危害
- 从样本量悬殊的角度
- 考虑 loss_function 通常都是正负例 loss 的求和,那么一旦一方样本数居多,loss就偏向于一方的loss,说明就在学习负例。造成最终结果不正确。
- 从易分类的角度
- 一定有些样本是特别易分类的,一旦这些样本量多起来,就对 loss 贡献不容小觑了。造成最终模型学习不好。
solution
- 解决样本不均
- 采样
- 降采样
- 直接负例10%采样
- 如果担心降采样浪费负例,可以迭代式采样。
- 第一轮用所有的整理,和采样的负例。
- 第二轮用第一轮的模型去预测所有的负例。把其中分错的拿来训练第二轮。
- 直至所有负例都被训练过。
- 过采样
- 因为要全部利用正例,很容易过拟合
- 降采样
- 生成
- 有专门的算法,基本上就是在附近生成一个扰动,当做正例。
- 采样
- 解决 loss function
- weighted loss
- 根据正负样本分布的比例,加权loss。
- focol loss,在上面的基础上,增加区分难易度的加权。抑制易区分的样本 loss。
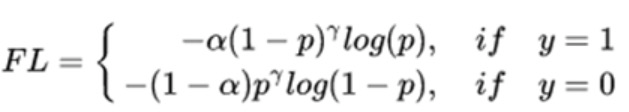
- weighted loss
- GHM loss,在focal loss 的基础上,抑制难区分样本的loss(把他们当做 outlier)
- 解决 prediction
- 例如原先 sigmoid prediction 0.5 是预测值,那么改成 0.3,无形中增大了正例的比例。(但一般我们用 auc evaluation,这就不重要了)