Redis缓存能够有效地加速应用的读写速度,就DB来说,Redis成绩已经很惊人了,且不说memcachedb和Tokyo Cabinet之流,就说原版的memcached,速度似乎也只能达到这个级别。今天主要讲讲在使用Redis时经常遇到的几个问题。缓存雪崩、缓存击穿、缓存穿透、缓存预热、缓存更新、缓存降级。
v缓存雪崩
缓存雪崩,是指在某一个时间段,缓存集中过期失效。所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。
缓存雪崩示意图:
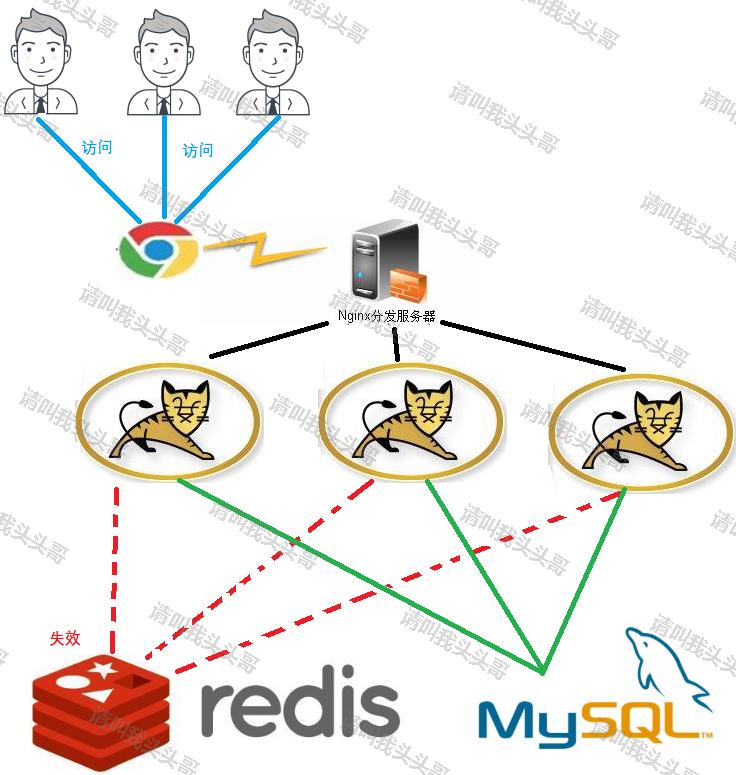
缓存失效时的雪崩效应对底层系统的冲击非常致命,那么应对Redis缓存雪崩有哪些方案呢?
1.1 加锁或者队列
可以考虑用加锁或者队列的方式防止大量线程对数据库的一次性进行读写,避免缓存失效时对数据库造成的巨大冲击。
以上效果还可以考虑接入Redis锁实现,具体可以参考《SpringBoot进阶教程(二十七)整合Redis之分布式锁》 加锁或者队列都是一个非常浅显的办法。虽然能够在一定的程度上缓解了数据库的压力,但同时也极大的降低了系统的吞吐量。
1.2 协调Redis过期时间
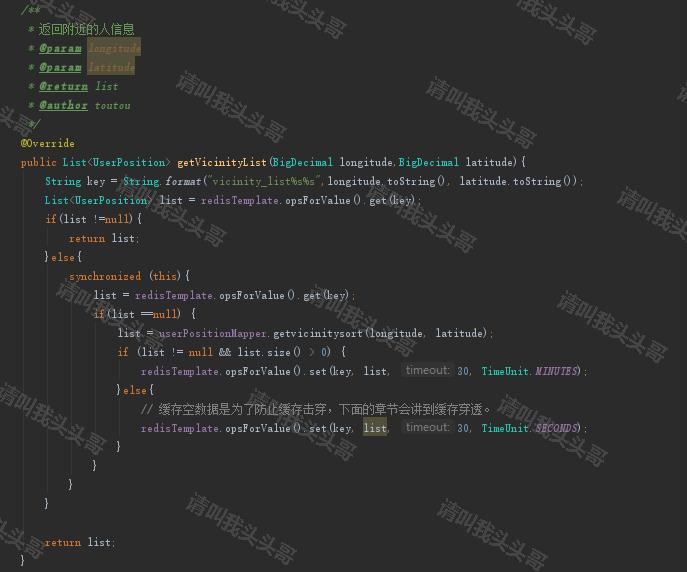
分析用户行为,尽量让缓存失效的时间均匀分布,最次也得随机分布,尤其是一些访问大的接口
@Override public UserDetails getUserInfoById(Integer uid){ String key = String.format("user_info_id:%d",uid); UserDetails userDetails = (UserDetails)templateRedis.opsForValue().get(key); if(userDetails != null){ return userDetails; }else{ userDetails = userDetailsMapper.getUserDetailsByUid(uid); Random random = new Random(); int time = 600; // type: 1: 大V用户 2: 网红 3: 普通用户 if(userDetails != null){ if(userDetails.getType() == 1){ time = 3600 + random.nextInt(3600); // 如果有其他逻辑 }else if(userDetails.getType() == 2){ time = 1200 + random.nextInt(1200); // 如果有其他逻辑 }else{ // 如果有其他逻辑 } redisTemplate.opsForValue().set(key, userDetails, time, TimeUnit.SECONDS); } } return userDetails; }
这里主要还是结合业务场景让缓存失效的时间均匀分布,比如上面这段代码中,大V用户和网红用户一般粉丝都是上百万,所以可以缓存长点的时间也是可以的。
1.3 二级缓存
做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期。
1.4 保证缓存层服务高可用性
保证缓存层服务高可用性。如果缓存层设计成高可用的,即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务。
关于这一块,可以看看前面写到的《SpringBoot进阶教程(三十)整合Redis之Sentinel哨兵模式》和《详解Redis Cluster集群》。
1.5 依赖隔离组件为后端限流并降级。
需要对重要的资源(例如Redis、MySQL、外部接口)都进行隔离,让每种资源都单独运行在自己的线程池中。即使个别资源出现了问题,对其他服务没有影响。但是线程池如何管理,比如如何关闭资源池、开启资源池、资源池阀值管理,这些做起来还是相当复杂的。
v缓存穿透
缓存穿透是指查询一个一定不存在的数据。由于缓存不命中,并且出于容错考虑,如果从数据库查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,失去了缓存的意义。
缓存穿透示意图:
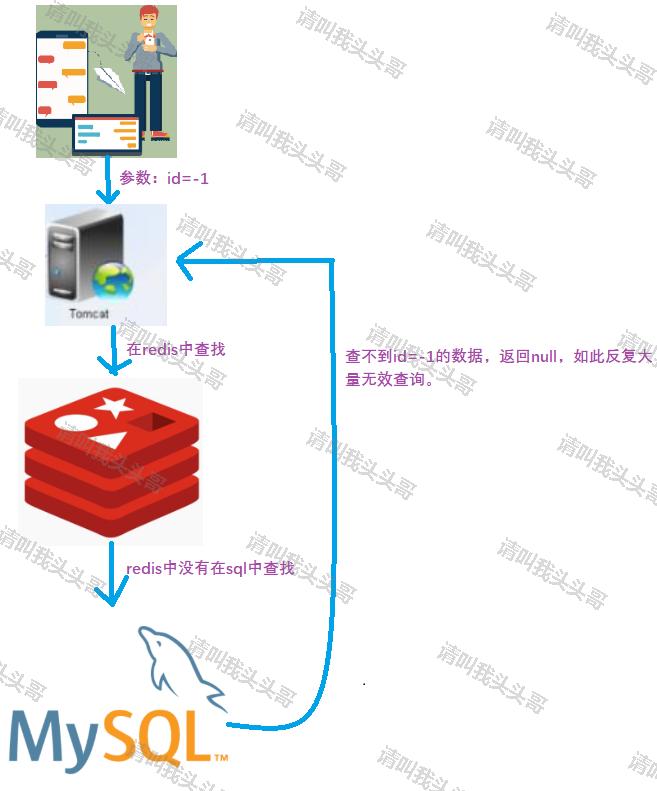
如何解决缓存穿透?对应的几个参考方案:
2.1 布隆过滤器(BloomFilter)
采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。由于请求的参数是不合法的(每次都请求不存在的参数),于是我们可以使用布隆过滤器(BloomFilter)或者压缩filter提前拦截,不合法就不让这个请求到数据库层。
BloomFilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算法和容器大小,
2.2 将空对象记录在缓存中。
如果数据库返回信息为null,也可以将这个空对象设置到缓存里边去。下次再请求的时候,就可以从缓存里边获取了,将空对象设置一个较短的过期时间。如1.1中的代码示例所示。
v缓存击穿
缓存击穿指的是热点key在某个特殊的场景时间内恰好失效了,恰好有大量并发请求过来了,造成DB压力。
其实缓存击穿和缓存雪崩从概念上来讲差不多,只是缓存击穿是某些热点key,而雪崩指的是大规模的key。
如何解决缓存击穿,对应的几个参考方案:
3.1 与1.1中类似,通过加锁或者队列的方式防止大量请求透过redis到DB中。
3.2 对于一些热点key,过期时间可以无限调长
将热点key过期时间无限调长,然后通过job服务来管理这些热点key不会过期,保证热点key(尤其是像排行榜、首页热度等需要大量计算的热点key)的稳定性。需要注意的是,job服务本身也存在不稳定性,比如部署job的服务挂了之类的。这里可以看看之前的一篇文章。《详解Supervisor进程守护监控》
v缓存降级
缓存降级是指当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。
降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
参加过去年天猫双11的朋友应该很清楚的能感受到降级,当时被吐槽的最狠的降级应该就是加入购物车,在结算的时候无法更改收货地址。只能使用默认收货地址,这得成就多少"前男友前女友"啊。
在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓死保护,哪些可降级;比如可以参考日志级别设置预案:
ps:强于"马爸爸",在双11的海量并发面前,也得降级,无可厚非。只是大家在做降级的时候,一定得考虑好取舍。这反而是降级最大的难度。
v缓存预热
上初中第一次做化学实验的时候,大家就知道试管加热前需要先预热。缓存预热也是一个比较常见的概念,缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题。用户直接查询事先被预热的缓存数据。
缓存预热思路:
对于一些计算量非常大的接口,缓存预热肯定是得有的。
v缓存更新
除了缓存服务器自带的缓存失效策略之外(Redis默认的有6中策略可供选择),我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
上面的这几个方案各有优劣,第一种的缺点是维护大量缓存的key是比较麻烦的;第二种人工成本太高;第三种的缺点就是每次用户请求过来都要判断缓存失效,逻辑相对比较复杂。具体使用场景还得结合业务来区分对待。
v博客总结
Redis的出现确实很大程度上解决了sql的压力,善用Redis的各种机制已经成为一个必不可少的技能之一。
v源码地址
https://github.com/toutouge/javademo/tree/master/hellospringboot
作 者:请叫我头头哥
出 处:http://www.cnblogs.com/toutou/
关于作者:专注于基础平台的项目开发。如有问题或建议,请多多赐教!
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
特此声明:所有评论和私信都会在第一时间回复。也欢迎园子的大大们指正错误,共同进步。或者直接私信我
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是作者坚持原创和持续写作的最大动力!