什么是xpath
1】xpath使用路径表达式在xml和html中进行导航 2】xpath包含标准库 3】xpath是一个w3c的标准
在本文将会利用scrapy的select实现。故而将会安装以下的依赖包
pip install twisted
pip install lxml
pip install scrapy
注意在安装lxml的时候会出现依赖的处理得问题。可以安装vscode来进行处理
xpath的节点关系
父亲节点
子节点
同胞节点
先辈节点
后代节点
xpath语法【xpath的插件安装方式,我的博客前面也有】


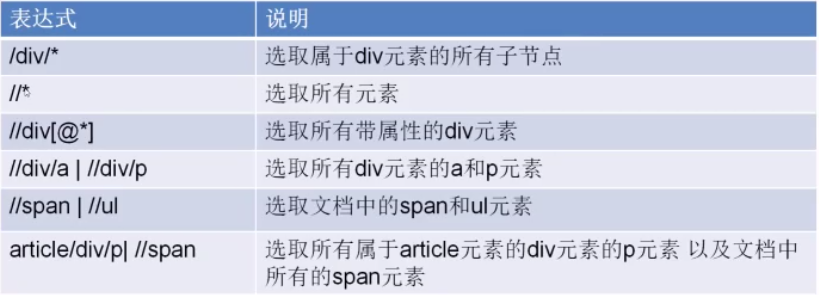
代码实现与解析:
html = """ <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>bobby基本信息</title> <script src="//code.jquery.com/jquery-1.11.3.min.js"></script> </head> <body> <div id="info"> <p style="color: blue">讲师信息</p> <div class="teacher_info info"> python全栈工程师,7年工作经验,喜欢钻研python技术,对爬虫、 web开发以及机器学习有浓厚的兴趣,关注前沿技术以及发展趋势。 <p class="age">年龄: 29</p> <p class="name bobbyname" data-bind="bobby bobby2">姓名: bobby</p> <p class="work_years">工作年限: 7年</p> <p class="position">职位: python开发工程师</p> </div> <p style="color: aquamarine">课程信息</p> <table class="courses"> <tr> <th>课程名</th> <th>讲师</th> <th>地址</th> </tr> <tr> <td>django打造在线教育</td> <td>bobby</td> <td><a href="https://coding.imooc.com/class/78.html">访问</a></td> </tr> <tr> <td>python高级编程</td> <td>bobby</td> <td><a href="https://coding.imooc.com/class/200.html">访问</a></td> </tr> <tr> <td>scrapy分布式爬虫</td> <td>bobby</td> <td><a href="https://coding.imooc.com/class/92.html">访问</a></td> </tr> <tr> <td>django rest framework打造生鲜电商</td> <td>bobby</td> <td><a href="https://coding.imooc.com/class/131.html">访问</a></td> </tr> <tr> <td>tornado从入门到精通</td> <td>bobby</td> <td><a href="https://coding.imooc.com/class/290.html">访问</a></td> </tr> </table> </div> </body> </html> """ from scrapy import Selector sel = Selector(text=html) #注意标签的顺序是重1开始的,不是0 name_xpath = "//div[1]/div[1]/p[2]/text()" #获取用户名字 name = "" #extract,是将数据提取出来同时转化为字符串 tag_texts = sel.xpath(name_xpath).extract() if tag_texts: name = tag_texts[0] print(name) #教师信息 teacher_tag = sel.xpath("//div[@class='teacher_info info']/p") #使用contains函数可以实现仅仅匹配一个类型 teacher_tag1 = sel.xpath("//div[contains(@class, 'teacher_info')]/p")