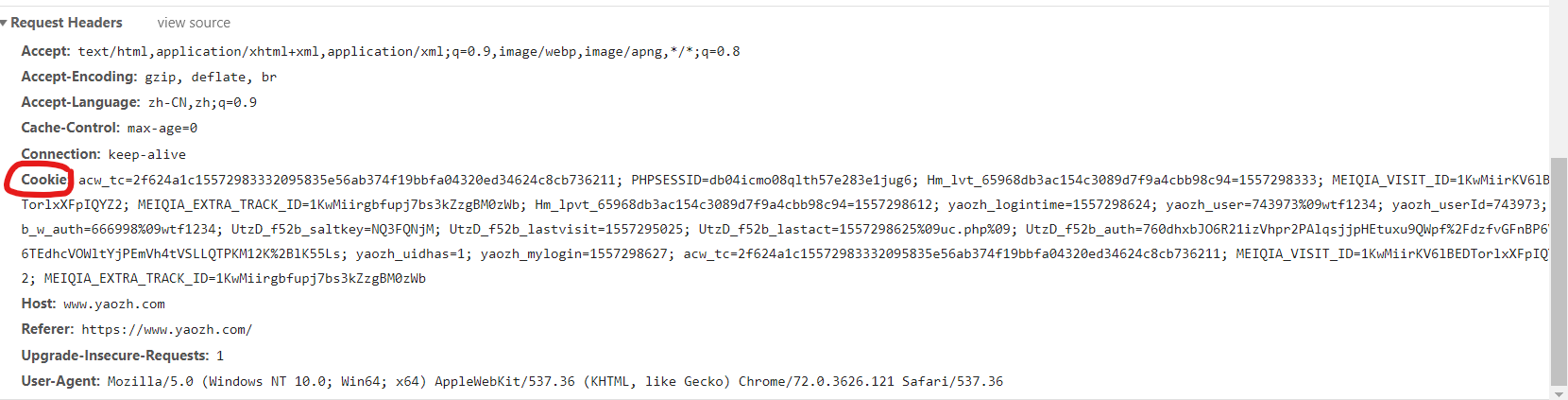
(3)如图所示,将cookie后面的所有信息全部复制粘贴,添加进请求头
(4)发送网络请求
1 import urllib.request
2 import ssl
3
4
5 #爬取药智网会员中心界面
6 #"https://www.yaozh.com/member/"
7
8 #忽略SSL验证
9 ssl._create_default_https_context = ssl._create_unverified_context
10
11 #1. 目标网页URL
12 url = "https://www.yaozh.com/member/"
13
14 #2. 请求头信息
15 #User-Agent、Cookie
16 #手动填写用户名和密码,进行登录,登陆成功之后,在会员中心页面,f12查看请求头信息,复制User-Agent和Cookie信息
17 user_agent = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
18 "Cookie": "acw_tc=2f624a1c15572983332095835e56ab374f19bbfa04320ed34624c8cb736211; PHPSESSID=db04icmo08qlth57e283e1jug6; Hm_lvt_65968db3ac154c3089d7f9a4cbb98c94=1557298333; MEIQIA_VISIT_ID=1KwMiirKV6lBEDTorlxXFpIQYZ2; MEIQIA_EXTRA_TRACK_ID=1KwMiirgbfupj7bs3kZzgBM0zWb; Hm_lpvt_65968db3ac154c3089d7f9a4cbb98c94=1557298612; yaozh_logintime=1557298624; yaozh_user=743973%09wtf1234; yaozh_userId=743973; db_w_auth=666998%09wtf1234; UtzD_f52b_saltkey=NQ3FQNjM; UtzD_f52b_lastvisit=1557295025; UtzD_f52b_lastact=1557298625%09uc.php%09; UtzD_f52b_auth=760dhxbJO6R21izVhpr2PAlqsjjpHEtuxu9QWpf%2FdzfvGFnBP6V66TEdhcVOWltYjPEmVh4tVSLLQTPKM12K%2BlK55Ls; yaozh_uidhas=1; yaozh_mylogin=1557298627; acw_tc=2f624a1c15572983332095835e56ab374f19bbfa04320ed34624c8cb736211; MEIQIA_VISIT_ID=1KwMiirKV6lBEDTorlxXFpIQYZ2; MEIQIA_EXTRA_TRACK_ID=1KwMiirgbfupj7bs3kZzgBM0zWb"
19 }
20 #2.2 创建request对象,并添加User-Agent
21 request = urllib.request.Request(url, headers=user_agent)
22
23
24 #3. 代理IP
25 #3.1 代理IP,IP池
26 proxy_ip = {"https": "115.159.155.60:8118"}
27 #3.2 创建自定义处理器对象handler
28 proxy_handler = urllib.request.ProxyHandler(proxy_ip)
29 #3.3 创建自定义opener对象
30 opener = urllib.request.build_opener(proxy_handler)
31
32
33 #4. 发送网络请求,登录
34 response = opener.open(request)
35 #5. 读取返回数据
36 data = response.read().decode('utf-8')
37
38 #6. 数据持久化
39 with open("yaozhi02.html", "w", encoding='utf-8') as f:
40 f.write(data)
结果:

可以看到,在本机启动的网页会员中心,这次有了用户名,说明登录成功。
———手动获取cookie的缺点:(1)麻烦;(2)获取的cookie有时效性
3.3 方式2:使用代码自动获取cookie(重点):
目标:自动获取(登陆后的)会员中心页面
难点:获取cookie,即:获取登录所需用户名和密码。由于在登录成功之后,Cookie会被自动保存,所以,要想获取Cookie,先要登录成功。
登录页面login和会员中心页面member是两个不同的页面,所以需要我们现在login页面登录成功,然后拿着cookie,去请求member页面
步骤:
(1)自动登录(但需要自己手动设置用户名和密码),登录成功之后,会自动保存Cookie
(2)代码自动获取Cookie
(3)带着cookie,代码请求会员中心页面,获取会员中心数据
———————————分割线—————————————————————
(1)为了能让程序自动登录,我们需要查看,登录过程中,浏览器都向服务器提交了哪些数据
由于登录过程为:
- 浏览器向服务器提交登录数据
- 服务器验证数据
- 服务器向浏览器发送新的跳转页面的链接
- 浏览器按照跳转页面的链接,向服务器重新发送请求
所以,在登录页面,点击“登录”按钮之后,页面会跳转到新的页面。此时浏览器network抓取到的数据,是第4步:浏览器向服务器按照跳转页面URL,向服务器发送请求时,的数据;而不是第1步:浏览器向服务器提交的登录数据。因为谷歌浏览器会只保留最新一次请求的数据,而将之前的请求抹除了。
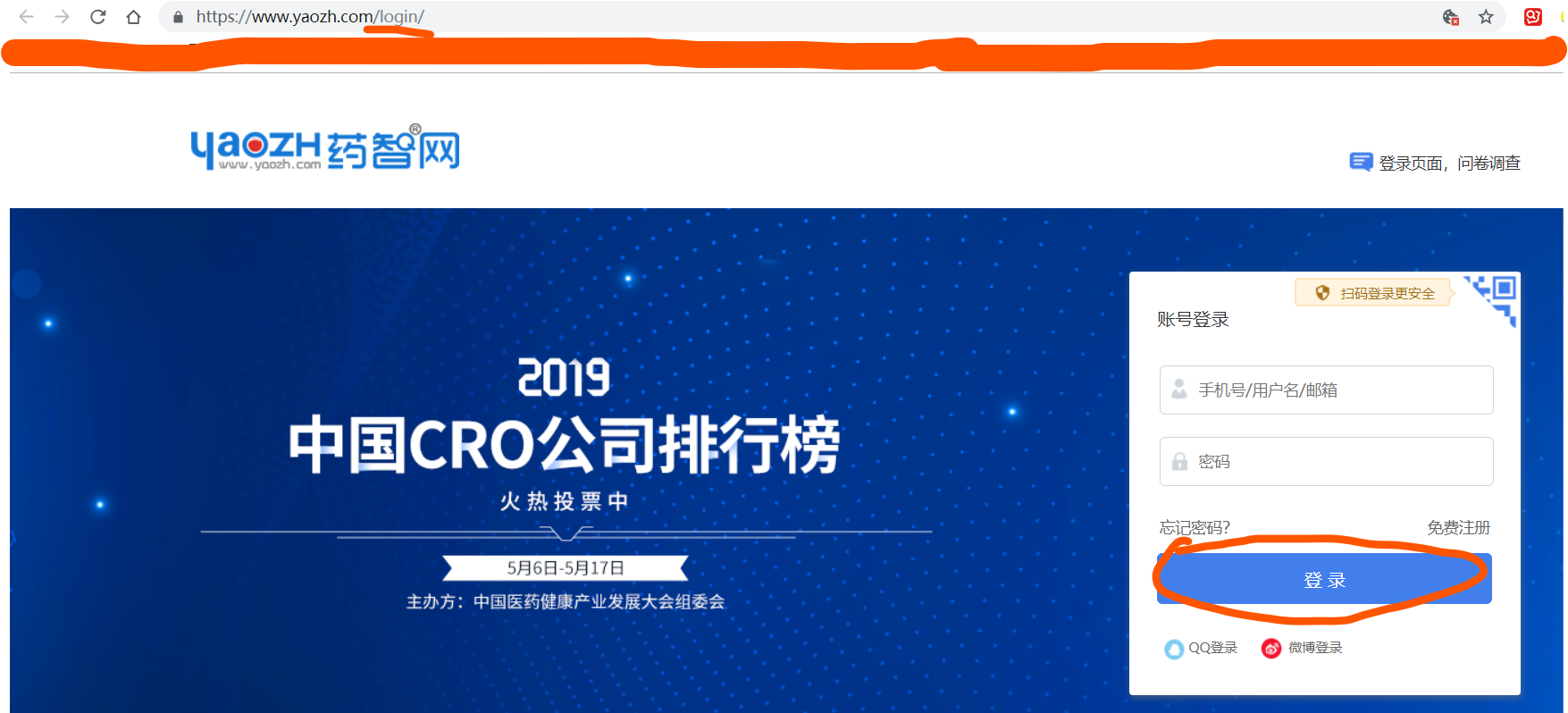
所以,在f12的network中,点击preserve log按钮,这样浏览器就会保留之前发送过的请求日志。

点击preserve log按钮,在https://www.yaozh.com/login/操作登录,发现浏览器进行登录时,发送的是一个叫做“login”的网络请求。
点击login请求,发现:(1)login发送的是POST请求!!!;(2)Form Data:Form Data为需要发送POST请求时,要发送的参数
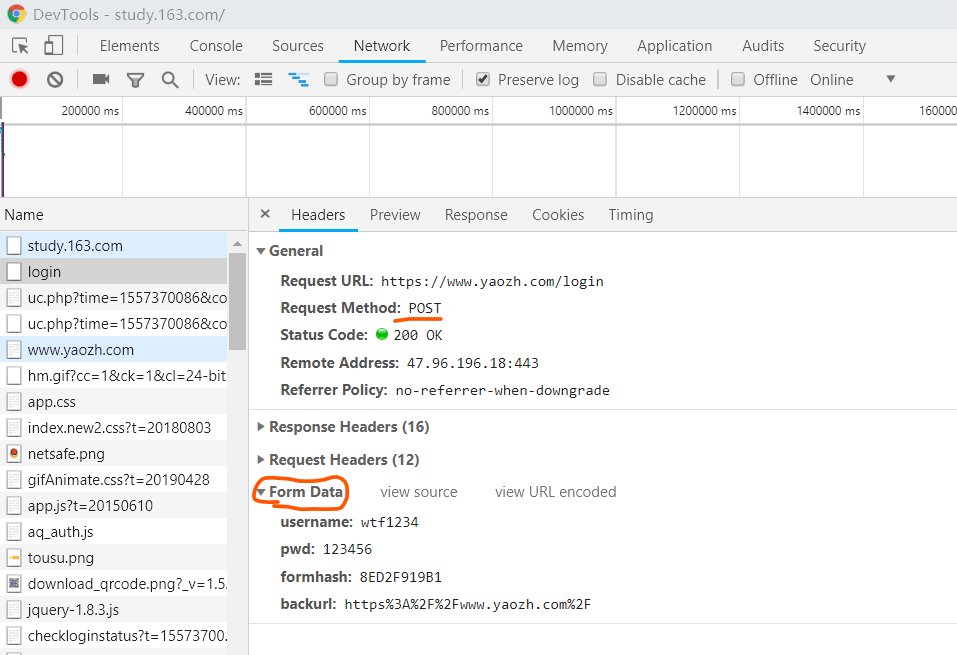
1 import urllib.request
2 import urllib.parse
3 import http.cookiejar
4 import ssl
5
6 #忽略SSL验证
7 ssl._create_default_https_context = ssl._create_unverified_context
8
9 #目标:爬取会员中心网页
10
11 #1. 会员登录,获取cookie
12 #1.1 登录网页URL
13 login_url = "https://www.yaozh.com/login/"
14
15 #1.2 请求头信息User-Agent
16 user_agent = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"}
17
18 #1.3 构造请求参数
19 #构造POST请求参数,格式必须是字典
20 #发现登录请求中,发送的是POST请求,POST请求有请求参数
21 #POST请求中需要用到的参数:位于浏览器请求头的Form Data中,将其中的数据全部复制下来
22 """
23 username: wtf1234
24 pwd: 123456
25 formhash: 3210139E64
26 backurl: https%3A%2F%2Fwww.yaozh.com%2F
27 """
28 login_request_data = {"username": "wtf1234",
29 "pwd": "123456",
30 "formhash": "3210139E64",
31 "backurl": "https%3A%2F%2Fwww.yaozh.com%2F"}
32
33
34 #1.4 转换POST请求参数格式
35 #POST请求中,上传的请求参数必须是2进制格式
36 login_request_data_bytes = urllib.parse.urlencode(login_request_data).encode("utf-8")
37
38 #1.5 向request对象中,添加URL地址、User-Agent、POST请求参数
39 #get请求中,参数拼接到URL地址中;POST请求中,Request对象里面专门有个data参数,用于接收POST请求参数
40 login_request = urllib.request.Request(login_url, headers=user_agent, data=login_request_data_bytes)
41
42 #1.6 构造CookieJar对象——用于保存管理cookie
43 my_cookiejar = http.cookiejar.CookieJar()
44
45 #1.7 构造自定义的可以添加cookie的处理器handler
46 #handler处理器的参数是构造的cookiejar对象
47 #因为urlopen()中不能添加cookie,所以我们需要找一个能添加cookie的处理器,然后再创建opener,再发送网络请求
48 cookie_handler = urllib.request.HTTPCookieProcessor(my_cookiejar)
49
50 #1.8 使用处理器handler对象,构造自定义opener对象
51 opener = urllib.request.build_opener(cookie_handler)
52
53 #1.9 使用opener对象,发送网络请求
54 #此时的login_request,既包含请求头信息,又包含请求参数
55 #此时,如果请求发送成功,则cookiejar对象会自动将cookie信息保存到opener对象中
56 opener.open(login_request) #由于我们这里只是为了登录成功,获取cookie,所以不需要response对象接收返回数据
57
58
59 #2. 使用cookie,访问会员中心网页
60 #2.1 会员中心URL
61 member_url = "https://www.yaozh.com/member/"
62
63 #2.2 构造请求头,添加User-Agent信息
64 user_agent2 = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"}
65 member_request = urllib.request.Request(member_url, headers=user_agent2)
66
67 #2.3 拿着刚才获得的cookie,发送网络请求
68 #由于opener对象中已经保存有cookie信息,所以直接用opener对象发送网络请求即可
69 response = opener.open(member_request)
70
71 #3. 读取数据
72 data = response.read().decode("utf-8")
73
74 #4. 持久化
75 with open("yaozhi_day03.html", 'w', encoding='utf-8') as f:
76 f.write(data)
爬取结果: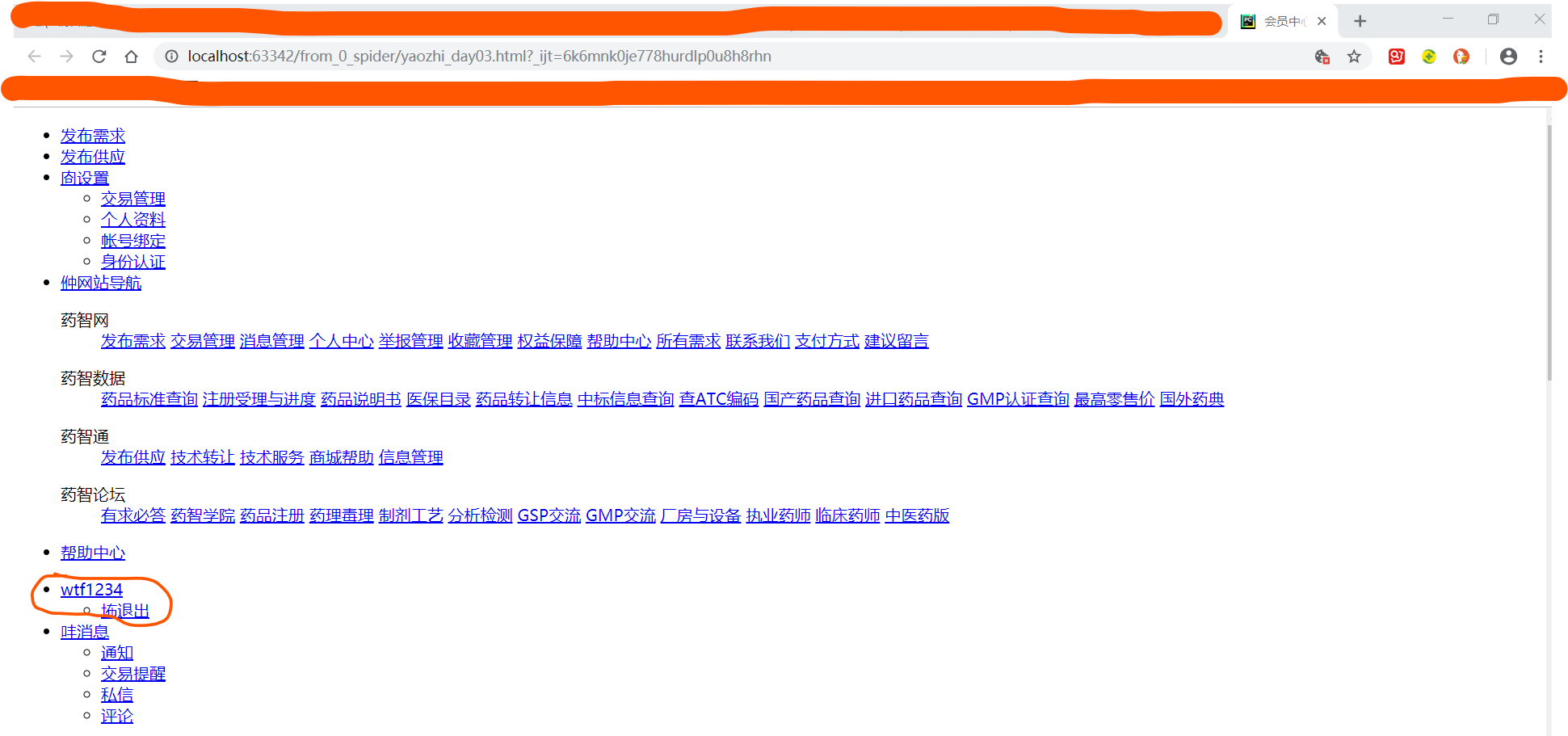
注:目前为止学过的反爬机制:
(1)User-Agent:模拟真实用户
同一个浏览器,短时间内频繁访问,反爬
(2)IP地址:
同一个IP地址,短时间内频繁访问,反爬
(3)账号:
同一个账号,短时间内在不同地点(使用不同IP地址)访问,反爬
三、初学requests模块:
理论:
(1)requests模块为第三方模块
(2)使用方法:import requests 注意末尾多一个s
(3)优点:
- 简单易用
- URL会自动转译
- python2、python3的方法名字一样
- 有官方中文文档
1 import requests
2
3 #爬取百度首页"https://www.baidu.com/"
4
5 #1. 目标网页URL
6 url = "https://www.baidu.com/"
7
8 #2. 发送get请求
9 response = requests.get(url)
10 #返回的response为状态码
11
12 #3.解析数据
13 #3.1 方式1:使用content属性解析,返回的是2进制数据
14 data = response.content.decode('utf-8')
15
16 #3.2 方式2:使用text属性解析,返回的是字符串格式数据
17 str_data = response.text
18 #但是不建议,使用此种方式解析数据,因为text内部,将2进制数据转换为字符串格式,靠猜。