一、loadloadsdumpdumps:
1.0 json介绍:
(1)json是一种数据格式,外部是以大括号{}或者中括号[]包裹的文件类型
eg:[{"xxx": "1", "yyy": "2"}, {"xxx": "3", "yyy": "4"}, {"xxx": "5", "yyy": "6"}]
(2)json中,大括号{}和中括号[],每一个应该“有且只有一个”
像:{{}}、[[]],就不是json了
(3)在python中,json里面的数据只能用双引号包含
1.1 将字符串str格式json数据,转换成dict、list格式:
str——>dict、list
data_dict1 = json.loads(data_str1)
1.2 将dict、list格式数据,转换成字符串str格式json:
data_str2 = json.dumps(data_list2)
1.3 将dict、list格式数据写入文件:
(1)先将dict、list格式数据转成字符串格式,再写入文件:
list3 = [xxx, yyy, zzz]
str3 = json.dumps(list3)
with open("01.json", "w") as f:
f.write(str3)
(2)一步直接写入文件:
list2 = [xxx, yyy, zzz]
file = open("new.json", "w")
json.dump(list2, fp=file)
file.close()
将上面代码缩短成一行:
json.dump(list2, open("new.json", "w"))
1.4 将xxx.json文件直接读取,然后用list、dict接收:
data_list = json.load(open("xxx.json", "r"))
1.5 总结:loadsloaddumpsdump
其中,带"s"的和字符串有关系。
不带"s"的和文件写入读取,有关系。
1.6 一个重要应用:将爬取下来的数据,以csv格式保存
(1)步骤:
- 读取json文件、创建CSV文件
- 提出表头、表内容
- 使用CSV写入器,写入CSV文件
- 关闭CSV文件和json文件
(2)代码:
1 import json
2 import csv
3
4 #需求:将json中的数据,用CSV文件保存
5 #json数据格式:
6 #[{"name": "张三", "age": "11"},
7 # {"name": "李四", "age": "22"},
8 # {"name": "王五", "age": "33"}]
9
10
11 #1. 读取json文件,创建CSV文件
12 json_fp = open("new.json", "r")
13 csv_fp = open("new_csv.csv", "w")
14
15 #2. 提取CSV文件的表头和表内容:
16 #2.1表头:即json数据中key,这里是"name", "age"
17 #将json文件中的数据提取出来,用list格式接收
18 data_list = json.load(json_fp)
19 #提取表头——json数据中的key
20 sheet_title = data_list[0].keys()
21 #2.2提取表的内容——即json数据中的value
22 sheet_data = []
23 for data in data_list:
24 sheet_data.append(data.values())
25
26 #3.创建CSV写入器,写入CSV文件
27 #3.1创建CSV写入器writer,向csv_fp文件写入
28 writer = csv.writer(csv_fp)
29 #3.2写入表头和表的内容
30 #写入表头
31 writer.writerows(sheet_title)
32 #写入表的内容
33 writer.writerows(sheet_data)
34
35 #4.关闭表csv文件和json文件
36 csv_fp.close()
37 json_fp.close()
二、爬取网站http://www.allitebooks.org/

分析网页发现有:
每个书籍的标题
每个书籍的图片
每个书籍的作者
每个书籍的简介
多个网页的标签
目标:爬取1-10页的数据,每一页爬取每个书籍的标题、图片、作者、简介,然后用CSV存储
代码:
import requests
from lxml import etree
from bs4 import BeautifulSoup
import csv
import json
#目标:爬取网站http://www.allitebooks.org/的所有页,爬取每个书籍的标题、图片、作者、简介,然后使用csv格式存储
#设定一个爬取类
#以后每爬一个网站,都单独设置一个类
class AllitebooksSpider(object):
def __init__(self):
#基本url
self.base_url = "http://www.allitebooks.org/page/"
#请求头信息
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"}
#创建全局变量data_list,用于存放每页数据
self.data_list =[]
#创建全局变量book_data_list,用于存放所有书的全部信息
self.book_data_list = []
#1.拼接完整的URL
#要爬取多页数据,需要搞一个方法,先将所有要爬取的URL放到列表中
#然后再将每页url逐一提取出来,逐一爬取
def get_url(self):
#设置一个list,存放url
url_list = []
#存放1-10页URL
for i in range(1, 821):
complete_url = self.base_url + str(i)
url_list.append(complete_url)
return url_list
#2.发送请求
def send_request(self, url):
data = requests.get(url=url, headers=self.headers).content.decode("utf-8")
return data
#3.解析数据
def parse_data(self, data):
#3.1转类型数据
xpath_data = etree.HTML(data)
#3.2将每一页的数据,从data_list提取出来
books_list = xpath_data.xpath('//div[@id="content"]//article')
#print(books_list)
for book_data in books_list:
#3.3二次解析,解析每一条书籍数据
#(1)书的名字,返回的是列表
book_name = book_data.xpath('.//h2[@class="entry-title"]/a/text()')
#print(book_name)
#(2)书的图片
book_image = book_data.xpath('.//div[@class="entry-thumbnail hover-thumb"]/a/img/@src')
#print(book_image)
#(3)书的作者
book_author = book_data.xpath('.//h5[@class="entry-author"]/a/text()')
#print(book_author)
#(4)书的简介
book_summary = book_data.xpath('.//div[@class="entry-summary"]/p/text()')
print(book_summary)
#(5)把每个书籍的信息放到一个字典里
book_data_dict = {}
book_data_dict["name"] = book_name
book_data_dict["image"] = book_image
book_data_dict["author"] = book_author
book_data_dict["summary"] = book_summary
#(6)把书籍信息都放到list中
self.book_data_list.append(book_data_dict)
#4.保存数据
def save_data(self):
#4.1创建CSV文件
csv_fp = open("allitebooks_csv.csv", "w", encoding="utf-8")
#4.2 提取表头、表内容
csv_title_list = self.book_data_list[1].keys()
csv_data_list = []
for book in self.book_data_list:
csv_data_list.append(book.values())
#4.3 创建CSV写入器,写入文件
writer = csv.writer(csv_fp)
writer.writerow(csv_title_list)
writer.writerows(csv_data_list)
#4.4 关闭json、CSV文件
csv_fp.close()
#5.统筹调用
def start(self):
#得到要爬取所有网页的URL列表
url_list = self.get_url()
#提取出每页URL,逐一爬取每一页数据
for url in url_list:
data = self.send_request(url=url)
self.data_list.append(data)
#将爬得的数据,逐页解析
#书名name、封面图片image、作者author、简介summary
for page_data in self.data_list:
self.parse_data(data=page_data)
#将爬得的所有数据全部存储到CSV文件
self.save_data()
#开始爬取
AllitebooksSpider().start()
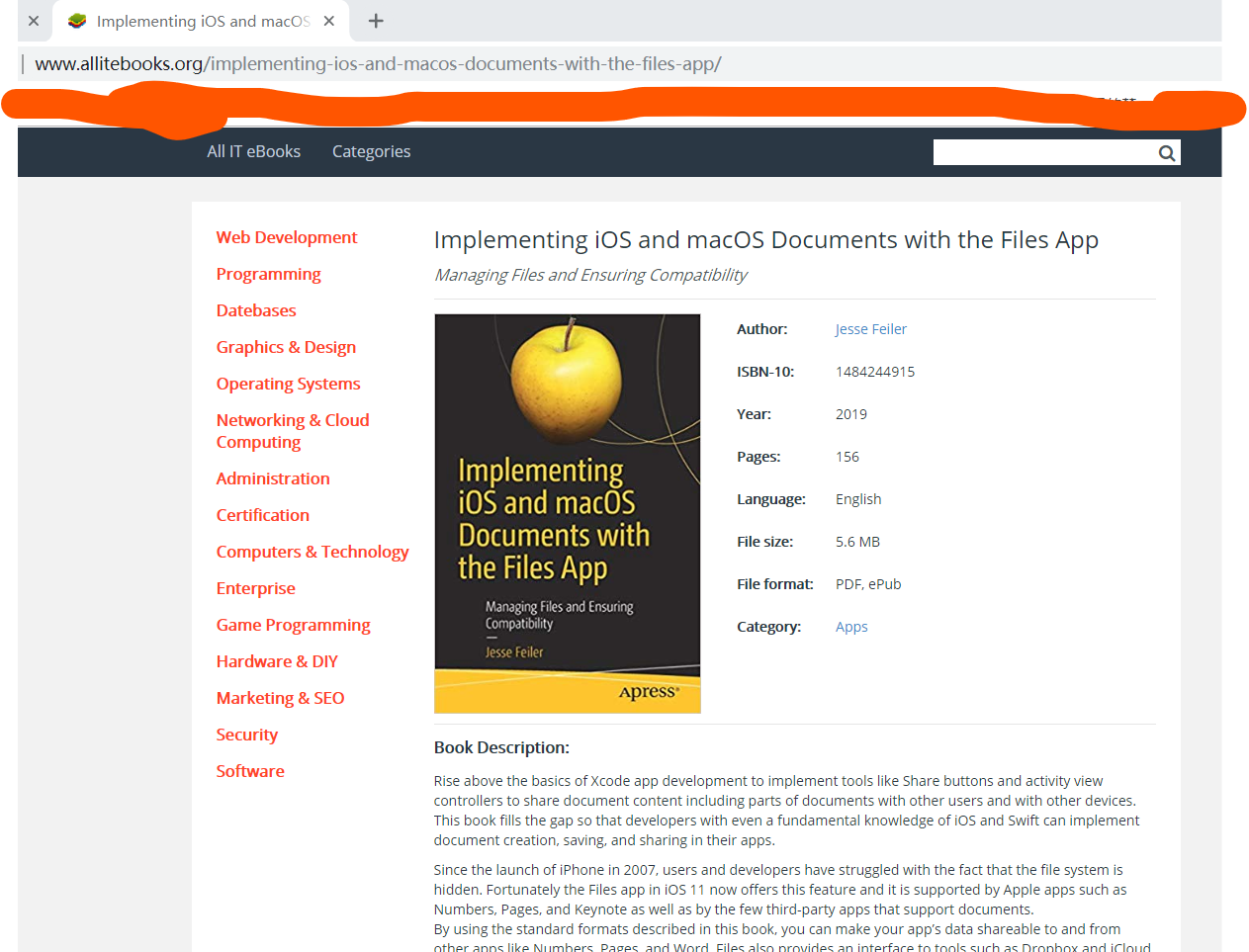
三、爬取网站http://www.allitebooks.org/每个书籍的详情页:
(1)目标页面的样子:
(2)爬虫代码:
import requests
from lxml import etree
import csv
import json
#爬取网站http://www.allitebooks.org/,爬取详情页信息
#爬取类
class DetailSpider(object):
def __init__(self):
#基础URL地址
self.base_url = "http://www.allitebooks.org/page/"
#请求头headers
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"}
#存放所有列表页的response数据
self.list_response = []
#存放所有书籍的详情页url
self.detail_url_list = []
#存放所有的书籍详情页信息
self.book_details = []
pass
#1.构建完整的URL
def get_complete_url(self):
#只爬取列表页第一页
url_list = []
for i in range(1, 2):
complete_url = self.base_url + str(i)
url_list.append(complete_url)
return url_list
#2.发送网络请求
def send_request(self, url):
response = requests.get(url=url, headers=self.headers).content.decode("utf-8")
return response
#3.1 解析列表页数据
def list_parse_data(self,data):
#1.转换数据类型
xpath_data = etree.HTML(data)
#2.所有书籍div
books_div = xpath_data.xpath('.//div[@id="content"]')[0]
#3.所有书籍信息
books_url = books_div.xpath('.//h2[@class="entry-title"]/a/@href')
for url in books_url:
self.detail_url_list.append(url)
#3.2 解析详情页数据
def detail_parse_data(self,data):
#1.转换数据类型
xpath_data = etree.HTML(data)
#2.解析页面
book_div = xpath_data.xpath('.//div[@class="site-content clearfix"]')[0]
#print(book_div)
book_title = book_div.xpath('.//h1[@class="single-title"]/text()')
book_sub_title = book_div.xpath('.//div/article/header/h4/text()')
book_image = book_div.xpath('.//div[@class="entry-body-thumbnail hover-thumb"]/a/img/@src')
book_author = book_div.xpath('.//div[@class="book-detail"]/dl/dd[1]/a/text()')
book_ISBN_10 = book_div.xpath('.//div[@class="book-detail"]/dl/dd[2]/text()')
book_year = book_div.xpath('.//div[@class="book-detail"]/dl/dd[3]/text()')
book_pages = book_div.xpath('.//div[@class="book-detail"]/dl/dd[4]/text()')
book_language = book_div.xpath('.//div[@class="book-detail"]/dl/dd[5]/text()')
book_file_size = book_div.xpath('.//div[@class="book-detail"]/dl/dd[6]/text()')
book_file_format = book_div.xpath('.//div[@class="book-detail"]/dl/dd[7]/text()')
book_category = book_div.xpath('.//div[@class="book-detail"]/dl/dd[8]/a/text()')
book_descriptions = book_div.xpath('.//div[@class="entry-content"]')[0].xpath('string(.)').strip()
book_dict = {}
book_dict['title'] = book_title
book_dict['sub_title'] = book_sub_title
book_dict['image'] = book_image
book_dict['ISBN-10'] = book_ISBN_10
book_dict['year'] = book_year
book_dict['pages'] = book_pages
book_dict['language'] = book_language
book_dict['file-size'] = book_file_size
book_dict['file-format'] = book_file_format
book_dict['category'] = book_category
book_dict['descriptions'] = book_descriptions
self.book_details.append(book_dict)
#4.保存数据
def save_data(self):
#1.创建CSV文件
csv_fp = open("allitebook_csv02.csv", "w", encoding="utf-8")
#2.提取出表头、表内容
sheet_title = self.book_details[1].keys()
sheet_data = []
for data in self.book_details:
sheet_data.append(data.values())
#3.创建CSV写入器
writer = csv.writer(csv_fp)
#4.写入表头、表内容
writer.writerow(sheet_title)
writer.writerows(sheet_data)
#5.关闭文件
csv_fp.close()
pass
#爬取列表页
def listspider(self):
# 1.1构建列表页完整URL
list_complete_url = self.get_complete_url()
# 1.2发送请求,得到全部列表页的response数据
# 逐页发送请求
for url in list_complete_url:
response = self.send_request(url=url)
self.list_response.append(response)
# 1.3解析数据,提取得到每个书籍详情页的URL
for page_data in self.list_response:
self.list_parse_data(data=page_data)
#爬取详情页
def detailspider(self, url_list):
# 2. 爬取详情页
for url in url_list:
# 2.1发送网络请求
response = self.send_request(url=url)
# 2.2解析数据
self.detail_parse_data(data=response)
# 2.3保存数据
self.save_data()
pass
#5.统筹运行
def run(self):
#爬取列表页,返回详情页的url列表
self.listspider()
print(self.detail_url_list)
#爬取详情页
self.detailspider(url_list=self.detail_url_list)
pass
DetailSpider().run()
(3)学到的知识点:
3.1 xpath取出指定的多个标签下的内容:String(.)方法
我们一般认为text的方法能够取出一个标签下的所有文本,其实不然,即使那个文本在其标签下(次级标签)想要定位范围稍微放宽,text的方法就不再适用,也就是说,我想要取出一个一级标签下的所有内容,如果有二级标签,三级标签,那么想要一下子把所有内容都取出来,只能靠string(.)的方法了
eg:
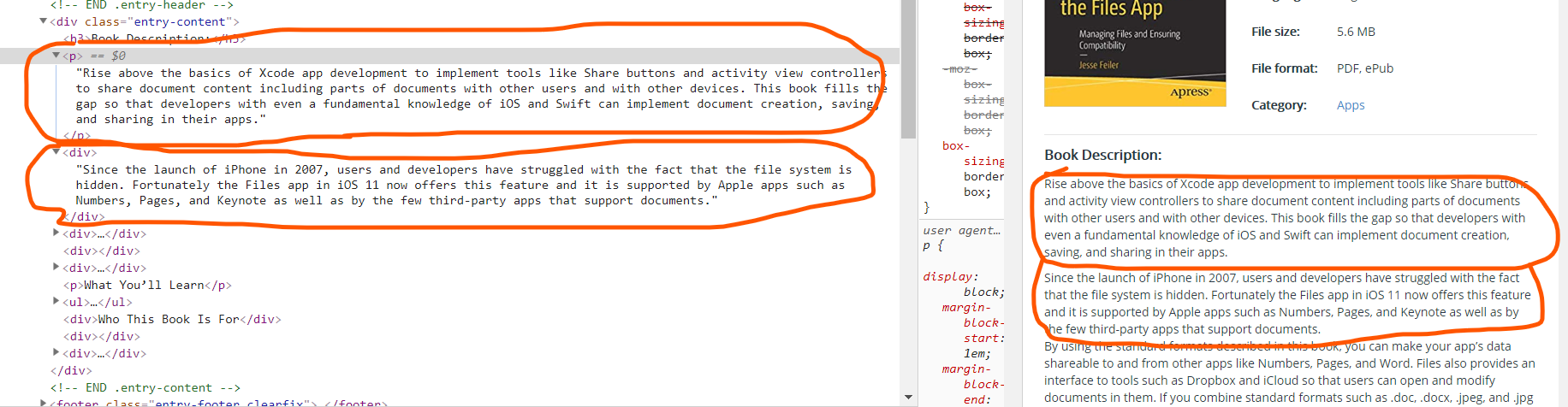
检查发现:book description下面的文字,有的是用p标签包裹,有的是用div标签包裹。
使用xpath()只取p标签或者只取div标签的内容,都无法得到完整信息。
发现所有详情页页面的共同情况是:book description是一整块div标签包裹
可以将整个book desciption作为一整块,然后将该div下面的所有文字全部取出来,就是book description的内容
book_descriptions = book_div.xpath('.//div[@class="entry-content"]')[0].xpath('string(.)').strip()
.xpath('.//div[@class="entry-content"]')得到整个div模块,但是返回的是list类型,所以取[0]第一个元素(该list也只有一个元素);
.xpath('String(.)')获取到节点下面的所有text内容,即:book description中的所有文字;
.strip()去除掉每个段落之间的空格
参考:https://blog.csdn.net/mrlevo520/article/details/53158050